|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Глава 21Графические возможности GDI+ Это вторая из двух глав в книге, описывающая элементы взаимодействия непосредственно с пользователем, т.е. вывод информации на экран и прием пользовательского ввода с помощью мыши или клавиатуры. В главе 9 мы рассматривали формы Windows и узнали, как выводить диалоговое окно или окна SDI и MDI и как разместить в них различные элементы управления, такие как кнопки, текстовые поля и поля списков. Основное внимание было уделено использованию элементов управления на основе их способности взять на себя полную ответственность за собственное изображение на устройстве вывода. Необходимо только задать свойства элемента управления и добавить методы обработки событий. Стандартные элементы управления — очень мощные, можно получить сложный интерфейс пользователя, используя только их. На самом деле они сами по себе вполне достаточны для полного интерфейса при работе со многими приложениями, в частности диалогового типа или с интерфейсом пользователя типа проводника. Однако существуют ситуации, в которых простые элементы управления не дают гибкости, требуемой в интерфейсе пользователя. Иногда необходимо ввести текст заданным шрифтом в точной позиции окна или нарисовать изображения, не используя элемент управления "графическая кнопка", простые контуры или другую графику. Хорошим примером является программа Word for Windows. В верхней части экрана находятся различные кнопки и панели инструментов, которые используются для доступа к различным свойствам Word. Некоторые из меню и кнопок вызывают диалоговые окна или даже списки свойств. Эта часть интерфейса пользователя была рассмотрена в главе 9. Но основная часть экрана в Word for Windows будет совершенно другой. Окно SDI выводит представление документа. Оно имеет текст, аккуратно расположенный в нужных местах и выведенный с использованием множества размеров и шрифтов. В документе может быть выведена любая диаграмма и, если посмотреть на документ компоновки для печати, поля реальных страниц также должны быть выведены. Ничего из этого нельзя сделать с помощью элементов управление, описанных в главе 9. Чтобы изобразить такой вывод, программа Word for Windows должна взять на себя прямую ответственность за сообщение операционной системе, что необходимо вывести и где в его окне SDI. Как это делается, объясняется в данной главе. Здесь будет показано, как рисовать различные элементы, включая: □ Линии, простые контуры □ Изображения из растровых и других файлов изображении □ Текст Во всех случаях элементы могут быть нарисованы где угодно в области экрана, занимаемой приложением, и код непосредственно управляет рисованием, например, когда и как обновить элементы, каким шрифтом изобразить текст и так далее. В этом процессе необходимо использовать множество вспомогательных объектов, включая перья (используемые для определения характеристик линий), кисти (для определения того, как заполняются области, каким цветом — сплошные, в виде решетки или заполнены в соответствии с некоторым другим шаблоном) и шрифты (определяющие форму символов текста). Также будет рассказано, как устройства интерпретируют и выводят различные цвета. Код, требуемый для реального рисования на экране, часто достаточно прост и базируются на технологии, называемой GDI+. GDI+ состоит из множества базовых классов .NET, доступных для выполнения произвольного рисования на экране. Эти классы могут отправить необходимые инструкции драйверам графических устройств для обеспечения правильного вывода в требуемых местах экрана монитора (или для печати твердой копии). Также как и остальные базовые классы .NET, классы GDI+ основываются на вполне доступной для понимания и использования объектной модели. Объектная модель GDI+ концептуально достаточно проста, но все же требуется хорошее понимание описанных ниже принципов того, как Windows организует изображение элементов на экране, чтобы эффективно и рационально использовать GDI+. Эта глава делится на два основных раздела. Первые две трети главы посвящены концепциям, лежащим в основе GDI+, исследуется, как происходит рисование с упором на теорию. Здесь будет представлено довольно много примеров, почти все из которых являются небольшими приложениями, выводящими специфические жестко закодированные элементы (в основном простые фигуры, такие как прямоугольники и эллипсы). В последней трети главы мы сконцентрируемся на разработке развернутого примера, называемого CapsEditor, который выводит содержимое текстового файла и позволяет пользователям делать некоторые изменения в выводимых данных. Назначение этого примера состоит в демонстрации принципов рисования, применяемых на практике в реальном приложении. Для реального рисования обычно необходим небольшой код — классы GDI+ работают на достаточно высоком уровне, поэтому в большинстве случаев требуется только несколько строк кода для рисования одиночного элемента (например, изображения или фрагмента текста). Но хорошо спроектированное приложение, использующее GDI+, будет выполнять за сценой большую дополнительную работу, т.е. обеспечивать эффективность рисования, и, если потребуется, обновление экрана без каких-либо лишних изображений. (Это важно, так как основная часть работы по рисованию требует от приложения высокой производительности.) Пример CapsEditorпоказывает, как делать большую часть этого фонового управления. Библиотека базовых классов GDI+ очень велика, и мы едва сможем прикоснуться к их свойствам в данной главе. Это обдуманное решение, так как попытка охватить хотя бы минимальную часть доступных классов, методов и свойств превратит эту главу в справочное руководство, которое просто перечисляет классы и т. д. Более важно понять фундаментальные принципы, вовлеченные в рисование, а затем можно будет исследовать доступные классы самостоятельно. (Полные списки всех доступных в GDI+ классов и методов имеются в документации MSDN). Разработчики, имеющие дело с VB, найдут, скорее всего, концепции, вовлеченные в рисование, совершенно незнакомыми, так как фокус VB заключается в элементах управления, обрабатывающих свое собственное рисование. Разработчики с подготовкой C++/MFC окажутся в более выгодном положении, так как MFC требует в большей степени внешнего управления процессом рисования, используя предпроцессор GDI+, GDI. Однако даже при хорошем знакомстве с GDI подавляющая часть материала окажется новой. GDI+ в действительности является оболочкой GDI, но тем не менее GDI+ имеет объектную модель, которая скрывает большую часть работы GDI. В частности GDI+ заменяет почти полностью модель с состоянием GDI, в которой элементы выбирались в контексте устройства, на модель, менее учитывающую состояние, в которой каждая операция рисования происходит независимо. Объект Graphics (представляющий контекст устройства) является единственным объектом, существующим между операциями рисования.
Прежде коротко перечислим основные пространства имен, которые встречаются в базовых классах GDI+.
Почти все классы, структуры и т.д., использующиеся в этой главе, взяты из пространства имен System.Drawing. Основные принципы рисованияВ этом разделе исследуются основные принципы, которые необходимо знать, чтобы начать рисовать на экране. Мы начнем с обзора GDI — описанной ниже технологии, на которой основывается GDI+, и посмотрим, как она связана с GDI+. Затем будет рассмотрено несколько простых примеров. GDI и GDI+Одним из достоинств Windows и современных операционных систем в целом является возможность абстрагировать детали работы определенных устройств от разработчика. Например, нет необходимости знать что-либо о драйвере устройства жесткого диска, чтобы программным путем прочитать или записать файлы на диск, достаточно просто вызвать соответствующие методы в подходящих классах .NET (или до появления .NET в эквивалентных функциях Windows API). Этот принцип также вполне справедлив, когда речь идет о рисовании. Когда компьютер рисует что-нибудь на экране, он делает это, посылая инструкции видеоплате с указанием, что рисовать и где. Проблема в том, что на рынке существует много сотен различных видеокарт, сделанных различными производителями. Если принять это в расчет и писать в приложении специальный код для каждого видеодрайвера, который рисует что-то на экране, создание приложения станет практически невозможной задачей. Именно поэтому интерфейс графического устройства (GDI) операционной системы Windows всегда присутствовал в системе с самых первых версий Windows. GDI скрывает нюансы работы различных видеоплат, так что для выполнения определенной задачи вызывается просто функция API Windows, и внутренне GDI вычисляет, как заставить определенную видеоплату сделать то, что требуется. Однако большинство компьютеров имеют более одного устройства, на которое можно послать вывод. Сегодня это монитор, доступ к которому получают через видеоплату, и принтер. Некоторые машины могут иметь более одной видеоплаты или более одного принтера. GDI проявляет удивительное искусство, заставляя принтер выглядеть так же, как экран, с позиции приложения. Если необходимо напечатать что-то, а не вывести это на экран, то система просто информируется, что устройством вывода является принтер, а затем вызываются те же функции API. Таким образом, истинное предназначение GDI — абстрагировать свойства оборудования на относительно высоком уровне API. GDI предоставляет для разработчиков относительно высокий уровень API, но это по-прежнему API, который основывается на старом API Windows с функциями в стиле С, и поэтому его не так просто использовать. GDI+ в большой степени позиционируется как слой между GDI и приложением, предоставляя более интуитивно-понятную объектную модель на основе наследования. Хотя GDI+ является по сути оболочкой вокруг GDI, компания Microsoft смогла с помощью GDI+ предоставить новые свойства и при этом повысить производительность.  Контексты устройств и объект GraphicsВ GDI устройство, на которое должен направиться вывод, идентифицируется с помощью объекта, известного как контекст устройства (DC — Device Context). Контекст устройства хранит информацию об определенном устройстве и может транслировать вызовы функций API GDI в инструкции, которые необходимо послать на это устройство. Можно также запрашивать контекст устройства, чтобы определить возможности соответствующего устройства (например, может ли принтер печатать в цвете или осуществляет только черно-белую печать), чтобы настроить соответственно вывод. Если запросить устройство сделать что-то, на что оно не способно, контекст устройства обычно это обнаруживает и совершает соответствующее действие (которое, в зависимости от ситуации, может означать порождение ошибки или изменение запроса, чтобы получить ближайшее соответствие тому, на что действительно способно устройство). Однако контекст устройства имеет дело не только с аппаратным устройством. Оно действует как мост к Windows и способен поэтому учесть любые требования или ограничения, налагаемые на рисование операционной системой Windows. Например, если Windows знает, что необходимо перерисовать только часть окна приложения (возможно, потому что было минимизировано другое окно, которое скрывает часть приложения), контекст устройства может перехватывать и аннулировать попытки рисовать вне этой области. Благодаря связи контекста устройства с Windows работа через контекст устройства может упростить код и другими способами. Например, аппаратным устройствам необходимо сообщать, где рисовать объекты, и обычно координаты задаются относительно верхнего левого угла экрана (или устройства вывода). Но приложение будет считать рисование чем-то происходящим в определенной позиции внутри клиентской области своего собственного окна. (Клиентская область в Windows является частью окна, которая обычно используется для рисования, что означает окно с исключенными границами, таким образом во многих приложениях клиентская область будет областью с белым фоном.) Поскольку окно может быть расположено где угодно на экране и пользователь вправе перемещать его в любое время, трансляция между двумя координатами является потенциально трудной задачей. Но контекст устройства всегда знает, где находится окно, и способен выполнить эту трансляцию автоматически. Это означает, что можно запросить контекст устройства нарисовать элемент в определенной позиции окна, не беспокоясь о том, где на экране в настоящее время расположено окно приложения. Как можно видеть, контекст устройства является очень мощным объектом, и нет ничего удивительного в том, что в GDI все рисование выполняется через него. Контекст устройства используется даже иногда для операций, которые не включают рисование на экране или на любом аппаратном устройстве. Например, если имеется битовое изображение, в котором делаются некоторые изменения (возможно, изменение его размера), то более эффективно делать это с помощью контекста устройства, так как он может использовать некоторые аппаратные свойства машины, чтобы выполнять такие операции быстрее. Изменение изображений находится вне рамок этой главы, но заметим, что контексты устройств очень эффективно подготавливают изображения в памяти, прежде чем конечный результат посылается на экран. При использовании GDI+ контекст устройства по-прежнему существует, хотя ему теперь дано другое имя. Он завернут в базовый класс .NET с именем Graphics. При чтении этой главы можно будет заметить, что большая часть рисования делается с помощью вызовов методов на экземпляре Graphics. Фактически, так как класс System.Drawing.Graphicsотвечает за реальную обработку большинства операций рисования, очень немногое делается в GDI+, что не включает экземпляр Graphics. Умение управлять этим объектом, является ключом к пониманию того, как рисовать на устройствах вывода с помощью GDI+. Пример: рисование контуровМы собираемся начать с короткого примера для рисования в основном окне приложения. Все примеры в этой главе созданы с помощью Visual Studio.NET как приложения Windows на C#. Вспомните, что для проекта такого типа мастер кода определяет класс с именем Form1, производный от System.Windows.Form, который представляет основное окно приложения. Если не утверждается обратное, то во всех примерах новый или измененный код означает код, добавленный к этому классу.
В первом примере создается просто форма и на ней рисуется в методе InitializeComponent(). Необходимо сказать вначале, что это не лучший способ рисования на экране, мы быстро обнаружим, что возникает проблем в связи с невозможностью перерисовать что-нибудь после запуска. Однако пример проиллюстрирует достаточно много деталей рисования, не требуя при этом большой работы. В данном случае мы запускаем Visual Studio.NET, создаем приложение Windows и изменяем код в методе InitializeComponent()следующим образом: private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(300, 300); this.Text = "Display At Startup"; this.BackColor = Color.White; и добавляем следующий код в конструктор Form1: public Form1() { InitializeComponent(); Graphics dc = this.CreateGraphics(); this.Show(); Pen BluePen = new Pen(Color.Blue, 3); dc.DrawRectangle(BluePen, 0, 0, 50, 50); Pen RedPen = new Pen(Color.Red, 2); dc.DrawEllipse(RedPen, 0, 50, 80, 60); } Это единственные изменения, которые необходимо сделать. Наш пример является примером DisplayAtStartupиз загружаемого кода. Фоновый цвет формы задается как белый, поэтому она выглядит "подходящим" окном, в котором мы собираемся вывести графическое изображение. Соответствующая строка кода помещается в метод InitializeComponent(), чтобы Visual Studio .NET распознал строку и мог изменить внешний вид формы. Иначе можно было бы использовать графическое представление для задания цвета фона, что привело бы к появлению той же самой инструкции в InitializeComponent(). Вспомните, что этот метод используется системой Visual Studio.NET для создания представления формы. Если не задать явно цвет фона, то он останется с заданным по умолчанию для диалоговых окон цветом, объявленным в настройках Windows. Затем мы создаем объект Graphicsс помощью метода CreateGraphics(). Этот объект Graphicsсодержит контекст устройства Windows, который нужен для рисования. Созданный контекст устройства ассоциируется с устройством вывода, а также с этим окном. Отметим, что здесь используется переменная с именем dc для экземпляра объекта Graphics, отражая тот факт, что он в действительности представляет контекст устройства, действующий за сценой. Далее для выведения окна вызывается метод Show(). Это делается просто для немедленного вывода окна, так как на самом деле нельзя выполнить рисования, пока окно не будет изображено — не на чем будет рисовать. Наконец, мы выводим прямоугольник в точке с координатами (0, 0) с шириной и высотой равной 50 и эллипс в точке с координатами (0, 50) с шириной 80 и высотой 50. Отметим, что координаты (х, у) означают х пикселей вправо и у пикселей вниз от верхнего левого угла клиентской области окна и являются координатами верхнего левого угла изображаемой фигуры: 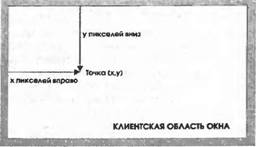 Запись (х, у) является стандартной математической записью, очень удобной для описания координат. Используемые методы DrawRectanglе()и DrawEllipse()имеют по 5 параметров. Первый параметр каждого метода — это экземпляр класса System.Drawing.Pen. Pen является одним из ряда поддерживаемых объектов, помогающих при рисовании,— объект содержит информацию о том, как должны быть нарисованы линии. Наше первое перо определяет, что линии должны быть голубыми с шириной 3 пикселя, второе говорит что линии красные и имеют ширину 2 пикселя. Последние четыре параметра являются координатами. Для прямоугольника они представляют координаты (х, у) верхнего левого угла, а также его ширину и высоту, задаваемые числом пикселей. Для эллипса эти числа представляют те же самые вещи, за исключением того, что речь идет о гипотетическом прямоугольнике, в который вписывается эллипс, а не о самом эллипсе.
