|
||||
|
|
Неделя №3Основные вопросыИтак, две недели изучения C++ уже позади. Сейчас вы наверняка свободно ориентируетесь в некоторых достаточно сложных аспектах объектно-ориентированного программирования, включая инкапсуляцию и полиморфизм. Что дальшеПоследняя неделя начинается с изучения дополнительных возможностей наследования. Затем на занятии 16 вы изучите потоки, а на занятии 17 познакомитесь с одним замечательным дополнением стандартов C++ — пространствами имен. Занятие 18 посвящено анализу основ объектно-ориентированного программирования. В этот день внимание будет сконцентрировано не столько на синтаксисе языка, сколько на изучении концепций объектно-ориентированного программирования. На занятии 19 вы познакомитесь с использованием шаблонов, а на занятии 20 узнаете о методах отслеживания исключительных ситуаций и ошибок. Наконец, на последнем занятии будут раскрыты некоторые хитрости и секреты программирования на C++, что сделает вас настоящим гуру в этой области. День 15-й. Дополнительные возможности наследованияДо настоящего момента вы использовали одиночное и множественное наследование для создания относительно простых связей между классами. Сегодня вы узнаете: • Что такое вложение и как его использовать • Что такое делегирование и как его использовать • Как выполнить один класс внутри другого • Как использовать закрытое наследование ВложениеАнализируя примеры, приведенные на предыдущих занятиях, вы, вероятно, заметили, что в классах допускается использование в переменных-членах объектов других классов. В этом случае программисты на C++ говорят, что внешний класс содержит внутренний. Так, класс Employee в качестве переменных-членов может содержать строковые объекты (с именем сотрудника) и объекты с целочисленными значениями (зарплатой и т.д.). В листинге 15.1 представлен незавершенный, но весьма полезный класс String. Запуск такой программы не приведет к выводу каких-либо результатов, но она потребуется при написании других программ этого занятия. Листинг 15.1. Класс string 1: #include <iostream.h> 2: #include <string.h> 3: 4: class String 5: { 6: public: 7: // конструкторы 8: String(); 9: String(const char *const); 10: String(const String &) 11: ~String(); 12: 13: // перегруженные операторы 14: char & operator[](int offset); 15: char operator[](int offset) const; 16: String operator+(const String&); 17: void operator+=(const String&); 18: String & operator= (const String &); 19: 20: // Общие методы доступа 21: int GetLen()const { return itsLen; } 22: const char * GetString() const { return itsString; } 23: // статический целочисленный счетчик ConstructorCount; 24: 25: private: 26: String (int); // закрытый конструктор 27: char * itsString; 28: unsigned short itsLen; 29: 30: }; 31: 32: // конструктор класса String пo умолчанию создает строку длиной 0 байт 33: String::String() 34: { 35: itsString = new char[1]; 36: itsString[0] = '\0'; 37: itsLen=0; 38: // cout << "\tDefault string constructor\n"; 39: // ConstructorCount++; 40: } 41: 42: // закрытый конструктор, используемый только 43: // методами клаcса для создания новой cтроки 44: // указанного размера, заполненной нулями 45: String::String(int len) 46: { 47: itsString = new ohar[len+1]; 48: for (int i = 0; i<=len; i++) 49: itsString[i] = '\0'; 50: itsLen=len; 51: // cout << "\tString(int) constructor\n"; 52: // ConstructorCount++; 53: } 54: 55: // Преобразует массив символов в cтроку 56: String::String(const char * oonst cString) 57: { 58: itsLen = strlen(cString); 59: itsString = new char[itsLen+1]; 60: for (int i = 0; i<itsLen; i++) 61: itsString[i] = cString[i]; 62: itsString[itsLen]='\0'; 63: // cout << "\tString(char*) constructor\n"; 64: // ConstructorCount++; 65: } 66: 67: // конструктор-копировщик 68: String::String (const String & rhs) 69: { 70: itsLen=rhs.GetLen(); 71: itsString = new char[itsLen+1]; 72: for (int i = 0; i<itsLen;i++) 73: itsString[i] = rhs[i]; 74: itsString[itsLen] = '\0'; 75: // cout << "\tString(String&) constructor\n 76: // ConstructorCount++; 77: } 78: 79: // деструктор освобождает занятую память 80: String::~String () 81: { 82: delete [] itsString; 83: itsLen = 0; 84: // cout << "\tString destructor\n"; 85: } 86: 87: // этот оператор освобождает память, а затем 88: // копирует строку и размер 89: String& String::operator=(const String & rhs) 90: { 91: if (this == &rhs) 92: return *this; 93: delete [] itsString; 94: itsLen=rhs.GetLen(); 95: itsString = new char[itsLen+1]; 96: for (int i = 0; i<itsLen;i++) 97: itsString[i] = rhs[i]; 98: itsString[itsLen] = '\0'; 99: return *this; 100: // cout << "\tString operator=\n"; 101: } 102: 103: // неконстантный оператор индексирования, 104: // возвращает ссылку на символ, который можно 105: // изменить 106: char & String::operator[](int offset) 107: { 108: if (offset > itsLen) 109: return itsString[itsLen-1]; 110: else 111: return itsStnng[offset]; 112: } 113: 114: // константный оператор индексирования, 115: // используется для константных объектов (см. конструктор-копировщик!) 