Выполнение данного кода приведет к следующему результату: 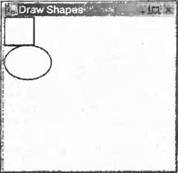 Экран иллюстрирует два момента. Первое: можно ясно видеть, что понимается под клиентской областью окна. Это белая область, которая была задействована в результате задания свойства BackColor. Отметим, что прямоугольник расположился в углу этой области, как и можно было ожидать при задании координат (0, 0). Второе, отметим, что верхняя часть эллипса слегка перекрывает прямоугольник,— это было трудно предвидеть из заданных в коде координат. Так, Windows размещаем линии, ограничивающие прямоугольник и эллипс. По умолчанию Windows будет пытаться поместить линию на границе фигуры что не всегда можно сделать точно, так как линия должна проходить через пиксели (очевидно), но граница каждой фигуры теоретически лежит между двумя пикселями. В результате линии толщиной в один пиксель будут проходить точно внутри верхней и левой сторон фигуры, но вне нижней и правой сторон, значит, фигуры, которые, строго говоря, находятся рядом друг с другом, будут иметь границы, перекрывающиеся на один пиксель. Мы определили более широкие линии, поэтому перекрытие будет больше. Можно изменить поведение по умолчанию, задавая свойство Pen.Alignment, как отмечено в документации MSDN, но для наших целей достаточно поведения по умолчанию. На рисунке показано также, что код сработал правильно. Кажется, что рисование невозможно выполнить проще. К сожалению, если действительно выполнить этот пример, можно будет заметить, что форма ведет себя немного странно. Все нормально, если просто оставить ее на месте или перемещать по экрану с помощью мыши. Попробуйте минимизировать форму а затем восстановить ее. Окажется, что нарисованные формы просто исчезнут. То же самое произойдет, если протащить другое окно через окно этого примера. Еще интереснее будет, если закрыть форму другим окном, так что оно закроет только часть фигур, а затем убрать его снова. Окажется, что временно скрытая часть исчезла и осталась только часть эллипса и часть прямоугольника. Что же делать? Проблема возникает, если окно или его часть становятся скрытыми по какой-либо причине (например, оно минимизируется или закрывается другим окном), Windows обычно немедленно отбрасывает всю информацию, относящуюся к тому, что там было изображено. Система должна это делать, иначе используемая память для хранения данных экрана будет слишком большой. Типичный компьютер может работать с видеоплатой, настроенной для вывода 1024×768 пикселей, возможно, в режиме с 24-битовым цветом. Мы покажем, что означает 24-битовый цвет позже, но в данный момент можно сказать, что каждый пиксель на экране занимает 3 байта, т. е. 2.25 Мбайт для изображения экрана. Однако нет ничего необычного, если пользователь имеет во время работы более 10 минимизированных окон в своей панели задач, в худшем сценарии 20, каждое из которых занимает весь экран, если оно не минимизировано. Если бы Windows действительно хранил визуальную информацию, которую содержат эти окна, готовую на случай, если пользователь захочет их восстановить, то речь шла бы о 45 Мбайт. Сегодня хорошая графическая карта может иметь 64 Мбайта памяти, но еще пару лет назад 4 Мбайта считалось большим объемом для графической платы, а избыточные данные необходимо было хранить в основной памяти компьютера. Множество людей все еще используют старые машины. Очевидно, что для Windows было бы непрактично управлять интерфейсом своих пользователей подобным образом. В тот момент, когда какая-либо часть окна становится скрытой, эти пиксели пропадают. Windows замечает, что окно (или некоторая его часть) скрыто, и когда система обнаруживает, что эта область больше не является скрытой, она запрашивает приложение, которое владеет окном, чтобы оно перерисовало его содержимое. Существуют исключения из этого правила, обычно для случаев, когда небольшая часть окна скрыта очень недолго (хорошим примером является выбор элемента из основного меню, когда этот элемент меню раскрывается внизу, временно закрывая часть окна ниже). Однако можно ожидать, что, если часть окна становится скрытой, то приложению придется перерисовать его позже. Это проблема для нашего примера приложения. Мы поместили код рисования в конструктор Form1, который вызывается только один раз при запуске приложения, и невозможно вызывать конструктор снова, чтобы перерисовать фигуры, когда это потребуется позже. В главе 9 при рассмотрении элементов управления нам ничего этого не нужно было знать, так как стандартные элементы управления достаточно развиты и могут правильно перерисовать себя, когда Windows об этом попросит. Это одна из причин, почему при программировании элементов управления вообще не нужно беспокоиться о реальном процессе рисования. Если мы берем на себя ответственность в приложении за рисование на экране, то нам нужно также гарантировать, что приложение будет отвечать правильно, когда Windows попросит перерисовать все или часть окна. В следующем разделе мы изменим пример так, чтобы это было возможно. Рисование фигур с помощью OnPaintЕсли приведенное выше объяснение заставило вас подумать, что рисование своего собственного пользовательского интерфейса будет очень сложной задачей, то не стоит волноваться. Это не так. Были приведены различные детали процесса, для того чтобы вы поняли, с какими проблемами столкнетесь. Но заставить приложение перерисовать себя, когда необходимо, — в действительности легкая задача. Когда возникает необходимость, Windows уведомляет приложение, что требуется выполнить некоторую перерисовку изображения, инициируя событие Paint. Интересно то, что класс Formуже реализовал обработчик для этого события, поэтому не нужно создавать свой собственный. Можно воспользоваться этой архитектурой, исходя из факта, что обработчик Form1для события Paintбудет вызывать в процессе обработки виртуальный метод OnPaint(), передавая в него единственный параметр PaintEventArgs. Это означает, что для выполнения рисования необходимо просто переопределить метод OnPaint(). Мы создадим для этого новый пример, называемый DrawShapes. Как и раньше, определяем DrawShapesкак приложение Windows, генерируемое с помощью Visual Studio.NET, и добавим следующий код класса Form1: protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; Pen BluePen = new Pen(Color.Blue, 3); dc.DrawRectangle(BluePen, 0, 0, 50, 50); Pen RedPen = new Pen(Color.Red, 2); dc.DrawEllipse(RedPen, 0, 50, 80, 60); base.OnPaint(e); } Отметим, что метод OnPaint()объявлен как protected. OnPaint()обычно используется внутри класса, поэтому нет необходимости любому другому коду вне класса знать о его существовании. PaintEventArgsявляется производным классом от EventArgs, используемого обычно для передачи информации о событиях. PaintEventArgsимеет два дополнительных свойства, из которых наиболее важным является экземпляр Graphics, уже настроенный и оптимизированный для рисования требуемой части окна. Это означает, что нам не нужно вызывать CreateGraphics(), чтобы получить контекст устройства в методе OnPaint(), — он уже существует. Мы вскоре рассмотрим другое дополнительное свойство, оно содержит более подробную информацию о том, какая область окна действительно нуждается в перерисовке. В данной реализации метода OnPaint()мы сначала получаем ссылку на объект Graphicsиз PaintEventArgs, затем рисуем фигуры так же, как это делалось раньше. В конце вызывается метод OnPaint()базового класса. Этот шаг является важным. Мы переопределили OnPaint()для выполнения нашего собственного рисования, но возможно, что Windows должен выполнить свою собственную работу в процессе рисования, и такая работа будет связана с методом OnPaint()в одном из базовых классов .NET. Для этого примера может оказаться, что удаление вызова base.OnPaint()не оказывает никакого влияния на работу, но никогда не пытайтесь удалить вызов. Это может привести к некорректному завершению работы Windows и непредсказуемым результатам. OnPaint()будет также вызываться, когда приложение впервые запускается и окно приложения выводится в первый раз, поэтому нет необходимости дублировать код рисования в конструкторе, хотя по-прежнему нужно задать здесь цвет фона и все другие свойства формы. Это обычно задается либо добавлением команды явно, либо заданием цвета в окне свойств Visual Studio.NET: private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(300, 300); this.Text = "Draw Shapes"; this.BackColor = Color.White; } Выполнение этого кода вначале дает те же результаты, что и в предыдущем примере, за исключением того, что теперь приложение ведет себя правильно, когда окно минимизируется или скрывается его часть. Использование области вырезанияПример приложения DrawShapesиз предыдущего раздела иллюстрирует основные принципы, используемые при рисовании в окне, однако оно не очень эффективно. Причина в том, что оно пытается рисовать в окне все, независимо от того, сколько должно быть перерисовано. Рассмотрим ситуацию, показанную на следующем рисунке. После выполнения приложения DrawShapesбыло открыто другое окно, которое закрыло часть формы DrawShapes. 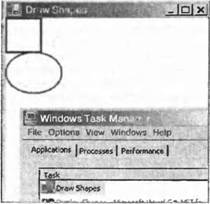 До сих пор все хорошо. А что произойдет, когда перекрывающее окно (в данном случае Task Manager) будет удалено, так что окно DrawShapesбудет снова полностью видно? Windows, как обычно, пошлет форме событие Paint, чтобы она себя перерисовала. Прямоугольник и эллипс находится в верхнем левом углу клиентской области и поэтому видны все время, так что в действительности нет ничего, что требуется сделать в данном случае, помимо перерисовки белой фоновой области. Однако Windows этого не знает. В той степени, в какой это касается Windows, необходимо перерисовать часть окна. Это означает, что надо инициировать событие Paint, которое вызывается в нашей реализации OnPaint(). OnPaint()будет затем пытаться излишне перерисовать прямоугольник и эллипс. В таком случае фигуры не нужно перерисовывать. Причина этого связана с контекстом устройства. Ранее говорилось, что контекст устройства внутри объекта Graphics, передаваемого в метод OnPaint(), будет оптимизирован операционной системой Windows для выполнения конкретной ближайшей задачи. Это означает, что Windows предварительно инициализирует контекст устройства информацией о том, какая область в действительности должна быть перерисована. Это прямоугольник, который был покрыт окном Task Manager на снимке экрана, приведенном выше. Во время использования GDI, область помеченная для перерисовки, называлась недействительной областью, но с появлением GDI+ терминология существенно изменилась, и эта область стала называться областью вырезания. Контекст устройства знает, какая это область, и поэтому прервет любые попытки рисования вне этой области и не будет передавать соответствующие команды рисования графической плате. Это звучит хорошо, но все равно здесь существует потенциальная потеря производительности. Мы не знаем какой объем обработки потребуется выполнить контексту устройства, чтобы определить, что рисование произойдет вне недействительной области. В некоторых случаях это может оказаться существенной величиной, так как определение того, какие пиксели необходимо изменить и в какой цвет может оказаться очень трудоемким (хотя хорошая графическая плата обеспечит аппаратное ускорение). Прямоугольник является достаточно легкой фигурой. Эллипс — труднее, поскольку необходимо вычислять положение кривой. Вывод текста потребует еще больших усилий, так как необходимо обрабатывать информацию в шрифте, чтобы определить форму каждой буквы, а каждая буква состоит из ряда линий и кривых, которые должны быть нарисованы по отдельности. Если, как в большинстве распространенных шрифтов, это будет шрифт с переменной шириной, т. е., когда у каждой буквы нет фиксированного размера и она занимает столько места, сколько ей требуется, то невозможно даже определить, сколько пространства займет текст, не выполнив предварительных громоздких вычислений Вследствие этого запрос экземпляра Graphicsвыполнит некоторое рисование вне недействительной области, что почти наверняка будет бесполезным использованием процессорного времени и замедлит работу приложения. В хорошо спроектированном приложении код активно помогает контексту устройства, выполняя несколько простых проверок, чтобы убедиться, что обычная работа по рисованию действительно нужна, прежде чем вызывать подходящие методы экземпляра Graphics. В этом разделе мы создадим новый пример DrawShapesWithClipping, изменяя для этого пример DisplayShapes. В коде OnPaint()будет сделана простая проверка достоверности, что недействительная область пересекла область рисования, и только в этом случае вызовутся методы рисования. Сначала необходимо получить данные области вырезания. Для этого используется дополнительное свойство PaintEventArgs. Свойство, называемое ClipRectangle, содержит координаты предназначенной для перерисовывания области, помещенные в экземпляр структуры System.Drawing.Rectangle. Rectangleявляется достаточно простой структурой, она содержит 4 представляющих интерес свойства: Top, Bottom, Leftи Right. Они соответственно содержат вертикальные координаты верха и низа прямоугольника и горизонтальные координаты левого и правого краев. Затем надо решить, какой тест будет использоваться для рисования. Здесь будет использован простой тест. Отметим, что прямоугольник и эллипс полностью содержатся внутри прямоугольника, который простирается в клиентской области от точки (0, 0) до точки (80, 130), в действительности до точки (82, 132), так как мы знаем, что линии могут отклоняться примерно на пиксель вне этой области. Поэтому будем проверять, что верхний левый угол области вырезания находится внутри этого прямоугольника. Если это так, то выполняется рисование. Если нет, то ничего не делается. Код выглядит следующим образом: protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; if (e.ClipRectangle.Tор < 132 && e.ClipRectangle.Left < 82) { Pen BluePen = new Pen(Color. Blue, 3); dc.DrawRectangle(BluePen, 0, 0, 50, 50); Pen RedPen = new Pen(Color.Red, 2); dc.DrawEllipse(RedPen, 0, 50, 80, 60); } base.OnPaint(e); } Заметим, что изображение получится точно таким же, как и раньше, но производительность повысится благодаря раннему выявлению некоторых случаев, когда ничего не должно рисоваться. Отметим также, что мы выбрали достаточно примитивный тест необходимости рисования, более точный тест мог бы проверять по отдельности, нужно ли рисовать прямоугольник или эллипс, или оба объекта. Здесь существует некоторое балансирование. Можно сделать проверку в OnPaint()более сложной, в этом случае повысится производительность, но код OnPaint()при этом усложнится и потребует больше работы для своего создания. Однако почти всегда стоит провести некоторую проверку просто потому, что это помогает понять общую картину (например, в нашем примере мы узнали дополнительно, что рисунок никогда не выходит за пределы прямоугольника (0, 0) на (82, 132)). Экземпляр Graphicsне имеет этого знания, он слепо следует командам рисования. Такое дополнительное знание означает, что имеются более полезные или эффективные проверки, чем те. что мог бы делать экземпляр объекта Graphics. Измерение координат и областейВ последнем примере мы встретили базовую структуру Rectangle, которая используется для представления координат прямоугольника. GDI+ в действительности использует несколько аналогичных структур для представления координат или областей. Мы рассмотрим основные структуры, определенные в пространстве имен System.Drawing:
Отметим, что многие эти объекты имеют ряд других свойств, методов или перезагруженных операторов, не перечисленных здесь. Рассмотрим только самые важные. Point и PointFРассмотрим сначала Point(точка) Эта структура концептуально является простейшей и математически полностью эквивалентна двумерному вектору. Она содержит два открытых целых свойства, которые представляют горизонтальное и вертикальное смещение от определенного места (возможно, на экране). Посмотрите на рисунок: 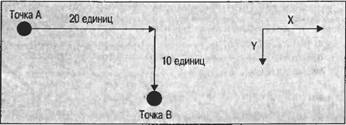 Чтобы перейти из точки А в точку В, необходимо сместиться на 20 единиц вправо и на 10 единиц вниз, помеченных как X и Y на рисунке, так как это обычное обозначение. Можно было бы создать структуру Point, которая представляет это, следующим образом: Point АВ = new Point(20, 10); Console.WriteLine("Moved {0} across, {1} down", AB.X, AB.Y); X и Y являются свойствами чтения-записи, а значит, можно также задать значения в Pointследующим образом: Point АВ = new Point(); AB.X = 20; АВ.Y = 10; Console.WriteLine("Moved (0) across, (1) down", AB.X, AB.Y); Отметим, что хотя обычно горизонтальные и вертикальные координаты обозначаются как координаты х и у (буквы нижнего регистра), соответствующие свойства Pointобозначаются Xи Y(буквами верхнего регистра), так как обычное соглашение в C# для открытых свойств требует, чтобы их имена начинались с букв верхнего регистра. PointFпо сути идентична Point, за исключением того, что Xи Yимеют тип floatвместо int. PointFиспользуется, когда координаты не обязательно являются целыми значениями. Для этих структур определено преобразование типов, поэтому можно неявно преобразовывать из Pointв PointFи явно из PointFв Point(последнее преобразование явное в связи с риском ошибок округления): PointF ABFloat = new PointF(20.5F, 10.9F); Point AB = (Point)ABFloat; PointF ABFloat2 = AB; Одно последнее замечание о координатах. В нашем обсуждении Pointи PointFсознательно присутствует неопределенность в отношении единиц измерения. Можно говорить о 20 пикселях вправо и 10 пикселях вниз или о 20 дюймах, или 20 милях. Интерпретация координат полностью принадлежит разработчику. По умолчанию GDI+ будет представлять единицы измерения как пиксели на экране (или принтере, в зависимости от графического устройства), именно таким образом методы объекта Graphicsбудут представлять любые координаты, которые передаются им в качестве параметров. Например, точка Point(20, 10)представляет 20 пикселей вправо по экрану и 10 пикселей вниз. Обычно эти пиксели измеряются от верхнего левого угла клиентской области окна, как было до сих пор в рассмотренных примерах. Но это не всегда так, в некоторых ситуациях может потребоваться нарисовать относительно верхнего левого угла всего окна (включая границу) или даже относительно верхнего левого угла экрана. В большинстве случаев, однако, если документация не говорит обратное, можно предполагать, что речь идет о пикселях относительно верхнего левого угла клиентской области. Мы вернемся к рассмотрению этого вопроса после изучения прокрутки экрана, когда речь пойдет об использовании трех различных координатных систем: мировых, страницы и устройства. Size и SizeFПодобно Pointи PointFразмеры выступают в двух вариантах. Структура Sizeпредназначена для работы с целыми значениями, SizeF— для значений с плавающей точкой. В остальном Sizeи SizeFидентичны. Мы сосредоточимся здесь на структуре Size. Во многом Sizeаналогична структуре Point. Она имеет два целых свойства, которые представляют горизонтальное и вертикальное расстояния, основное различие состоит в том, что вместо Xи Yэти свойства называются Widthи Height. Можно представить предыдущую диаграмму с помощью кода: Size АВ = new Size(20, 10); Console.WriteLine("Moved {0} across, {1} down", AB.Width, AB.Height); Строго говоря структура Sizeматематически представляет то же, что и Point, но концептуально она предназначена для использования немного другим образом. Pointприменяется, если говорится о местоположении объекта, a Size— когда речь идет о размере чего-то. В качестве примера рассмотрим нарисованный ранее прямоугольник с координатой вверху слева (0, 0) и размером (50, 50): Graphics dc. = е.Graphics; Pen BluePen = new Pen(Color.Blue, 3); dc.Rectangle(BluePen, 0, 0, 50, 50); Размер этого прямоугольника равен (50, 50) и может быть представлен экземпляром Size. Нижний правый угол также находится в точке (50, 50), но будет представляться экземпляром Point. Чтобы увидеть различия, предположим, что мы рисуем прямоугольник в другом месте, так что его верхняя левая координата будет (10, 10). dc.DrawRectangle(BluePen, 10, 10, 50, 50); Теперь нижний правый угол имеет координаты (60, 60), но размер не изменился — по-прежнему (50, 50). Дополнительный оператор был перезагружен для точек и размеров так, чтобы можно было добавлять размер к точке задавал другую точку: static void Main(string [] args) { Point TopLeft = new Point (10, 10); Size RectangleSize = new Size(50, 50); Point BottomRight = TopLeft + RectangleSize; Console.WriteLine("TopLeft = " + TopLeft); Console.WriteLine("BottomRight = " + BottomRight); Console.WriteLine("Size = " + RectangleSize); } Этот код, выполняемый как простое консольное приложение, создает следующий вывод:  Отметим, что этот вывод показывает также, как метод ToString()объектов Pointи Sizeбыл переопределен для вывода значения в формате {X, Y}. Аналогично можно вычесть Sizeиз Point, чтобы задать Point, или складывать два размера Size, задавая другой размер Size. Однако невозможно сложить точку Pointс другой точкой Point. Компания Microsoft определила, что такое действие не имеет концептуального смысла, поэтому было решено не создавать никакою перезагружаемого оператора + который бы позволял это сделать. Можно также явно преобразовать Pointв Sizeи наоборот: Point TopLeft = new Point(10, 10); Size S1 = (Size)TopLeft; Point P1 = (Point)S1; При этом преобразовании значению S1.Widthприсваивается значение TopLeft.X, а S1.Height— TopLeft.Y. Следовательно, S1содержит (10, 10). P1будет содержать те же значения, что и TopLeft. Rectangle и RectangleFЭти структуры предcтавляют прямоугольную область (обычно на экране). Так же, как и в случае с Pointи Size, мы рассмотрим только структуру Rectangle. RectangleFпо сути идентична, за исключением того, что свойства, представляющие размеры, используют float, в то время как в Rectangleиспользует int. Rectangleможно рассматривать как точку в верхнем левом углу прямоугольника и Size, которая представляет его размер. Один из его конструкторов действительно получает Pointи Sizeв качестве параметров, Можно увидеть это переписывая предыдущий код рисования прямоугольника Graphics dc = е Graphics; Pen BluePen = new Pen(Color Blue, 3); Point TopLeft = new Point(0, 0); Size HowBig = new Size(50, 50); Rectangle RectangleArea = new Rectangle(TopLeft, HowBig); dc.DrawRectangle(BluePen, RectangleArea); Этот код также использует альтернативное переопределение Graphics.DrawRectangle(), который получает Penи структуру Rectangleв качестве своих параметров. Можно также создать Rectangle, используя значения в таком порядке как отдельные числа: верхняя левая горизонтальная координата, верхняя левая вертикальная координата, отдельно ширина и высота: Rectangle RectangleArea = new Rectangle(0, 0, 50, 50) Rectangleимеет достаточно много свойств чтения-записи для задания или извлечения его размеров в различных комбинациях:
Отметим, что эти свойства не все независимы,— например задание Widthбудет влиять на значение Right. RegionМы упомянем здесь о существовании класса System.Drawing.Region, однако не будем рассматривать его подробно в этой книге. Regionпредставляет область на экране, которая имеет некоторую сложную форму. Например, затененная область на рисунке может быть представлена Region:  Процесс инициализации экземпляра Regionявляется сам по себе достаточно сложным. В целом это можно сделать, указывая, какие компоненты простой формы составляют область либо какой маршрут необходимо пройти, чтобы обойти область по границе. Если требуется работать с такими областями, то стоит изучить класс Region. Замечание об отладкеТеперь мы готовы перейти к более сложным рисункам. Но сначала необходимо поговорить об отладке. Если попробовать задать точки прерывания для примеров в этой главе, то можно заметить, что отладка графических программ не является такой же простой задачей, как отладка других частей программы. Это связано с тем, что сам факт входа и выхода из отладчика часто приводит к отправке приложению сообщений Paint. В результате может оказаться, что задание точки прерывания в методе OnPaintзаставляет приложение просто воспроизводить себя непрерывно, и поэтому оно не может делать ничего другого. Типичный сценарий будет таков: необходимо определить, почему приложение что-то выводит неправильно, поэтому в OnPaintзадается точка прерывания. Как ожидается, приложение доходит до точки прерывания и вызывает отладчик, в результате появляется окно среды разработки MDI. В этом окне можно проверить значения некоторых переменных и даже найти что-нибудь полезное. Для продолжения работы нажмите клавишу F5, чтобы можно было увидеть, что происходит, когда приложение выводит что-то еще после выполнения некоторой обработки. К сожалению, в этот момент окно приложения выходит на передний план и Windows обнаруживает, что форма снова видна и немедленно посылает событие Paint. Это означает, конечно, что точка прерывания тут же сработает снова. Но обычно требуется, чтобы точка прерывания сработала позже, когда приложение нарисует что-то интересное, возможно, после выбора некоторых пунктов меню для чтения из файла или другого способа изменения изображения. Похоже на тупик. Либо не нужно вообще создавать точку прерывания в OnPaint, либо приложение никогда не сможет выйти за точку, где выводится его начальное окно. Однако существуют способы обхода этой проблемы. Если имеется достаточно большой экран, то простейшим способом является сохранение окна среды разработчика открытым, но так, чтобы оно не закрывало окно приложения. К сожалению, в большинстве случаев это не очень практичное решение, так как окно среды разработки будет слишком маленьким. Альтернативное решение, которое использует тот же самый принцип, состоит в том, что приложение должно объявить себя самым верхним приложением во время отладки. Это делается заданием свойства TopMostкласса Form, что можно легко осуществить в методе InitializeComponent: private void InitializeComponent() { this.TopMost = true; Это означает, что приложение никогда не будет закрыто другими окнами (только другими самыми верхними окнами). Оно всегда остается поверх других окон, даже когда другое приложение получает фокус. Так ведет себя менеджер задач. Даже при использовании этой техники необходимо быть внимательным, так как никогда нет полной уверенности в том, что Windows не решит по какой-либо причине инициировать событие Paint. Если действительно в OnPaintтребуется выявить некоторую проблему, возникающую при некоторых специальных условиях (например, приложение выполняет рисование после выбора определенного пункта в меню и что-то происходит в этом месте неправильно), то лучше всего поместить пустой код в OnPaint, который проверит некоторое условие, справедливое только в определенных обстоятельствах. А затем помещаем точку прерывания внутрь блока ifследующим образом: protected override void OnPaint(PaintEventArgs e) { // Condition() оценивается как true, когда требуется прерывание if (Condition() == true) { int ii = 0; // <-- ЗАДАТЬ ЗДЕСЬ ТОЧКУ ПРЕРЫВАНИЯ } Это быстрый и простой способ создания условной точки прерывания. Изображение прокручиваемых оконНаш ранний пример DrawShapesработал хорошо, так как все, что нужно было нарисовать, поместилось в окне начального размера. В этом разделе мы обсудим, что необходимо сделать, если это не так. Расширим пример DrawShapesдля демонстрации прокрутки. Начнем с создания примера BigShapes, в котором сделаем прямоугольник и эллипс немного больше. При этом продемонстрируем, как использовать структуры Point, Sizeи Rectangle, используя их для определения областей рисования. С такими изменениями соответствующая часть класса Form1выглядит следующим образом: // поля-члены private Point reсtangleTopLeft = new Point(0, 0); private Size rectangleSize = new Size(200, 210); private Point ellipseTopLeft = new Point(50, 200); private Size ellipseSize = new Size(200, 150); private Pen bluePen = new Pen(Color.Blue, 3); private Pen redPen = new Pen(Color.Red, 2); private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(300, 300); this.Text = "Scroll Shapes"; this.BackColor = Color.White; } #endregion protected override void OnPaint(PaintEventArgs e) ( Graphics dc = e.Graphics; if (e.ClipRectaringle.Top < 350 || e.ClipRectangle.Left < 250) { Rectangle RectangleArea = new Rectangle(RectangleTopLeft, RectangleSize); Rectangle EllipseArea = new Rectangle(EllipseTopLeft, EllipseSize); dc.DrawRectangle(BluePen, RectangleArea); dc.DrawEllipse(RedPen, EllipseArea); } base.OnPaint(e); } Отметим, что мы превратили объекты Penв поля-члены — это более эффективно, чем создание нового объекта Penкаждый раз, когда нужно что-то нарисовать, как это делалось до сих пор. Результат выполнения этого примера выглядит следующим образом: 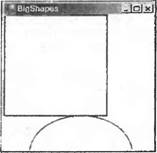 Сразу можно увидеть проблему. Фигуры не вписываются в область рисования 300×300 пикселей. Обычно, если документ является слишком большим для изображения, приложение добавляет панель прокрутки, чтобы позволить прокручивать окно и видеть выбранную часть изображения. Это еще одна область, где для интерфейса пользователя (см. главу 9) предоставляется среда времени выполнения .NET и базовым классам делать всю работу. Если форма имеет различные элементы управления, присоединенные к ней, то экземпляр класса Formзнает, где находятся эти элементы управления, и, следовательно, осведомлен, что если его окно становится слишком маленьким, то нужны панели прокрутки. Экземпляр Formбудет также автоматически добавлять панели прокрутки и не только это, он способен также правильно нарисовать любую часть экрана, на которую произойдет перемещение. В этом случае нет ничего, что требуется делать в коде явно. Однако в этой главе мы берем ответственность за рисование на экране и поэтому собираемся помочь экземпляру Form, когда потребуется использовать прокрутку.