116: char String::operator[](int offset) const 117: { 118: if (offset > itsLen) 119: return itsString[itsLen-1]; 120: else 121: return itsString[offset]; 122: } 123: 124: // создает новую строку, добавляя текущую 125: // строку к rhs 126: String String::operator+(const String& rhs) 127: { 128: int totalLen = itsLen + rhs.GetLen(); 129: String temp(totalLen); 130: int i, j; 131: for (i = 0; i<itsLen; i++) 132: temp[i] = itsString[i]; 133: for (j = 0: j<rhs.GetLen(); j++, i++) 134: temp[i] = rhs[j]; 135: temp[totalLen]='\0'; 136: return temp; 137: } 138: 139: // изменяет текущую строку, ничего не возвращая 140: void String::operator+=(const String& rhs) 141: { 142: unsigned short rhsLen = rhs.GetLen(); 143: unsigned short totalLen = itsLen + rhsLen; 144: String temp(totalLen); 145: int i, j; 146: for (i = 0; i<itsLen; i++) 147: temp[i] = itsString[i]; 148: for (j = 0; j<rhs.GetLen(); j++, i++) 149: temp[i] = rhs[i-itsLen]; 150: temp[totalLen]='\0'; 151: *this = temp; 152: } 153: 154: // int String::ConstructorCount = 0; Результат: Нет Анализ: Представленный в листинге 15.1 класс String напоминает другой класс, использованный в листинге 12.12. Однако есть одно важное отличие между этими двумя классами: конструкторы и некоторые функции листинга 12.12 включали операторы вывода на печать, благодаря которым на экране отображались сообщения об их использовании. В листинге 15.1 эти операторы временно заблокированы, но они будут использоваться в следующих примерах. Статическая переменная-член ConstructorCount объявляется и инициализируется соответственно в строках 23 и 154. Значение этой переменной увеличивается на единицу при вызове любого конструктора класса String. Эти функции также заблокированы и будут использоваться в следующих листингах. В листинге 15.2 объявляется класс Employee, содержащий три объекта класса String. Листинг 15.2. Класс Employee 1: #include "String.hpp" 2: 3: class Employee 4: { 5: 6: public: 7: Employee(); 8: Employee(char *, char *, char >>, long); 9: ~Employee(); 10: Employee(const Employee&); 11: Employee & operator= (const Employee &); 12: 13: const String & GetFirstName() const 14: { return itsFirstName; } 15: const String & GetLastName() const { return itsLastName; } 16: const String & GetAddress() const { return itsAddress; } 17: long GetSalary() const { return itsSalary; } 18; 19: void SetFirstName(const String & fNama) 20: { itsFirstName = fName; } 21: void SetLastName(const String & lNama) 22: { itsLastName = lNamo; } 23: void SetAddress(const String & address) 24: { itsAddress = address; } 25: void SetSalary(long salary) { itsSalary = salary; } 26: private: 27: String itsFirstName; 28: String itsLastName; 29: String itsAddress; 30: long itsSalary; 31: }; 32: 33: Employee::Employee(); 34: itsFirstName(""), 35: itsLastName(""), 36: itsAddress(""), 37: itsSalary(0) 38: { } 39: 40: Employee::Employee(char * firstName, char * lastName, 41: char * address, long salary): 42: itsFirstName(firstName), 43: itsLastName(lastName), 44: itsAddress(address), 45: itsSalary(salary) 46: { } 47: 48: Employee::Employee(const Employee & rhs): 49: itsFirstName(rhs.GetFirstName()), 50: itsLastName(rhs,GetLastName()), 51: itsAddress(rhs,GetAddress()), 52: itsSalary(rhs.GetSalary()) 53: { } 54: 55: Employee::~Employea() { } 56: 57: Employee & Employae::Qperator= (const Employee & rhs) 58: { 59: if (thls — &rhs) 60: return *this; 61: 62: itsFlrstName = rhs.GetFlrstName(); 63: itsLastName = rhs,GetLastName(); 64: itsAddress = rhs,GetAddress(); 65: itsSalary = rhs,GetSalary(); 66: 67: return *thls; 68: } 69: 70: int main() 71: { 72: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000); 73: Edie.SetSalary(50000); 74: String LastName("Levine"); 75: Edie.SetLastName(LastName); 76: Edie.SetFirstName("Edythe"); 77: 78: cout << "Имя: "; 79: cout << Edie.GetFirstName().GetString(); 80: cout << " " << Edie.GetLastName().GetString(); 81: cout << ".\nАдрес: "; 82: cout << Edie.GetAddress().GetString(); 83: cout << ".