Добавление панелей прокрутки делается очень просто. Объект Formможет по-прежнему обрабатывать все это для нас, причина, по которой так не делается в приведенном выше примере, состоит в том, что он не знает о необходимости этого, так как ему неизвестен размер области, в которой будет происходить рисование. Более точно, нам нужно знать размер прямоугольника, который простирается от верхнего левого угла документа (или, эквивалентно, верхнего левого угла клиентской области, прежде чем делается какая-либо прокрутка) и которая достаточно велика, чтобы содержать весь документ. В данной главе эта область будет называться областью документа. Взглянув на рисунок "документа", можно увидеть, что для нашего примера область документа составляет (250, 350) пикселей. 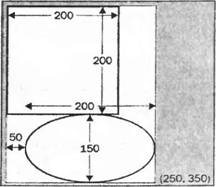 Сообщить форме размер документа достаточно просто. Мы используем соответствующее свойство Form.AutoScrollMinSize. Поэтому мы пишем следующий код: private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(300, 300); this.Text = "Scroll Shapes"; this.BackColor = Color.White; this.AutoScrollMinSize = new Size(250, 350); } Отметим, что здесь мы имеем MinScrollSizeв методе InitializeComponent. Это удачный фрагмент в данном конкретном приложении, так как мы всегда знаем, каков будет размер экрана. Наш "документ" никогда не изменяет размер, пока выполняется это конкретное приложение. Помните, однако, что если приложение делает, например, вывод содержимого файлов или что-то еще, где область экрана может изменяться, то потребуется задание этого свойства в другое время. Задания MinScrollSizeдля начала вполне достаточно. Давайте посмотрим, как теперь выглядит ScrollShapes. Мы имеем экран, который правильно выводит фигуры: 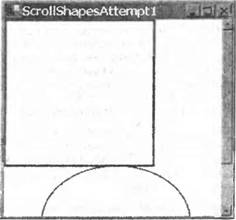 Отметим, что форма не только правильно задает панели прокрутки, но даже правильно масштабирует их, чтобы указать, какая часть документа выводится в данный момент. Если мы попробуем изменить размер окна во время выполнения примера, то окажется, что панели прокрутки реагируют правильно и даже исчезают, если сделать окно достаточно большим, так что необходимость в них отпадет. Однако посмотрим теперь, что происходит, если действительно воспользоваться одной из панелей прокрутки и сместить немного изображение вниз: 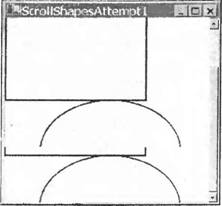 Очевидно, что-то происходит неправильно. Фактически неправильное поведение связано с тем, что не было принято во внимание положение панелей прокрутки в коде метода OnPaint(). Это легко увидеть, если заставить окно полностью перерисовать себя, минимизировав и затем восстановив его. Результат выглядит так: 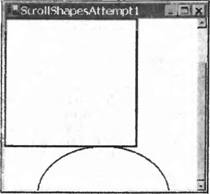 Фигуры нарисованы, как и раньше, с верхним левым углом прямоугольника, помещенным в верхний левый угол клиентской области, как если бы панель прокрутки вообще не перемещалась. Прежде чем перейти к решению этой проблемы, рассмотрим, что происходит на снимках экрана. Это поможет точно понять, как выполняется рисование в присутствии панелей прокрутки, и в то же время будет хорошей практикой. Если начать использовать GDI+, то рано или поздно встретится ситуация со странными рисунками, такая, как одна из приведенных выше, что потребует определить, что же происходит неправильно. Посмотрим сначала на последний снимок экрана, с которым проще иметь дело. Пример ScrollShapesбыл только что восстановлен, поэтому все окно перерисовано. Взглянув на код, можно видеть, что он дает указание экземпляру Graphicsнарисовать прямоугольник с верхними левыми координатами (0, 0) относительно верхнего левого угла клиентской области окна — то, что и было нарисовано. Проблема в том, что экземпляр Graphicsпо умолчанию интерпретирует координаты относительно клиентского окна, ведь он ничего не знает о панелях прокрутки. Код также не пытается настроить координаты в соответствии с позициями панелей прокрутки. То же самое происходит для эллипса. Теперь посмотрим на более ранний снимок экрана — сразу после прокрутки изображения вниз. Мы замечаем, что здесь верхние две трети окна выглядят нормально. Это связано с тем, что они были нарисованы, когда приложение запускалось в первый раз. При прокрутке окна Windows не просит приложение перерисовать то, что уже было на экране. Система Windows достаточно разумна, чтобы самостоятельно определить, какие биты из изображаемых в данный момент на экране могут плавно переместиться, чтобы соответствовать текущему положению панели прокрутки. Это значительно более эффективный процесс, так как он может использовать некоторые аппаратные средства ускорения. Часть этого изображения экрана, которая выглядит неправильно, составляет нижнюю треть окна. Эта часть окна не была нарисована, когда приложение появилось на экране впервые, так как до начала прокрутки она находилась вне клиентской области. Значит, система Windows просит приложение ScrollShapesнарисовать эту область. Она инициирует событие Paint, передавая именно эту область в качестве прямоугольника вырезания. И именно это сделал метод OnPaint(). Такое довольно странное изображение экрана возникает в приложении, которое сделало в точности то, что ему было приказано. Один из способов решения проблемы состоит в следующем. Мы в данный момент задаем координаты относительно верхнего левого угла начала "документа", а нам необходимо преобразовать их, чтобы задать относительно верхнего левого угла клиентской области. Рисунок должен это четко показать. На нем тонкие прямоугольники отмечают границы области экрана и всего документа (чтобы сделать рисунок понятнее, документ на самом деле расширен вниз и вправо за границы экрана, но это не изменяет рассуждения. Мы также предполагаем небольшую горизонтальную и вертикальную прокрутки). Толстые линии отмечают прямоугольник и эллипс, которые мы пытаемся нарисовать. Некоторая произвольно нарисованная точка Р будет служить в качестве примера. При вызове методов рисования мы предоставляем экземпляр объекта Graphicsс вектором из точки В в точку Р, этот вектор представляет экземпляр Point. На самом деле нам нужен вектор из точки А в точку Р. 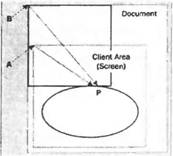 Проблема в том, что неизвестно, каким будет вектор из А в Р. Мы знаем, какой будет вектор из В в Р, это просто координаты Р относительно верхнего левого угла документа, позиция, где мы хотим нарисовать в документе точку Р. Мы знаем также, какой будет вектор из В в А — это величина, на которую была выполнена прокрутка; она хранится в свойстве класса Formс именем AutoScrollPosition. Однако мы не знаем вектор, направленный из А в Р. Чтобы найти искомый вектор, надо вычесть два вектора. Например, чтобы попасть из В в Р надо переместиться на 150 пикселей вправо и на 200 пикселей вниз, а чтобы попасть из B в А, необходимо переместиться на 10 пикселей вправо и на 57 пикселей вниз. Это означает, что для тою чтобы попасть из А в Р. необходимо переместиться на 140 (= 150 - 10) пикселей вправо и на 143 (= 200 - 57) пикселя вниз: Однако все выполняется проще. Весь процесс был расписан подробно, чтобы показать, что происходит на самом деле, но класс Graphicsна самом деле реализует метод, делающий эти вычисления. Он называется TranslateTransform. Ему передаются в качестве параметров горизонтальная и вертикальная координаты, которые указывают, где находится верхний левый угол клиентской области относительно верхнего левого угла документа (наше свойство AutoScrollPosition, которое определяет на рисунке вектор от В к А). Затем устройство Graphicsс этого момента будет рассчитывать все координаты, принимая во внимание, где находится клиентская область относительно документа. После всех этих объяснений осталось только добавить следующую строку кода в код рисования dc.TranslateTransform(this.AutoScrollPosition.X, this.AutoScrollPosition.Y); Фактически в нашем примере это происходит немного сложнее, так как мы по отдельности контролируем область вырезания, проверяя, нужно ли делать какое-либо рисование. Мы должны настроить эту проверку с учетом положения прокрутки, после чего весь код рисования для этого примера (загружаемый с web-сайта Wrox Press как ScrollShapes) выглядит таким образом: protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; Size ScrollOffset = new Size(this.AutoScrollPosition); if (e.ClipRectangle.Top + ScrollOffset.Width < 350 || e.ClipRectangle.Left + ScrollOffset.Height < 250) { Rectangle RectangleArea = new Rectangle(RectangleTopLeft + ScrollOffset, RectangleSize); Rectangle EllipseArea = new Rectangle(EllipseTopLeft + ScrollOffset, EllipseSize); dc.DrawRectangle(BluePen, RectangleArea); dc.DrawEllipse(RedPen, EllipseArea); } base.OnPaint(); } Теперь код прокрутки работает прекрасно, мы можем, наконец, получить правильно прокрученный снимок экрана. 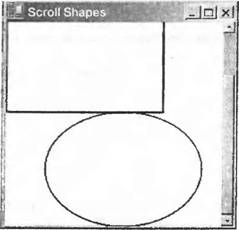 Координаты мировые, страницы и устройстваРазличие в измерениях позиции относительно верхнего левого угла документа и относительно верхнего левого угла экрана является настолько значительным, что GDI+ имеет для них специальные названия. □ Мировые координаты являются позицией точки, измеренной в пикселях от верхнего левого угла документа. Название отражает тот факт, что весь документ может рассматриваться как "мир" с точки зрения программы. □ Координаты страницы являются позицией точки, измеренной в пикселях от верхнего левого угла клиентской области. Название идет от представления выводимой области как "страницы" выводимых данных.
GDI+ определяет также и третьи координаты, которые теперь называются координатами устройства. Координаты устройства аналогичны координатам страницы, за исключением того, что в качестве единиц измерения используются не пиксели, а другие единицы, которые пользователь может определить с помощью свойства Graphics.PageUnit. Возможные единицы измерения, помимо используемых по умолчанию пикселей, включают дюймы и миллиметры. Хотя свойство PageUnitв этой главе не будет использоваться, оно может быть полезно как способ обойти проблему различной плотности пикселей на устройствах. Например, 100 пикселей на большинстве мониторов будут занимать около дюйма. Однако лазерные принтеры могут иметь до тысяч dpi (точек на дюйм), что означает, что фигура в 100 пикселей шириной будут выглядеть значительно меньше при печати на таком лазерном принтере. Задавая единицы измерения, например, дюймы, и определяя, что фигура должна быть шириной в 1 дюйм, можно гарантировать, что фигура будет одного размера на различных устройствах. ЦветаВ этом разделе мы рассмотрим способы, с помощью которых можно определить цвет для рисования. Цвета в GDI+ представлены экземплярами структуры System.Drawing.Color. Обычно после создания экземпляра такой структуры с ним почти ничего нельзя делать, только передавать в какой-либо вызываемый метод, требующий Color. Мы встречали эту структуру раньше, когда задавали фоновый цвет клиентской области окна в примерах. Свойство Form.BackColorв действительности возвращает экземпляр Color. Рассмотрим эту структуру более подробно. В частности, проверим несколько различных способов создания Color. Значения красный-зеленый-синий (RGB)Общее число цветов, которое можно изобразить на мониторе, огромно — более 16 млн. Точнее, оно равно 2 в 24-й степени, что составляет 16777216. Требуется некоторый способ индексирования этих цветов, чтобы можно было указать, какой цвет мы хотим использовать для данного пикселя. Наиболее распространенный способ индексирования цветов состоит в разделении их на компоненты красного, зеленого и синего цветов. Эта идея основывается на принципе, что любой цвет, различаемый человеческим глазом, можно создать из некоторого количества красного, зеленого и синего. Эти цвета называются компонентами. На практике оказывается, что если разделить величину каждого компонента на 256 возможных интенсивностей, то это дает достаточно тонкую градацию, чтобы можно было вывести изображения, которые воспринимаются человеческим глазом как имеющие фотографическое качество. Поэтому мы определяем цвета, задавая значения этих компонентов на шкале от 0 до 255, где 0 означает, что компонент отсутствует, а 255 означает, что он имеет максимальную интенсивность.
Это дает нам первый способ задания цвета в GDI+. Можно указать значения для красного, синего и зеленого цветов, вызывая статическую функцию Color.FromArgb(). Компания Microsoft решила не поставлять конструктор для этой задачи. Причина в том, что существуют другие способы, помимо обычных компонентов RGB, для указания конструктора. В связи с этим Microsoft решила, что значения параметров, передаваемых в любой конструктор, будет подвержено неверной интерпретации: Color RedColor = Color.FromArgb(255, 0, 0); Color FunnyOrangyBrownColor = Color.FromArgb(255, 155, 100); Color BlackColor = Color.FromArgb(0, 0, 0); Color WhiteColor = Color.FromArgb(255, 255, 255); Три параметра являются соответственно количествами красного, синего и зеленого цвета. Существует ряд других перегружаемых методов для этой функции, некоторые из них также позволяют определить так называемую альфа-смесь (отсюда буква А в названии метода FromArgb()!). Альфа-смешивание не рассматривается в этой главе, оно позволяет рисовать полупрозрачными тонами, комбинируя с цветом, который уже имеется на экране. Это может создавать красивые эффекты и часто используется в играх. Именованные цветаСоздание структуры Colorс помощью FromArgb()является наиболее гибкой техникой, так как она по сути означает, что можно определить любой цвет, который различает человеческий глаз. Однако, если требуется простой, стандартный, хорошо известный цвет, такой как красный или синий, то значительно легче просто назвать требуемый цвет. В связи с этим Microsoft предоставляет также большое число статических свойств в Color, каждое из которых возвращает именованный цвет. Одно из этих свойств использовалось, когда в примерах задавался фоновый цвет окон как белый: this.BackColor = Color.White; // имеет такой же эффект, как и // this.BackColor = Color.FromArgb(255, 255, 255); Существует несколько сотен таких цветов. Полный список дан в документации MSDN. Он включает все простые цвета: Red, White, Blue, Green, Blackи т.д., а также такие, как MediumAquamarine, LightCoralи DarkOrchid.
Режимы вывода графики и палитра безопасностиПри том что в принципе мониторы могут вывести любой из 16 млн цветов RGB, на практике это зависит от того, как заданы свойства вывода изображения на компьютере. Делая щелчок правой кнопкой мыши на рабочем столе Windows и выбирая Settings в появляющейся таблице свойств, можно получить цветовое разрешение изображения. Здесь традиционно существует три основных варианта (хотя некоторые машины могут предоставлять другие возможности в зависимости от оборудования): true color (24-битовые), high color (16-битовые) и 256 цветов. (На некоторых графических платах сегодня true color в действительности помечены как 32-битовые с целью оптимизации аппаратного обеспечения, хотя в этом случае для самого цвета используются только 24 бита из 32). Только режим true color позволяет выводить одновременно все цвета RGB. Это лучший вариант, но требует дополнительных расходов: для хранения полного значения RGB требуется 3 байта, т. е. для хранения каждого выводимого пикселя требуется 3 байта памяти графической платы. Если памяти графической платы достаточно (ограничение, которое встречается сегодня реже), то можно выбрать такой режим. Режим high color использует два байта на пиксель. Этого достаточно, чтобы задать 5 битов для каждой компоненты RGB. Поэтому вместо 256 градаций интенсивности красного, получается только 32 градации; то же самое для синего и зеленого, что дает всего 65536 цветов. Этого вполне достаточно, чтобы получить почти фотографическое качество при поверхностном рассмотрении, хотя области с легким затенением покажутся слегка неровными. 256-цветовой режим дает еще меньше цветов. Однако в этом режиме можно выбрать используемые цвета. В системе задается так называемая палитра. Это список 256 цветов, выбранных из 16 миллионов цветов RGB. После задания цветов в палитре графическое устройство может выводить только эти цвета. Палитра изменяется в любое время, но графическое устройство по-прежнему выведет только 256 различных цветов в данный момент времени. 256-цветный режим используется в действительности только, когда необходимо получить высокую производительность и при небольшом объеме видеопамяти. Большинство игр будут использовать этот режим, но за счет тщательного выбора палитры они по-прежнему смогут предоставить хорошее графическое оформление. Вообще, если устройство вывода находится в режиме high color или 256 цветов и запрашивается для вывода определенного цвета RGB, то оно будет выбирать ближайшее математическое соответствие из пула доступных цветов. По этой причине важно знать о режимах цветов. При рисовании объекта, который содержит слабые затенения или имеет фотографическое качество, и если не выбран режим 24-битовых цветов, пользователь может не увидеть изображения в том виде, как это должно быть. Если работа такого рода делается с помощью GDI+, необходимо проверить приложение в различных режимах цветов. (Приложение может также программным путем задать цветовой режим, хотя этот вопрос здесь рассматриваться не будет). Палитра безопасностиДля справки мы кратко упомянем здесь палитру безопасности. Это обычно палитра, используемая по умолчанию. Она работает так, что для каждого цветового компонента задается шесть расположенных на одинаковом расстоянии друг от друга возможных значений. А именно, значения 0, 51, 102, 153, 204, 255. Другими словами, красный компонент может иметь любое из этих значений. То же самое можно сказать о зеленом и синем компонентах. Поэтому возможные цвета из палитры безопасности включают (0, 0, 0) (черный), (153, 0, 0) (достаточно темный оттенок красного), (0, 255, 102) (зеленый с небольшой голубизной) и т. д. Это дает всего 6 в кубе = 216 цветов. Идея состоит в том, что это дает нам простой способ иметь палитру, которая содержит цвета из всего спектра и всех степеней яркости, хотя на практике это работает не так хорошо, так как равное математическое разделение цветовых компонентов не значит равного восприятия различия цветов человеческим глазом. Но поскольку палитра безопасности широко используется, можно найти большое число приложений и изображений, которые используют цвета исключительно из палитры безопасности. При использовании 256-цветного режима Windows палитрой по умолчанию является палитра безопасности с добавленными 20 стандартными цветами Windows и 20 свободными цветами. Перья и кистиВ этом разделе мы сделаем обзор двух вспомогательных классов, которые нужны для рисования фигур. Мы уже встречали класс Pen, используемый для сообщения экземпляру Graphics, как рисовать линии. Связанным является класс System.Drawing.Brush, который говорит, как заполнять области. Например, Pen требуется для рисования контуров прямоугольников и эллипсов в рассмотренных ранее примерах. Если понадобится нарисовать эти фигуры как заполненные, то для этого должна использоваться кисть, которая определяет, как заполнять фигуру. Одной из особенностей этих двух классов является то, что на них вряд-ли когда-нибудь будут вызываться какие-либо методы. Обычно просто создается экземпляр Penили Brushс требуемым цветом и другими свойствами, а затем он передается в методы рисования. Рассмотрим сначала кисти, а затем — перья.
КистиGDI+ имеет несколько различных видов кистей, мы объясним простейшие из них, чтобы знать о принципах. Каждый тип кисти представлен экземпляром класса, производным из System.Drawing.Brush(этот класс является абстрактным, поэтому нельзя создать экземпляры объектов Brushкак только объекты производных классов). Простейшая кисть указывает, что область должна быть заполнена сплошным цветом. Этот вид кисти представлен экземпляром класса System.Drawing.SolidBrush, который можно создать таким образом: Brush solidBeigeBrush = new SolidBrush(Color.Beige); Brush solidFunnyOrangyBrownBrush = new SolidBrush(Color.FromArgb(255, 155, 100) Альтернативно, если кисть является одним из именованных цветов Интернета, то можно создать кисть более просто с помощью другого класса System.Drawing.Brushes. Brushesявляется одним из тех классов, экземпляры которых реально никогда не создаются (он имеет закрытый конструктор, чтобы не дать возможности это сделать). Большое число статических свойств возвращает кисть специального цвета. Brushesиспользуется так: Brush solidAzureBrush = Brushes.Azure; Brush solidChocolateBrush = Brushes.Chocolate; Следующий уровень сложности представляет штриховая кисть, которая заполняет область, рисуя некоторый шаблон-узор. Этот тип кисти находится в пространстве имен Drawing2D, представленном классом System.Drawing.Drawing2D.HatchBrush. Класс Brushesне сможет помочь в случае штриховой кисти, необходимо будет создать одну из них явно, задавая стиль штриховки и два цвета — цвет переднего плана и цвет фона (но можно опустить цвет фона, в таком случае по умолчанию используется черный цвет). Стиль штриховки задают с помощью перечисления System.Drawing.Drawing2D.HatchStyle. Существует большое число доступных значений HatchStyle, поэтому проще всего обратиться к документации MSDN для получения полного списка. Типичными стилями, например, являются ForwardDiagonal, Cross, DiagonalCross, SmallConfettiи ZigZag. Ниже приведены примеры создания штриховой кисти Brush crossBrush = new HatchBrush(HatchStyle.Cross, Color.Azure); // фоновый цвет для CrosstBrush будет черный Brush brickBrush = new HatchBrush(HatchStyle.DiagonalBrick, Color.DarkGoldenrod.Color.Cyan); Сплошные и штриховые кисти — единственные кисти, доступные в GDI. GDI+ добавляет пару новых стилей кисти: □ Кисть System.Drawing.Drawing2D.LinearGradientBrushзаполняет область цветом, который изменяется на экране. □ Кисть System.Drawing.Drawmg2D.PathGradientBrushдействует аналогично, но в этом случае цвет меняется вдоль кривой в закрашиваемой области. Мы не будем рассматривать здесь эти кисти. Отметим только, что обе они могут создать интересные эффекты при аккуратном использовании. Пример Bezierиз главы 9 использует кисть с линейным градиентом для закрашивания фона окна. ПерьяВ отличие от кистей перья представлены только одним классов — System.Drawing.Pen. Перо в действительности является немного более с южным, чем чисть, так как оно должно указывать толщину линий (ширину в пикселях), а для широкой линии,— как закрашивать область внутри нее. Перья могут также определять ряд других свойств, которые находятся за пределами нашего рассмотрения, но включают упоминавшееся ранее свойство Alignment, указывающее, где относительно границы фигуры должна быть нарисована линия, а также какую фигуру нарисовать в конце линии (нужно ли округлять форму). Область внутри толстой линии может быть закрашена сплошным цветом с помощью пера или кисти. Следовательно, экземпляр Pen может содержать ссылку на экземпляр Brush. Это достаточно мощное средство, так как при его содействии можно нарисовать линии, окрашенные с помощью штрихования или линейного затенения. Существует четыре различных способа, с помощью которых создаются экземпляры Pen. Можно задать цвет или кисть, оба эти конструктора будут создавать перо шириной в один пиксель. Можно также в дополнение к цвету или кисти задать значение типа float, представляющее ширину пера (на тот случай, если для объекта Graphics, который будет выполнять рисование, используются нестандартные единицы измерения, такие как миллиметры или дюймы, или доли дюймов). Поэтому, например, можно так создавать перья: Brush brickBrush = new HatchBrush(HatchStyle.DiagonalBrick, Color.DarkGoldenrod, Color.Cyan); Pen solidBluePen = new Pen(Color.FromArgb(0, 0, 255)); Pen solidWideBluePen = new Pen(Color.Blue, 4); Pen brickPen = new Pen(BrickBrush); Pen brickWidePen = new Pen(BrickBrush, 10); Кроме того, для быстрого создания перьев можно использовать класс System.Drawing.Pens, который подобно классу Brushesсодержит ряд готовых перьев. Эти перья все имеют ширину в один пиксель и используют обычное множество именованных цветов Интернета, что позволяет создавать перья таким образом: Pen SolidYellowPen = Pens.Yellow; Рисование фигур и линийВ первой части главы были рассмотрены базовые классы и объекты, требуемые для рисования специальных фигур и т.д. на экране. Теперь дадим обзор некоторых методов рисования, предоставляемых классом Graphics, и в конце — кратким примером проиллюстрируем несколько кистей и перьев. System.Drawing.Graphicsимеет большое число методов, позволяющих рисовать различные линии, контуры фигур и сплошные фигуры. Их существует слишком много, но таблица (см. ниже) представляет основные методы и дает представление о множестве фигур, которые можно нарисовать.
Прежде чем закончить тему рисования простых объектов, создадим пример, который демонстрирует разновидности визуальных эффектов, создаваемых с помощью кистей. Пример называется ScrollMoreShapesи является по сути пересмотром примера ScrollShapes. Помимо прямоугольника и эллипса, добавим толстую линию и закрасим фигуры с помощью различных кистей. Мы уже объясняли принципы рисования, поэтому код представлен с минимальными комментариями. Первое: в связи с новыми кистями, нам нужно указать, что используется пространство имен System.Drawing.Drawing2D: using System; using System.Drawing; using System.Drawing.Drawing2D; using System.Collections; using System.ComponentModel; using System.Windows.Forms; using System.Data; Используем несколько дополнительных полей в классе Form1, которые содержат данные о местах, где должны быть нарисованы фигуры, а также различные перья и кисти: private Rectangle rectangleBounds = new Rectangle(new Point(0, 0), new Size(200, 200)); private Rectangle ellipseBounds = new Rectangle(new Point(50, 200), new Size(200, 150)); private Pen BluePen = new Pen(Color.Blue, 3); private Pen RedPen = new Pen(Color.Red, 2); private Brush SolidAzureBrush = Brushes.Azure; private Brush CrossBrush = new HatchBrush(HatchStyle.Cross, Color.Azure); static private Brush BrickBrush = new HatchBrush(HatchStyle.DiagonalBrick, Color.DarkGoldenrod, Color.Cyan); private Pen BrickWidePen = new Pen(BrickBrush, 10); Поле BrickBrushобъявлено как статическое, чтобы использовать его значение в инициализаторе BrickWidePen, который далее следует. C# не позволит использовать поле одного экземпляра объекта для инициализации поля другого экземпляра, так как не определено, какое из них будет инициализировано первым. Но объявление поля как static решает проблему, так как создается только один экземпляр класса Form1, поэтому неважно, будут ли поля статическими или полями экземпляра. Вот метод OnPaint(): protected override void OnPaint(PaintEventArgs e ) { Graphics dc = e.Graphics; Point scrollOffset = this.AutoScrollPosition; dc.TranslateTransform(scrollOffset.X, scrollOffset.Y); if (e.ClipRectangle.Top+scrollOffset-X < 350 || e.ClipRectangle.Left+scrollOffset.Y < 250) { dc.DrawRectangle(BluePen, rectangleBounds); dc.FillRectangle(CrossBrush, rectangleBounds); dc.DrawEllipse(RedPen, ellipseBounds); dc.FillEllipse(SolidAzureBrush, ellipseBounds); dc.DrawLine(BrickWidePen, rectangleBounds.Location, ellipseBounds.Location + ellipseBounds.Size); } base.OnPaint(e); } А это результат:  Отметим, что толстая диагональная линия лежит поверх прямоугольника и эллипса, так как это был последний нарисованный элемент. Вывод изображенийОдним из наиболее распространенных действий, которое может понадобиться сделать с помощью GDI+, является вывод изображений, уже существующих в файле. Это значительно проще, чем рисование своего собственного интерфейса пользователя, так как изображение уже было нарисовано. По сути необходимо только загрузить файл и приказать GDI+ вывести его. Изображение может быть простым графическим рисунком, пиктограммой или сложным изображением, таким как фотография. Можно выполнить некоторые манипуляции с изображением, такие как растягивание и вращение, или вывести только его часть. В данном разделе представим пример, затем обсудим несколько вопросов, о которых необходимо знать при выводе изображений. Мы можем сделать это, так как код для вывода изображений очень прост. Image MyImage = Image.FromFile("FileName"!); FromFile()является статическим членом класса Imageи обычным способом создает экземпляр изображения. Файл может быть любым из обычно поддерживаемых форматов графических файлов, включая .bmp, .jpg, .gifи .png. Вывод изображения требует также только одну строку кода в предположении, что имеется подходящий экземпляр объекта Graphics: dc.DrawImageUnscaled(MyImage, TopLeft); В этой строке кода dcпредполагается экземпляром объекта Graphics, MyImageявляется Image, который будет выведен, a TopLeft— структурой Point, которая хранит координаты устройства, где требуется поместить изображение. Трудно представить себе что-то более простое.
Мы проиллюстрируем процесс вывода изображения с помощью примера DisplayImage. Этот пример просто выводит файл .jpgв основном окне приложения. Чтобы упростить код, путь доступа файла .jpgжестко закодирован в приложении (поэтому при выполнении приложения необходимо изменить его в соответствии с местоположением файла на используемой системе). Выводимый файл .jpgявляется групповой фотографией участников встречи COMFest. Как обычно в этой главе, проект DisplayImageявляется стандартным приложением Windows, созданным с помощью VisualStudio.NET. Мы добавляем следующее поле в класс Form1: Image Piccy; Затем загружаем файл в процедуру InitializeComponent. private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(600, 400); this.Text = "Display COMFEst Image"; this.BackColor = Color.White; Piccy = Image.FromFile(@"C:\ProCSharp\Chapter21\Display Image\CF4Group.jpg"); this.AutoScrollMinSize = Piccy.Size; } Отметим, что размер изображения в пикселях задается как его свойство Size, которое используется для задания области документа. Изображение выводится в методе OnPaint(): protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; dc.DrawImageUnscaled(Piccy, this.AutoScrollPosition); base.OnPaint(e); } Выбор this.AutoScrollPositionв качестве координатного устройства гарантирует, что окно будет прокручиваться правильно, при этом до начала прокручивания изображение будет располагаться с верхнего левого угла клиентской области. Наконец, сделаем еще одно замечание об изменениях, сделанных в коде метода Form1.Dispose(), созданном мастером: public override void Dispose() { base.Dispose(); if (components != null) components.Dispose(); Piccy.Dispose(); } Удаление изображения, когда оно не требуется, является важной задачей, так как изображения обычно требуют много памяти. После вызова Image.Dispose()экземпляр Imageбольше не ссылается на какое-либо реальное изображение и поэтому не может больше выводиться (если не будет загружено новое изображение). Выполнение этого кода создает результат: 
Вопросы, возникающие при манипуляциях с изображениямиВывод изображений выполнить легко, но все же требуется некоторое понимание описанной ниже технологии. Наиболее важным моментом при работе с изображениями является то, что они всегда прямоугольные. Это не просто удобство для людей. Такая форма связана с тем, что все современные графические платы имеют встроенное оборудование, которое может очень эффективно копировать блоки пикселей из одного участка памяти в другой. При условии, что блок пикселей представляет прямоугольную область, аппаратное ускорение выполняется практически как одна операция, и поэтому будет очень быстрым. На самом деле это ключ к современной высокопроизводительной графике. Такая операция называется переносом битовых блоков (BitBlt). Image.DrawImageUnscaled()внутренне использует BitBlt, вот почему можно видеть огромное изображение, содержащее, возможно, миллионы пикселей (фотография из примера имеет 104975 пикселей) появляющимся почти мгновенно. Если бы компьютер должен был копировать изображение на экран пиксель за пикселем, то изображение постепенно появлялось бы в течение нескольких секунд. Метод BitBltочень эффективен, поэтому почти все операции рисования и манипуляции с изображениями выполняются с его помощью. Даже некоторое редактирование изображений будет делаться с помощью BitBlt, перенося части изображений между контекстами устройств, которые представляют области памяти. При использовании GDI функция BitBlt()из API Windows 32 была, наверное, самой важной и широко используемой функцией для манипуляции изображениями, хотя в GDI+ операции BitBltпо большей части скрыты объектной моделью GDI+. Невозможно использовать BitBltдля областей, которые не являются прямоугольными, что можно легко смоделировать. Один из способов состоит в пометке некоторого цвета как прозрачного для целей BitBltпоэтому данная область цвета в изображении-источнике не будет перезаписывать существующий цвет соответствующего пикселя на получающем устройстве. Можно также определить, что в процессе выполнения BitBltкаждый пиксель получающегося изображения будет сформирован перед BitBltнекоторой логической операцией (такой, как побитовое AND) на цветах этого пикселя в изображении-источнике и в получающем устройстве. Такие операции поддерживаются аппаратным ускорителем и могут использоваться для задания ряда тонких эффектов. Не рассматривая детали процесса, отметим что объект Graphicsреализует другой метод DrawImage(). Он аналогичен методу DrawImageUnscaled(), но поставляется с большим числом перезагружаемых версий, которые позволяют определить более сложные формы BitBltдля использования в процессе рисования. DrawImage()позволяет также рисовать ( BitBlt) только определенную часта изображения, или выполнить на нем некоторые другие операции, такие как масштабирование (увеличение или уменьшение размера) при его рисовании. Рисование текстаМы отложили рисование текста на экране до этого момента, так как эта очень важная тема является в целом более сложной задачей, чем рисование графики. Необходимо уточнить это утверждение. Вывод одной или двух строк текста без учета их вида является очень простым, требуя вызова одного из методов экземпляра Graphics, Graphics.DrawString(). Однако при попытке вывести документ, содержащий большое количество текста, быстро обнаруживается значительное усложнение процесса. Это обусловлено двумя причинами: □ Первое: для получения аккуратного изображения необходимо понимать шрифты. Там, где для рисования фигуры используются кисти и перья в качестве вспомогательных объектов, процесс рисования текста требует соответственно шрифтов в качестве вспомогательных объектов. Понимание шрифтов является не простой задачей. В следующем разделе будет предоставлено краткое введение в предмет. Заметим, однако, что детали шрифтов являются более сложными, чем кистей и перьев. □ Второе: текст необходимо очень аккуратно разместить в окне. Пользователя обычно ожидают слова, которые естественно следуют одно за другим выровненными с пробелами между словами. Сделать это труднее, чем кажется. Обычно заранее неизвестно, сколько места на экране потребуется для слова (в отличие от фигуры). Это должно вычисляться (не беспокойтесь, это не придется делать вручную, так как существует метод Graphics.MeasureString(), который это сделает). Также пространство занимаемое словом на экране, будет влиять на местоположение каждого последующего слова документа. Если приложение выполняет перенос строк, то ему придется тщательно оценивать размеры слов, прежде чем решить, где поместить разрыв. Посмотрев внимательно на работу Word for Windows, можно заметить, что Word непрерывно изменяет положение текста при вводе, изменении шрифта, вырезании, вставке, и т. д. При этом выполняется большая обработка, включающая некоторые очень тщательно отработанные алгоритмы. Конечно, проектируемое приложение GDI+ не обязательно должно быть таким же сложным, как Word, но если потребуется вывести произвольный текст, то многие из таких же рассмотрений будут по-прежнему в силе. Поэтому конечная часть этой главы посвящена примеру, допускающему простые манипуляции с текстом, чтобы дать некоторое представление о проблемах, которые возникают в подобных приложениях, и об их возможных решениях. Обработка текста с хорошим качеством не является невозможной, она просто сложна для правильного выполнения. Как было упомянуто ранее, реальный процесс вывода строки текста на экран при условии знания шрифта и места вывода трудности не представляет. Поэтому далее будет дан краткий пример, показывающий, как выводить фрагменты текста. В оставшейся части главы вы найдете обзор некоторых принципов Fonts и Font Families, прежде чем мы перейдем к более реалистичному примеру обработки текста CapsEditor, который продемонстрирует аспекты размещения текста на экране, а также покажет, как обрабатывать пользовательский ввод. Простой пример с текстомПример является обычным результатом работы Windows Forms. В этот раз метод OnPaint()переопределяется следующим образом: protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; Brush blackBrush = Brushes.Black; Brush blueBrush = Brushes.Blue; Font haettenschweilerFont = new Font("Haettenschweiler", 12); Font boldTimesFont = new Font("Times New Roman", 10, FontStyle.Bold); Font italicCourierFont = new Font("Courier", 11, FontStyle.Italic | FontStyle.Underline); dc.DrawString("This is a groovy string", haettenschweilerFont, blackBrush, 10, 10); c.DrawString("This is a groovy string " + "with some very long text that will never fit in the box", boldTimesFont, blueBrush, new Rectangle(new Point(10, 40), new Size(100, 40))); dc.DrawString("This is a groovy string", italicCourierFont, blackBrush, new Point(10, 100)); base.OnPaint(e); } Выполнение этого примера создает вывод:  Этот пример демонстрирует использование метода Graphics.DrawString()для рисования элементов текста. Существует несколько перезагружаемых версий DrawString(), из которых показаны три. Все различные версии требуют параметры, указывающие выводимый текст, шрифт для рисования текста и кисть, которая должна использоваться для создания различных линий и кривых, составляющих символы текста. Для оставшихся параметров существуют альтернативы. В целом, однако, можно определить либо Point(или эквивалентно два числа), либо Rectangle. Если определяется Point, то текст начнется своим верхним левым углом в этой точке Pointи развернется вправо. Если определить Rectangle, то экземпляр Graphicsпоместит строку внутри этого прямоугольника. Если текст не впишется в границы прямоугольника, то он будет обрезан, как видно на снимке экрана. Передача прямоугольника в D rawString() означает, что процесс рисования продолжится дольше, так как DrawString()необходимо определить, где поместить разрывы строки, но результат может выглядеть лучше (если строка вписывается в прямоугольник). Этот пример показывает также способы создания шрифтов. Всегда требуется имя шрифта и его размер (высота). Можно также при желании передать различные стили, изменяющие вид текста (жирный, подчеркивание и т. д.). Шрифты и семейства шрифтовВсе интуитивно считают, что достаточно хорошо понимают шрифты. В конце концов мы видим их почти постоянно. Шрифт точно описывает, как должна выводиться каждая буква. Выбор подходящего шрифта, а также предоставление разумного множества шрифтов в документе является важным фактором улучшения читабельности документа. Можно просто взглянуть на страницы этой книги, чтобы увидеть, сколько использовалось шрифтов. Нужно тщательно выбирать шрифты, поскольку плохой выбор шрифта может существенно повредить как привлекательности, так и использованию приложения. Многие при вопросе о названии шрифта скажут что-нибудь типа 'Arial' или 'Times New Roman' или 'Courier'. Фактически это не шрифты вообще, это семейства шрифтов. Шрифты будут чем-нибудь типа Arial 9-point italic. Семейство шрифтов сообщает в общих терминах визуальный стиль текста и является ключевым фактором в общем представлении приложения. Большинство людей способны распознавать стили наиболее распространенных семейств шрифтов, даже если и не осознают этого. Шрифт добавляет дополнительную информацию, определяя размер текста, а также применение к тексту определенных модификаций. Например, будет ли это жирный, курсив или подчеркнутый текст, выведется ли он ЗАГЛАВНЫМИ БУКВАМИ или как подстрочный индекс. Такие модификации технически называются стилями, хотя в некотором смысле термин вводит в заблуждение, поскольку только что было отмечено, что визуальное представление определяется в основном семейством шрифта. Размер текста определяется его высотой. Высота измеряется в пунктах (points) — традиционная единица измерения, которая представляет 1/72 дюйма (для людей, живущих за пределами Великобритании и США, пункт равен 0.351 мм). Поэтому, например, буквы в 10-пунктовом шрифте имеют в высоту 10/72 дюйма (или приблизительно 1/7", или 3.5 мм). Из этого объяснения может показаться, что семь строк текста с размером шрифта 10 разместятся по вертикали на одном дюйме экрана или пространства бумаги. Фактически их будет немного меньше, так как необходимо также обеспечить интервалы между строками.
Иногда при работе со шрифтами могут встретиться и другие термины, используемые для описания некоторых семейств шрифтов. □ Семейство шрифтов serif имеет небольшие черточки на концах многих линий, которые составляют символы. Эти черточки называют засечками (serifs). Times New Roman является классическим примером такого шрифта. □ Семейства шрифтов sans serif, в противоположность, не имеют этих черточек. Хорошими примерами шрифтов sans serif являются Arial и Verdana. Отсутствие черточек часто придает тексту резкий, бросающийся в глаза вид, поэтому шрифты sans serif часто используются для выделения важного текста. □ В семействе шрифтов true type очертания кривых, формирующих символы, вычисляются точными математическими способами. Это означает, что одно и то же определение может использоваться для вычисления того, как нарисовать шрифты семейства любого размера. Сегодня практически все используемые шрифты являются шрифтами true type. Некоторые старые семейства шрифтов из Windows 3.1 определялись с помощью отдельного битового изображения для каждого символа любого размера, но сегодня эти шрифты не используются. (Среди других недостатков они вызывают проблемы при переходе от экрана к современному принтеру, где число пикселей на дюйм значительно больше, поэтому битовые изображения будут выглядеть слишком маленькими). Microsoft предоставляет два основных класса, с которыми необходимо иметь дело при выборе или манипуляциях со шрифтами. Это классы System.Drawing.Fontи System.DrawingFontFamily. Мы уже видели основное использование класса Font. Когда необходимо нарисовать текст, создается экземпляр класса Fontи передается методу DrawStringдля указания того, как должен быть нарисован текст. Экземпляр FontFamilyиспользуется для представления семейств шрифтов. Одно из применений класса FontFamilyвозникает в ситуации, когда требуется шрифт определенного типа (Serif, SansSerif или Monospace), но неважно какой. Статические свойства GenericSerif, GenericSansSerifи GenericMonospaceвыявляют используемые по умолчанию шрифты, соответствующие этим критериям: FontFamily sansSerifFont = FontFamily.GenericSansSerif; Однако при написании профессионального приложения желательно выбирать шрифт более тщательно. Скорее всего, код рисования реализуется таким образом, что будет проверять, какие семейства шрифтов реально установлены на компьютере и, следовательно, какие шрифты доступны. Затем приложение выберет подходящий шрифт, возможно, взяв первый доступный шрифт из списка предпочтительных шрифтов. Если желательно, чтобы приложение имело более дружественный пользовательский интерфейс, то первым вариантом в списке предпочтительных будет шрифт, который пользователь выбирал в последний раз при выполнении этого приложения. Обычно используются наиболее популярные семейства шрифтов, такие как Arial и Times New Roman. Но если попробовать вывести текст с помощью шрифта, который не существует, результаты не всегда будут предсказуемы, и, скорее всего, Windows просто подставит стандартный системный шрифт, который очень легко нарисовать системе, но который выглядит не совсем удачно и, появившись в документе, создаст впечатление программного обеспечения плохого качества. Шрифты, доступные в системе, можно определить с помощью класса, называемого InstalledFontCollection, который находится в пространстве имен System.Drawing.Text. Этот класс представляет реализации свойства Families, которое является массивом всех шрифтов, доступных для использования в системе: InstalledFontCollection insFonc = new InstalledFontCollection(); FontFamily [] families = insFont.Families; foreach (FontFamily family in families) { // выполнить обработку с помощью этого семейства шрифтов } Пример: перечисление семейств шрифтовВ этом разделе мы разберем небольшой пример EnumFontFamilies, который перечисляет все семейства шрифтов, доступные в системе, и проиллюстрирует их, выводя имя каждого семейства с помощью подходящего шрифта (10-пунктовой обычной версии семейства этого шрифта). Когда пример выполняется, он выглядит так:  Отметим, однако, что в зависимости от установленных на компьютере шрифтов можно получить различные результаты. Для этого примера, как обычно, создается стандартное приложение C# для Windows с именем EnumFontFamilies. Затем мы добавляем следующую константу в класс Form1: const int margin = 10; marginявляется размером левого и верхнего полей между текстом и краем документа, он не позволяет тексту разместится прямо на крае клиентской области. Это приложение создано лишь с целью показать семейства шрифтов, поэтому код упрощенный и во многих случаях делает вещи не так, как должно делаться в настоящих приложениях. Например, здесь жестко закодировано предполагаемое значение размера документа вместо вычисленного, который мог бы определить, сколько пространства потребуется реально для вывода списка семейств шрифтов. (Мы будет использовать более правильный подход в следующем примере). Поэтому метод InitializeComponent()выглядит подобным образом: private void InitializeComponent() { this.components = new System.ComponentModel.Container(); this.Size = new System.Drawing.Size(300, 300); this.Text = "EnumFontFamilies"; this.BackColor = Color.White; this.AutoScrollMinSize = new Size(200, 500); } А вот метод OnPaint(): protected override void OnPaint(PaintEventArgs e) { int verticalCoordinate = margin; Point topLeftCorner; InstalledFontCollection insFont = new InstalledFontCollection(); FontFamily [] families = insFont.Families; e.Graphics.TranslateTransform(AutoScrollPosition.X, AutoScrollPosition.Y); foreach (FontFamily family in families) { if (family.IsStyleAvailable(FontStyle.Regular)) { Font f = new Font(family.Name, 10); topLeftCorner = new Point(margin, verticalCoordinate); verticalCoordinate += f.Height; e.Graphics.DrawString(family.Name, f, Brushes.Black, topLeftCorner); f.Dispose(); } } base.OnPaint(e); } Этот код начинается с использования объекта InstalledFontCollectionдля получения массива, содержащего данные обо всех доступных семействах шрифтов. Для каждого семейства создается экземпляр шрифта размером 10 пунктов. Здесь для Fontиспользуется простой конструктор, существует множество других, которые требуют определения большего числа параметров. Выбранный конструктор использует два параметра: имя семейства и размер шрифта: Font f = new Font(family.Name, 10); Конструктор создает шрифт обычного стиля (т. е. не подчеркнутый, не курсив, не перечеркнутый). Однако на всякий случай сначала проверим, что этот стиль доступен для каждого семейства шрифтов, прежде чем пытаться вывести что-либо с его помощью. Это делается с применением метода FontFamily. IsStyleAvailable(), и такая проверка важна, так как не все шрифты доступны во всех стилях: if (family.IsStyleAvailable(FontStyle.Regular)) FontFamily.IsStyleAvailable()получает один параметр — перечисление FontStyle. Это перечисление содержит ряд флажков, комбинирующихся с помощью оператора OR. Возможными флажками являются Bold, Italic, Regular, Strikeoutи Underline. Наконец, отметим, что здесь используется свойство Heightкласса Font, которое определяет высоту, необходимую для вывода текста этим шрифтом с учетом интервала между строками. Font f = new Font (family.Name, 10); topLeftCorner = new Point(margin, verticalCoordinate); VerticalCoordinate += f.Height; Для упрощения кода используемая версия OnPaint()демонстрирует несколько слабых приемов программирования. Вначале мы не подумали проверить, какую область документа в действительности надо нарисовать, мы просто пытаемся вывести все. Создание экземпляра Font, как отмечалось ранее, является интенсивным вычислительным процессом, поэтому на самом деле необходимо сохранять шрифты, а не создавать экземпляры новых копий всякий раз, когда вызывается OnPaint(). Мы заметили, что этот пример требует для своего рисования немало времени. Чтобы сберечь память и помочь сборщику мусора, мы вызываем Dispose()на каждом экземпляре шрифта после завершения с ним работы. Если этого не сделать, то после 10 или 20 операций рисования будет существовать большой объем бесполезно используемой памяти, хранящей шрифты, которые больше не требуются. Редактирование текстового документа: пример CapsEditorМы переходим теперь к самому большому примеру этой главы. Пример CapsEditorсоздан для иллюстрации того, как принципы рисования, которые были до сих пор изучены, применить в более реальных условиях. Здесь не требуется никакого нового материала, кроме ответа на ввод пользователя с помощью мыши, но будет показано, как управлять рисованием текста так, чтобы приложение поддерживало производительность, гарантируя в то же время, что содержимое клиентской области основного окна всегда актуально. Программа CapsEditorфункционально является совсем простой. Она позволяет пользователю прочитать текстовый файл, который затем выводится построчно в клиентской области. Если пользователь делает двойной щелчок на любой строке, она будет изменяться в символы верхнего регистра. Это фактически все, что делает пример. Даже с таким ограниченным набором свойств мы обнаружим, что работа, вовлеченная в реализацию того, чтобы все выводилось в нужном месте, учитывая при этом вопросы производительности (выводить только то, что нужно, в данном вызове OnPaint()), будет достаточно сложно. В частности, мы имеем здесь новый элемент, связанный с изменением содержимого документа, происходящим в то время, когда пользователь выбирает пункт меню для считывания нового файла, либо когда он делает двойной щелчок, чтобы перевести строку в верхний регистр. В первом случае нам необходимо исправить размер документа, чтобы панели прокрутки по-прежнему работали правильно, и снова все вывести на экран. Во втором случае надо тщательно проверить, изменился ли размер документа и какой текст необходимо перерисовать. Дадим обзор внешнего представления CapsEditor. Когда приложение начинает выполняться, оно не имеет загруженного документа и выводит:  Меню File имеет два пункта: Open и Exit. Exit заканчивает приложение, в то время как Open выводит стандартное диалоговое окно для открытия файла и считывает файл, который выбирает пользователь. На снимке показано использование CapsEditorдля просмотра своего собственного файла исходного кода Form1.cs. Там также случайным образом были сделаны двойные щелчки мышью на нескольких строчках для преобразования их в верхний регистр:  Размеры вертикальной и горизонтальной панелей прокрутки являются, кстати, правильными. Клиентская область будет прокручиваться так, чтобы можно было просмотреть весь документ. CapsEditorне пытается переносить строки текста, пример уже усложнен в достаточной степени и без этого. Программа просто выводит каждую строку файла точно так, как ее читает. Не существует ограничений на размер файла, но предполагается, что это текстовый файл, который не содержит никаких непечатных символов. Добавляем некоторые поля в класс Form1, которые нам понадобятся: #region constant fields private const string standardTitle = "CapsEditor"; // текст по умолчанию в заголовке private const uint margin = 10; // горизонтальное и вертикальное поля в клиентской области #endregion #region Member fields private ArrayList documentLines = new ArrayList(); // "документ" private uint lineHeight; // высота одной строки в. пикселях private Size documentSize; // какой требуется размер клиентской // области для вывода документа private uint nLines; // число строк в документе private Font mainFont; // шрифт, используемый для вывода // всех строк private Font emptyDocumentFont; // шрифт, используемый для вывода // сообщения Empty private Brush mainBrush = Brushes.Blue; // кисть, используемая для вывода текста документа private Brush emptyDocumentBrush = Brushes.Red; // кисть, используемая для вывода сообщения empty document private Point mouseDoubleClickPosition; // положение мыши при двойном щелчке private OpenFileDialog fileOpenDialog = new OpenFileDialog(); // стандартный диалог открытия файла private bool documentHasData = false; // задать как true, если документ содержит данные #endregion Поле documentLinesявляется ArrayList, который содержит прочитанный текст файла. В реальном смысле это поле содержит данные документа. Каждый элемент DocumentLinesвключает данные одной строки текста, который был считан. Этот объект ArrayListпредпочтительнее обычного массива C#, так что можно динамически добавлять в него элементы, когда считывается файл. Можно заметить, что достаточно свободно используются директивы препроцессора #regionдля объединения в блоки частей программы, чтобы ее было легче редактировать. Как было сказано, каждый элемент documentLinesсодержит информацию о строке текста. Эта информация является на самом деле экземпляром другого класса, который был определен — TextLineInformation: class TextLineInformation { public string Text; public uint Width; } TextLineInformationвыглядит как классический случай обычного использования структуры, а не класса, так как требуется только сгруппировать поля. Однако его экземпляры всегда доступны в качестве элементов класса ArrayList, в котором они хранятся как ссылочные типы. Поэтому объявление TextLineInformationклассом приводит к более эффективным действиям, сохраняя множество операций упаковки и распаковки. Каждый экземпляр TextLineInformationхранит строку текста и выводится как один элемент. Обычно для каждого такого элемента в приложении GDI+ желательно сохранять его текст, а также мировые координаты, где он должен выводиться, и размер. Обратите внимание, что используются мировые координаты, а не координаты страницы. Координаты страницы часто изменяются, когда пользователь прокручивает текст, в то время как мировые координаты меняются лишь в случае, когда другие части документа преобразуются каким-то образом. В данном случае мы сохранили только Widthэлемента, так как высота здесь является просто высотой выбранного шрифта. Она одинакова для всех строк текста, поэтому нет смысла хранить ее отдельно для каждой строки. Вместо этого она сохраняется только однажды в поле Form1.lineHeight. Что касается позиции, то в данном случае координата х просто равна граничному полю, а координата у легко вычисляется как: Margin + LineHeight*(количество строк выше текущей строки) Если бы мы попытались выводить и манипулировать, скажем, отдельными словами вместо полных строк, то позиция х каждого слова должна была бы вычисляться с помощью значений ширины всех предыдущих слов в этой строке текста. Но чтобы сохранить пример простым, мы интерпретируем каждую строку текста как один элемент. Займемся теперь основным меню. Эта часть приложения принадлежит к формам Windows — тема рассмотрения главы 9. Пункты меню были добавлены с помощью графического представления в Visual Studio.NET, но переименованы как menuFileOpenи menuFileExit. Затем код в InitializeComponent()был изменен, чтобы добавить подходящие обработчики событий, а также выполнить некоторую инициализацию: private void InitializeComponent() { // добавлено мастером построения кода this.menuFileOpen = new System.Windows.Forms.MenuItem(); this.menuFileExit = new System.Windows.Forms.MenuItem(); this.mainMenu1 = new System.Windows.Forms.MainMenu(); this.menuFile = new System.Windows.Forms.MenuItem(); this.menuFileOpen.Index = 0; this.menuFileOpen.Text = "Open"; this.menuFileExit.Index = 3; this.menuFileExit.Text = "Exit"; this.mainMenu1.MenuItems.AddRange(new System.Windows.Forms.MenuItem[] {this.menuFile}); this.menuFile.Index = 0; this.menuFile.MenuItems.AddRange( new System.Windows.Forms.MenuItem[] {this.menuFileOpen, this.menuFileExit}); this.menuFile.Text = "File"; this.menuFileOpen.Click += new System.EventHandler(this, menuFileOpen_Click); this.menuFileExit.Click += new System.EventHandler(this.menuFileExit_Click); this.AutoScaleBaseSize = new System.Drawing.Size(5, 13); this.BackColor = System.Drawing.Color.White; this.Size = new Size(600, 400); this.Menu = this.mainMenu1; this.Text = standardTitle; CreateFonts(); FileOpenDialog.FileOk += new System.ComponentModel.CancelEventHandler(this.OpenFileDialog_FileOk); } Мы добавили обработчики событий для пунктов меню File и Exit, а также для диалога FileOpen, который выводится, когда пользователь выбирает Open. CreateFonts()является вспомогательным методом, выбирающим шрифты: private void CreateFonts() { mainFont = new Font("Arial", 10); lineHeight = (uint)mainFont.Height; emptyDocumentFont = new Font("Verdana", 13, FontStyle.Bold); } Реальное определение обработчиков является достаточно стандартным материалом: protected void OpenFileDialog_FileOk(object Sender, CancelEventArgs e) { this.LoadFile(fileOpenDialog.FileName); } protected void menuFileOpen_Click(object sender, EventArgs e) { fileOpenDialog.ShowDialog(); } protected void menuFileExit_Click(object sender, EventArgs e) { this.Close(); } Исследуем метод LoadFile(). Он занимается открытием и считыванием файла (а также обеспечивает инициирование события Paint, чтобы была выполнена перерисовка с новым файлом). private void LoadFile(string FileName) { StreamReader sr = new StreamReader(FileName); string nextLine; documentLines.Clear(); nLines = 0; TextLineInformation nextLineInfo; while ((nextLine = sr.ReadLine()) != null) { nextLineInfo = new TextLineInformation(); nextLineInfо.Text = nextLine; documentLines.Add(nextLineInfo); ++nLines; } sr.Close(); documentHasData = (nLines > 0) ? true : false; CalculateLineWidths(); CalculateDocumentSize(); this.Text = standardTitle + " " + FileName; this.Invalidate(); } Большая часть этой функции является просто стандартным кодом чтения файла (см. главу 14). Обратите внимание, что по мере чтения файла мы последовательно добавляем строки в documentLines ArrayList, поэтому массив в конце содержит информацию для каждой строки по порядку. После считывания файла устанавливается флаг documentHasDataдля указания, что действительно что-то есть для вывода на экран. Далее определяется содержание и место, а затем клиентская область, т.е. размер документа влияющий на задание панелей прокрутки. В конце добавляется текст строки заголовка и вызывается метод Invalidate(). Invalidate()является важным методом, поставляемым Microsoft. Поэтому мы постараемся объяснить его использование, прежде чем переходить к коду методов CalculateLineWidths()и CalculateDocumentSize(). Метод Invalidate()Invalidate()является членом System.Windows.Forms.Form, с которым мы еще не встречались. Это очень полезный метод для случая, когда что-то необходимо перерисовать. По сути он отмечает область клиентского окна как недействительную и поэтому требующую перерисовки, а затем обеспечивает инициирование события Event. Существует две перезагружаемые версии метода Invalidate(): можно передать ему прямоугольник, который точно определяет (в координатах страницы), какая область окна требует перерисовки, или, если не передается никаких параметров, вся клиентская область помечается как недействительная. Почему мы делаем это таким образом? Если мы знаем, что требуется что-то нарисовать, почему не вызвать просто OnPaint()или другой метод? При необходимости сделать на экране очень точное небольшое изменение, можно так и поступить, но обычно вызов процедур рисования напрямую рассматривается как плохая практика программирования. Если код решает, что требуется выполнить некоторое рисование, обычно вызывается метод Invalidate(). Для этого существует несколько причин: □ Рисование почти всегда является наиболее интенсивно использующей процессор задачей, которую будет решать приложение GDI+. Выполнение его в середине другой работы задерживают эту работу. Для нашего примера, если бы метод рисования вызывался прямо из метода LoadFile(), то метод LoadFile()не вернул бы управление, пока не завершена задача рисования. В течение этого времени приложение не сможет ответить ни на одно иное событие. С другой стороны, вызывая метод Invalidate(), мы просто поручаем Windows инициировать событие Paintперед непосредственным выходом из LoadFile(). Система Windows тогда сможет проверить события, ожидающие обработки. Внутренне это происходит следующим образом. События находятся в так называемых сообщениях, которые выстраиваются в очередь. Система Windows периодически проверяет очередь сообщений, и если в ней есть события, Windows берет одно из них и вызывает соответствующий обработчик событий. С большой вероятностью событие Paint— единственное событие, находящееся в очереди, поэтому OnPaint()будет немедленно вызван в любом случае. Однако в более сложных приложениях могут быть другие события, некоторые из них имеют приоритет. В частности, если пользователь решил покинуть приложение, это будет отмечено сообщением в очереди, известном как WM_QUIT. Обработка такого события будет иметь самый высокий приоритет. Это очевидно, так как выполнение, например обновления графики в окне приложения, которое в данный момент будет закрыто, не имеет смысла. Таким образом, использование для рисования области метода Invalidate()сортировки запросов означает, что приложение действует, как хорошо ведущее себя приложение Windows. □ В случае более сложного, мультипоточного приложения желательно, чтобы только один поток выполнения обрабатывал все рисование. Использование метода Invalidate()для направления всего рисования в очередь сообщений предоставляет гарантию, что один и тот же поток выполнения (какой бы поток выполнения ни отвечал за очередь сообщений, это будет поток выполнения, который вызвал Application.Run()) произведет рисование безотносительно к тому, какие другие потоки выполнения запрашивают операцию рисования. □ Существует также причина, связанная с производительностью. Предположим, что примерно в одно время поступает пара различных запросов для рисования части экрана. Возможно, что код только что сделал изменение документа и хочет убедиться, что обновленный документ выводится, а в то же самое время пользователь восстановил минимизированное окно или переместил другое окно, которое закрывало часть клиентской области. Вызывая Invalidate(), мы даем знать окну, что это произошло. Windows может затем объединить события Paint, если это возможно, комбинируя недействительные области, так что рисование будет выполняться только один раз. (Вызов метода для выполнения рисования прямо из кода может привести к ненужному результату, когда одна и та же область экрана будет перерисовываться более одного раза.) □ Наконец, код для выполнения рисования будет, вероятно, одной из наиболее сложных частей кода приложения, особенно если у приложения достаточно развитый интерфейс пользователя. Те, кому придется модифицировать этот код через пару лет, будут благодарить разработчика за сохранение кода рисования в одном месте и за максимально возможную простоту — чего добиться гораздо легче, если код не разбросан по разными частям программы. Из этого можно сделать вывод, что хорошая практика состоит в поддержании всего кода рисования в процедуре OnPaint()или в других методах, вызываемых из этого метода. Не создавайте в коде множества других мест, которые вызывают методы для реализации странных фрагментов рисования, все-таки аспекты создания программы должны быть сбалансированы относительно различных рассмотрений. Если, предположим, требуется заменить только один символ или фигуру на экране или добавить акцент к букве и совершенно точно известно, что это не повлияет ни на какие другие изображения, то можно не пользоваться методом Invalidate(), а написать просто отдельную процедуру рисования.
Вычисление размеров объектов и размера документаМы возвращаемся теперь к примеру CapsEditorи разбираем методы CalculateLineWidths()и CalculateDocumentSize(), которые вызываются из метода LoadFile(): private void CalculateLineWidths() { Graphics dc = this.CreateGraphics(); foreach (TextLineInformation nextLine in documentLines) { nextLine.Width = (uint)dc.MeasureString(nextLine.Text, mainFont).Width; } } Этот метод просто выполняется на каждой прочитанной строке и использует метод Graphics.MeasureString()для определения и сохранения значения величины горизонтального пространства экрана, которое требуется строке. Мы сохраняем значение, так как MeasureString()является весьма интенсивным с вычислительной точки зрения. Так как в нашем примере CapsEditorне слишком легко определить высоту и положение каждого элемента, то этот метод почти наверняка будет реализован, чтобы вычислить все эти величины. Теперь, когда мы знаем размер каждого элемента на экране и можем вычислить приблизительное его положение, определим реальный размер документа. Высота, по существу, равна числу строк, умноженному на высоту каждой строки. Ширину необходимо определить просмотром всех строк, чтобы выявить самую длинную и взять ширину этой строки. Для высоты и ширины также желательно допустить небольшие поля вокруг выводимого документа, чтобы приложение выглядело более привлекательно. (Нежелательно, чтобы текст прикасался к одному из углов клиентской области.) Вот метод, который вычисляет размер документа: private void CalculateDocumentSize() { if (!documentHasData) { documentSize = new Size(100, 200); } else { documentSize.Height = (int)(nLines*lineHeight) + 2*(int)margin; uint maxLineLength = 0; foreach (TextLineInformation nextWord in documentLines) { uint tempLineLength = nextWord.Width + 2*margin; if (tempLineLength > maxLineLength) maxLineLength = tempLineLength; } documentSize.Width = (int)maxLineLength; } this.AutoScrollMinSize = documentSize; } Этот метод сначала проверяет, есть ли данные для вывода. Если данных нет, мы слегка схитрим и зададим жестко кодированный размер документа такой величины, чтобы хватило места для выведения большими красными буквами предупреждения <Empty Document>. В противном случае необходимо воспользоваться методом MeasureString()для определения реального размера документа. После этого размер документа сообщается экземпляру класса Form, задавая свойство Form.AutoScrollMinSize. Когда это сделано, за сценой происходит кое-что интересное. В процессе задания этого свойства клиентская область становится недействительной и инициируется событие Paintв связи с тем, что изменение размера документа означает необходимость добавить или изменить панели прокрутки, а также, что вся клиентская область почти наверняка будет перерисована. Это в полной мере иллюстрирует то, что было сказано ранее об использовании метода Form.Invalidate(). Если вернуться назад к коду LoadFile(), то станет понятно, что вызов метода Invalidate()в этом методе является на самом деле излишним. Клиентская область будет объявлена недействительной в любом случае, когда задается размер документа. Явный вызов метода Invalidate()в реализации метода LoadFile()оставлен для иллюстрации. Фактически в этом случае все, что будет делать вызванный метод Invalidate(), является ненужным запросом повторного события Paint. Однако это в свою очередь подтверждает, что Invalidate()дает Windows возможность оптимизировать производительность. Второе событие Paint не будет фактически инициировано: Windows увидит, что в очереди уже находится событие Paint, и сравнит запрошенные недействительные области, чтобы попробовать объединить их. В этом случае оба события Paint будут определять всю клиентскую область, поэтому ничего не нужно делать, и Windows спокойно удалит второй запрос Paint. Конечно, это действие займет какое-то процессорное время, но оно будет ничтожным по сравнению с тем, сколько времени потребуется для реального выполнения рисования. OnPaint()Итак, мы увидели, как CapsEditorзагружает файл. Теперь пришло время посмотреть, как выполняется рисование: protected override void OnPaint(PaintEventArgs e) { Graphics dc = e.Graphics; int scrollPositionX = this.AutoScrollPosition.X; int scrollPositionY = this.AutoScrollPosition.Y; dc.TranslateTransform(scrollPositionX, scrollPositionY); if (!documentHasData) { dc.DrawString("<Empty Document>", emptyDocumentFont, emptyDocumentBrush, new Point(20, 20)); base.OnPaint(e); return; } // определить, какие строки находятся в вырезанном прямоугольнике int minLineInClipRegion = WorldYCoordinateToLineIndex(е.ClipRectangle.Top - scrollPositionY); if (minLineInClipRegion == -1) minLineInClipRegion = 0; int maxLineInClipRegion = WorldYCoordinateToLineIndex(e.ClipRectangle.Bottom - scrollPositionY); if (maxLineInClipRegion >= this.documentLines.Count || maxLineInClipRegion == -1) maxLineInClipRegion = this.documentLines.Count - 1; TextLineInformation nextLine; for (int i = minLineInClipRegion; i <= maxLineInClipRegion; i++) { nextLine = (TextLineInformation)documentLines[i]; dc.DrawString(nextLine.Text, mainFont, mainBrush, this.LineIndexToWorldCoordinates(i)); } base.OnPaint(e); } В середине этой перезагружаемой версии OnPaint()находится цикл, который перебирает все строки документа, вызывая метод Graphics.DrawString()для рисования каждой из них. Остальная часть этого кода связана в основном с оптимизацией рисования — обычный материал для определения, что действительно необходимо нарисовать вместо необдуманного приказания экземпляру Graphics перерисовать все. Мы начинаем с проверки, имеются ли в документе какие-либо данные. Если данных нет, мы выводим краткое сообщение, говорящее об этом вызываем реализацию OnPaint()из базового класса и выходим. Если имеются данные, то мы начинаем проверять прямоугольник вырезания. Способ, которым это делается, состоит в вызове другого написанного нами метода WorldYCoordinateToLineIndex(). Мы рассмотрим этот метод позже, но по сути он получает заданную у-позицию относительно верха документа и определяет, какая строка документа будет выводиться в этой точке. При первом вызове метода WorldYCoordinateToLineIndex()ему передается значение координаты е.ClipRectangle.Top - scrollPositionY. Это верх области вырезания, преобразованный в мировые координаты. Если возвращаемое значение будет -1, мы предположим, что нам нужно начать с начала документа (если верх области вырезания находится наверху граничного поля). После того, как все это будет сделано, мы практически повторяем тот же процесс для низа прямоугольника вырезания, чтобы определить последнюю строку документа, которая находится внутри области вырезания. Индексы первой и последней строки хранятся соответственно в minLineInClipRegionи maxLineInClipRegion, поэтому мы можем просто выполнить цикл forмежду этими значениями, чтобы реализовать рисование. Внутри цикла рисования мы должны сделать приблизительно обратное преобразование для преобразования, выполненного методом WorldYCoordinateToLineIndex(). Задан индекс строки текста и нужно проверить, где она должна быть нарисована. Это вычисление является вполне простым, но мы поместили его в другой метод LineIndexToWorldCoordinates(), который возвращает требуемые координаты верхнего левого угла элемента. Возвращаемые координаты являются мировыми координатами, и это хорошо, так как мы уже вызвали метод TranslateTransform()на объекте Graphics, поэтому нам нужно передать ему при запросе вывода элемента мировые координаты, а не координаты страницы. Преобразования координатВ этом разделе мы рассматриваем реализацию вспомогательных методов, которые были использованы в примере CapsEditor, чтобы выполнить преобразование координат. Это методы WorldYCoordinateToLineIndex()и LineIndexToWorldCoordinates(), на которые мы ссылались в предыдущем разделе, а также некоторые другие методы. Первое. LineIndexToWorldCoordinates()получает заданный индекс строки и определяет мировые координаты верхнего левого угла строки с помощью известных ширины поля и высоты строки: private Point LineIndexToWorldCoordinates(int index) { Point TopLeftCorner = new Point((int)margin, (int)(lineHeight*index + margin)); return TopLeftCorner; } Мы также используем метод, который делает приблизительно обратное преобразование в OnPaint(). WorldYCoordinateToLineIndex()определяет индекс строки, но он принимает в расчет только вертикальную мировую координату. Это связано с тем, что метод используется для определения индекса строки, соответствующего верху и низу области вырезания: private int WorldYCoordinateToLineIndex(int у) { if (у < margin) return -1; return (int)((y - margin)/lineHeight); } Существуют еще три метода, вызываемые из процедуры обработки, которые отвечают на двойной щелчок пользователя мышью. Прежде всего — метод, определяющий индекс строки, которая выведется в заданных мировых координатах. В отличие от WorldYCoordinateToLineIndex()этот метод берет в расчет позиции x- и y- координат. Он возвращает -1, если нет строки текста с заданными координатами. private int WorldCocrdinatesToLineIndex(Point position) { if (!documentHasData) return -1; if (position.Y < margin || position.X < margin) return -1; int index = (int) (position.Y - margin) / (int) this.lineHeight; // проверить, что позиция находится не ниже документа if (index >= documentLines.Count) return -1; // теперь проверим, что горизонтальная позиция располагается // внутри строки TextLineInformation theLine = (TextLineInformation)documentLines[index]; if (position.X > margin * theLine.Width) return -1; // все хорошо. Можно вернуть ответ. return index; } Наконец, иногда необходимо делать преобразование между индексом строки и координатами страницы, а не мировыми координатами. Это делает следующий метод: private Point LineIndexToPageCoordinates(int index) { return LineIndexToWorldCoordinates(index) + new Size(AutoScrollPosition); } private int PageCoordinatesToLineIndex(Point position) { return WorldCoordinatesToLineIndex(position - new Size(AutoScrollPosition)); } Эти методы сами по себе не кажутся особенно интересными, они иллюстрируют общую технику, которую, по всей видимости, вам придется часто использовать. Применяя GDI+, мы иногда оказываемся в ситуации где заданы некоторые координаты (например, координаты места, где пользователь щелкнул мышью) и требуется определить, какой элемент изображен в этом месте. Или наоборот, для заданного определенного элемента вывода необходимо приблизительно определить, где он должен быть выведен. Следовательно, при создании приложений GDI+ может оказаться полезным умение написать методы, эквивалентные методам преобразований координат, проиллюстрированным здесь. Ответ на ввод пользователяДо сих пор, за исключением пеню File в примере CapsEditor, все, что делались в этой главе, было односторонним, так как приложение общалось с пользователем, выводя информацию на экране. Почти любое программное обеспечение работает в обоих направлениях — пользователь также может общаться с программным обеспечением. Мы собираемся теперь добавить эту возможность в CapsEditor. Заставить приложение GDI+ ответить на пользовательский ввод в действительности значительно проще, чем писать код для рисования на экране, и мы в главе 9 уже рассмотрели, как обрабатывать ввод пользователя. По сути для этого необходимо переопределить методы из класса Form, которые вызываются из соответствующего обработчика событий почти так же, как вызывается OnPaint(), когда инициируется событие Paint. Для случая обнаружения, когда пользователь щелкнул мышью или переместил мышь, функции которые можно будет переопределить включают следующие:
Если требуется определить, когда пользователь вводит с клавиатуры какой-то текст, то, вероятно, можно будет переопределить следующие методы.
Отметим, что некоторые из этих событий перекрываются. Например, нажатие пользователем кнопки мыши порождает событие MouseDown. Если кнопка немедленно снова освобождается, то это порождает событие MouseUpи событие Click. Также некоторые из этих методов получают аргумент, который выводится из аргумента EventArgsи поэтому может использоваться для предоставления дополнительных данных об определенном событии. MouseEventArgsимеет два свойства — Xи Y, которые задают координаты мыши во время нажатия кнопки. KeyEventArgsи KeyPressEventArgsимеют свойства, указывающие, какая клавиша или клавиши имеют отношение к событию. Затем разработчик должен продумать логику последующих действий. Только одно замечание. Вполне вероятно, что приложение GDI+ потребует создания большего объема логики, чем приложение Windows.Forms. Это связано с тем, что в приложении Windows.Formsприходится отвечать на высокоуровневые события (например, TextChangedдля текстового поля). При использовании GDI+ события являются более базовыми — пользователь щелкает мышью или нажимает клавишу h. Действие, которое предпринимает приложение, скорее всего зависит от последовательности событий, а не от одного события. Например, в Word for Windows, чтобы выбрать некоторый текст, пользователь обычно щелкает левой кнопкой мыши, перемещает мышь и освобождает левую кнопку мыши. Если пользователь просто нажмет, а затем освободит левую кнопку мыши, Word не выделит никакой текст, он просто переместит курсор текста в место, где был курсор мыши. Поэтому в точке, где пользователь нажимает левую кнопку мыши, нельзя еще сказать, что пользователь собирается делать. Приложение будет получать событие MouseDown, но, предположим, что требуется, чтобы приложение вело себя так же, как это делает Word for Windows. Нам ничего не остается, кроме как записать, что произошел щелчок мыши с курсором в определенной позиции. Когда будет получено событие MouseMove, вы захотите проверить в только что сделанных записях, не нажата ли в данный момент левая кнопка, и если это так, то выделить текст, поскольку пользователь его выбрал. Когда пользователь освобождает левую кнопку мыши (в методе OnMouseUp()), происходит проверка, было ли выполнено какое-либо перемещение, пока мышь была нажата, а далее нужно действовать соответственно. Только в этой точке последовательность завершается. Другой момент нашего рассмотрения связан с перекрытием некоторых событий, так как в этой ситуации возникает необходимость выбора события, на которое должен ответить код. Золотое правило состоит в тщательном продумывании логики каждой комбинации движения мыши или щелчка и события клавиатуры, которое может инициировать пользователь, а также обеспечении того, чтобы приложение отвечало способом, который интуитивно понятен и согласован с обычно ожидаемым поведением приложений в каждом случае. Большая часть работы здесь будет состоять в обдумывании, а не в кодировании, хотя кодирование потребуется достаточно кропотливое, поэтому может понадобиться принять во внимание множество комбинаций ввода пользователя. Например, что должно делать приложение, если пользователь начинает вводить текст, когда одна из кнопок мыши нажата? Это покажется невероятной комбинацией, но рано или поздно какой-то пользователь попробует так сделать. Для примера CapsEditorвсе сделано очень простым, по сути нет никаких комбинаций для рассмотрения. Необходимо ответить только на двойной щелчок пользователя мышью, и в этом случае строку текста, над которой находится курсор мыши, необходимо перевести в символы верхнего регистра. Это несложная задача, но имеется одна заминка. Необходимо перехватить событие Doubleclick, но приведенная выше таблица показывает, что это событие имеет параметр EventArgs, а не параметр MouseEventArgs. Проблема в том, что необходимо знать, где находится мышь, когда пользователь делает двойной щелчок, если требуется правильно определить строку текста, которая будет переводиться в верхний регистр, и для этого требуется параметр MouseEventArgs. Существует два способа обойти эту проблему. Один состоит в использовании статического метода Control.MousePosition, который реализован объектом Form1, чтобы найти положение мыши, как в следующем коде: protected override void OnDoubleClick(EventArgs e) { Point MouseLocation = Control.MousePosition; // обработать двойной щелчок В большинстве случаев это срабатывает. Однако могут быть сложности, если приложение (или даже некоторое другое приложение с более высоким приоритетом) выполняет некоторые интенсивные вычисления в момент двойного щелчка пользователя. В таком случае возможно, что обработчик событий OnDoubleClick()не будет вызван в течение полсекунды. Задержки такого рода вряд ли желательны, так как они начинают раздражать пользователей достаточно быстро. Половины секунды вполне достаточно для перемещения мыши на половину экрана, — и в этом случае выполнение OnDoubleClick()может произойти в совершенно другом месте. Лучший подход состоит в использовании одного из многих наложений между значениями событий мыши. Первая часть двойного щелчка мыши включает нажатие левой кнопки. Это означает, что если вызывается OnDoubleClick(), то мы знаем, что также был вызван OnMouseDown()с курсором мыши в том же месте. Можно использовать перезагружаемую версию OnMouseDown()для записи положения мыши при использовании в OnDoubleClick(). Этот подход используется в CapsEditor: protected override void OnMouseDown(MouseEventArgs e) { base.OnMouseDown(e); this.mouseDoubleClickPosition = new Point(e.X, e.Y); } Теперь посмотрим на перезагруженную версию OnDoubleClick(). Здесь придется выполнить немного больше работы: protected override void OnDoubleClick(EventArgs e) { int i = PageCoordinatesToLineIndex(this.mouseDoubleClickPosition); if (i >= 0) { TextLineInformation lineToBeChanged = (TextLineInformation) documentLines[i]; lineToBeChanged.Text = lineToBeChanged.Text.ToUpper(); Graphics dc = this.CreateGraphics(); uint newWidth = (uint)dc.MeasureString(lineToBeChanged.Text, mainFont).Width: if (newWidth > lineToBeChanged.Width) lineToBeChanged.Width = newWidth; if(newWidth+2*margin > this.documentSize.Width) { this.documentSize.Width = (int)newWidth; this.AutoScrollMinSize = this.documentSize; } Rectangle changedRectangle = new Rectangle( LineIndexToPageCoordinates(i), new Size((int)newWidth, (int)this.lineHeight)); this.Invalidate(changedRectangle); } base.OnDoubleClick(e); } Начнем работу с вызова PageCoordinatesToLineIndex()для определения, над какой строкой текста находится курсор мыши, когда пользователь делает двойной щелчок. Если этот вызов возвращает -1, то никакого текста под курсом нет, поэтому ничего делать не надо (за исключением, конечно, вызова версии OnDoubleClick()базового класса, чтобы позволить Windows выполнить обработку по умолчанию. Это никогда не надо забывать делать.). При условии, что была идентифицирована строка текста, можно воспользоваться методом string.ToUpper(), чтобы легко преобразовать ее в верхний регистр. Труднее определить, что и где необходимо перерисовать. К счастью, так как пример сделан упрощенным, существует не слишком много комбинаций. Можно предположить для начала, что преобразование в верхний регистр будет всегда либо оставляет ширину строки на экране без изменения, либо увеличивает ее. Заглавные буквы больше строчных, поэтому ширина никогда не уменьшится. Известно, что поскольку мы не переносим строки, строка текста не будет продолжена на следующей строке и не сместит текст ниже. Действие по преобразованию строки в верхний регистр не будет поэтому в действительности изменять положение ни одного из выводимых элементов. Это существенное упрощение. Затем код использует Graphics.MeasureString()для определения новой ширины текста. Здесь имеется две возможности: □ Первая: новая ширина может сделать строку самой длинной строкой, что приведет к увеличению ширины всего документа. В этом случае необходимо задать для AutoScrollMinSizeновый размер, чтобы панели прокрутки размещались правильно. □ Вторая: размер документа может не измениться. В любом случае необходимо перерисовать изображение на экране, вызывая Invalidate(). Только одна строка изменилась, поэтому нет необходимости перерисовывать весь документ. Вместо этого надо определить границы прямоугольника, который содержит только измененную строку, чтобы можно было передать этот прямоугольник в метод Invalidate()для перерисовывания только этой строки текста. Именно так делает представленный выше код. Вызов Invalidate()приведет к вызову OnPaint(), когда окончательно закончит работу обработчик события мыши. Вспомните предыдущие замечания в этой главе о трудностях в задании точки прерывания в OnPaint(). Если при выполнении примера задать точку прерывания в OnPaint()для перехвата получающегося действия рисования, то обнаружится, что параметр PaintEventArgsдля OnPaintдействительно содержит область вырезания, которая соответствует указанному прямоугольнику. И так как метод OnPaint()был перезагружен, чтобы аккуратно вычленить область вырезания, то будет перерисована только одна требуемая строка текста. ПечатьВ этой главе мы полностью сконцентрировались на рисовании на экране. Часто бывает желательно, чтобы приложение могло создать твердую копию данных. К сожалению, в книге не хватает места, чтобы рассмотреть детали этого процесса, но мы кратко рассмотрим вопросы, которые встретятся при реализации печати документа. Во многом печать схожа с выводом на экран. Предоставляется контекст устройства (экземпляр Graphics) и на этом экземпляре вызываются все обычные команды вывода. Однако имеются некоторые различия: принтеры не могут прокручиваться — они используют страницы. Необходимо убедиться, что найден разумный способ деления документа на страницы, и выводить каждую страницу по запросу. К тому же большинство пользователей ожидают, что вывод на принтер будет выглядеть очень похоже на вывод на экран. Этого очень трудно добиться при использовании координат страницы. Проблема в том, что принтеры имеют другое число точек на дюйм (dpi), чем экран. Дисплейные устройства традиционно поддерживают стандарт около 96 dpi, хотя некоторые новые мониторы имеют более высокое разрешение. Принтеры могут иметь более тысячи dpi. Это означает, например, что при рисовании фигур или выводе изображений, при задании их размеров числом пикселей они будет выглядеть на принтере слишком маленькими. Иногда та же самая проблема может влиять на шрифты текста. К счастью, GDI+ допускает в этих случаях применение координат устройства. Чтобы напечатать документы, почти наверняка придется использовать свойство Grpahics.PageUnitдля выполнения печати с помощью некоторых физических единиц измерения, таких как дюймы или миллиметры. .NET имеет большое количество классов, созданных для поддержки процесса печати. Эти классы позволяют контролировать и извлекать различные настройки принтера и находятся в основном в пространстве имен System.Drawing.Printing. Существуют также предопределенные диалоговые окна PrintDialogи PrintPreviewDialog, которые доступны в пространстве имен System.Windows.Forms. Процесс печати будет включать вызов метода Show()на экземпляре одного из этих классов после задания некоторых свойств. ЗаключениеВ этой главе было рассмотрено рисование на устройстве вывода, реализующиеся в коде приложения, а не с помощью предопределенных элементов управления или диалоговых окон. GDI+ является мощным инструментом, и базовые классы .NET могут помочь при рисовании на устройстве. Мы видели, что этот процесс является в действительности довольно простым, в большинстве случаев можно рисовать текст и сложные фигуры или выводить изображения с помощью пары инструкций C#. Однако управление рисованием — работа, происходящая неявно, включающая определение, что и где нарисовать и нужна ли перерисовка в любой данной ситуации. Это значительно более сложная задача, требующая тщательного проектирования алгоритма. Важно хорошо понимать, как работает GDI+ и какие действия предпринимает Windows для рисования. В частности, с учетом архитектуры Windows важно, чтобы рисование выполнялось с помощью объявления областей окна недействительными, где это возможно, в таком случае система Windows реагирует должным образом на событие Paint. Существует значительное количество классов .NET, связанных с рисованием, которые невозможно рассмотреть в одной главе, но, зная основные принципы, вовлеченные в рисование, можно изучить их самостоятельно. Просматривая списки их методов в документации и создавая их экземпляры, вы поймете, что они делают. В конце концов, рисование, как почти и любой другой аспект программирования, требует логики, тщательного обдумывания и четких алгоритмов. Используйте это, и вы сможете написать сложные интерфейсы пользователя, не зависящие от стандартных элементов управления. Ваша программа существенно выиграет как в удобстве для пользователя, так и в визуальном представлении. Многие приложения целиком полагаются на элементы управления в своем интерфейсе пользователя. Хотя это и может быть эффективно, такие приложения очень быстро начинают походить друг на друга. Добавляя некоторый код GDI+, чтобы выполнить специальное рисование, можно выделить свое приложение и сделать его внешне более оригинальным. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||