\nЗарплата: " ; 84: cout << Edie.GetSalary(); 85: return 0; 86: } Примечание:Сохраните листинг 15.1 в файле с именем string. hpp. Затем всякий раз, когда понадобится класс String, вы сможете вставить листинг 15.1, просто добавив строку #include "String.hpp". Это первая строка в листинге 15.2. Результат: Name: Edythe Levine. Address: 1461 Shore Parkway. Salary: 50000 Анализ: В листинге 15.2 объявляется класс Employee, переменными-членами которого выступают три объекта класса String — itsFirstName, itsLastName и itsAddress. В строке 72 создается объект Employee, который инициализируется четырьмя значениями. В строке 73 вызывается метод доступа SetSalary класса Employee, который принимает константное значение 50000. В реальной программе это значение определялось бы либо динамически в процессе выполнения программы, либо устанавливалось бы константой. В строке 74 создается и инициализируется строковой константой объект класса String, который в строке 75 используется в качестве аргумента функции SetLastName(). В строке 76 вызывается метод SetFirstName класса Employee с еще одной строковой константой в качестве параметра. Однако если вы обратитесь к объявлению класса Employee, то увидите, что в нем нет функции SetFirstName(), принимающей строку символов как аргумент. Для функции SetFirstName() в качестве параметра задана константная ссылка на объект String. Тем не менее компилятор не покажет сообщения об ошибке, поскольку в строке 9 листинга 15.1 объявлен конструктор, создающий объект String из строковой константы. Доступ к членам вложенного классаВ классе Employee не объявлены специальные методы доступа к переменным- членам класса String. Если объект Edie класса Employee попытается напрямую обратиться к переменной-члену itsLen, содержащейся в ero собственной переменной- члене itsFirstName, это приведет к возникновению ошибки компиляции. Однако в таком обращении нет необходимости. Методы доступа класса Employee просто создают интерфейс для класса String, и классу Employee нет нужды беспокоиться о деталях выполнения класса String, а также о том, каким образом собственная целочисленная переменная-член itsSalary хранит свое значение. Фильтрация доступа к вложенным классамВы, наверное, уже заметили, что в классе String перегружается operator+. В классе Employee доступ к перегруженной функции operator+ заблокирован. Дело в том, что в объявлениях методов доступа класса Employee указано, что все эти методы, такие как GetFirstName(), возвращают константные ссылки. Поскольку функция operator+ не является (и не может быть) константой (она изменяет объект, для которого вызывается), попытка написать следующую строку приведет к сообщению об ошибке компиляции: String buffer = Edie.GetFirstName() + Edie.GetLastName(); Функция GetFirstName() возвращает константную строку и вы не можете использовать operator+ с константным объектом. Чтобы устранить эту проблему, следует перегрузить функцию GetFirstName() таким образом, чтобы она стала не константной: const String & GetFirstName() const { return itsFirstName; } String & GetFirstName() { return itsFirstName; } Как видите, возвращаемое значение больше не является константой, также как и сама функция-член. Изменения возвращаемого значения недостаточно для перегрузки имени функции. Необходимо изменить константность самой функции. Цена вложенийВажно отметить, что пользователю придется "расплачиваться" за каждый объект внешнего класса всякий раз при создании или копировании объекта Employee. Снимите символы комментариев с операторов cout листинга 15.1 (строки 38, 51, 63, 75, 84 и 100), и вы увидите, как часто они вызываются. В листинге 15.3 представлена та же программа, что и в листинге 15.2, только в этом примере добавлены операторы печати, которые будут показывать сообщения на экране всякий раз при выполнении конструктора класса Employee. Это позволит наглядно увидеть весь процесс создания объектов в программе. Примечание:До компиляции этого листинга разблокируйте строки 38, 51, 63, 75, 84 и 100 в листинге 15.1. Листинг 15.3. Конструкторы вложенных классов 1: #include "String.hpp" 2: 3: class Employee 4: { 5: 6: public: 7: Employee(); 8: Employee(char *, char *, char *, long); 9: ~Employee(); 10: Employee(const Employee&); 11: Employee & operator= (const Employee &); 12: 13: const String & GetFirstName() const 14: { return itsFirstName; } 15: const String & GetLastName() const { return itsLastName; } 16: const String & GetAddress() const { return itsAddress; } 17: long GetSalary() const { return itsSalary; } 18: 19: void SetFirstName(const String & fName) 20: { itsFirstName = fName; } 21: void SetLastName(const String & lName) 22: { itsLastName = lName; } 23: void SetAddress(const String & address) 24: { itsAddress = address; } 25: void SetSalary(long salary) { itsSalary = salary; } 26: private: 27: String itsFirstName; 28: String itsLastName; 29: String itsAddress; 30: long itsSalary; 31: }; 32: 33: Employee::Employee(); 34: itsFirstName(""), 35: itsLastName(""), 36: itsAddress(""), 37: itsSalary(0) 38: { } 39: 40: Employee::Employee(char * firstName, char * lastName, 41: char * address, long salary): 42: itsFirstName(firstName), 43: itsLastName(lastName), 44: itsAddrsss(address), 45: itsSalary(salary) 46: { } 47: 48: Employee:;Employee(const Employee & rhs): 49: itsFirstName(rhs,GetFirstName()), 50: itsLastName(rhs,GetLastName()), 51: itsAddress(rhs.GetAddress()), 52: itsSalary(rhs.GetSalary()) 53: { } 54: 55: Employee::~Employee() { } 56: 57: Employee & Employee::operator= (const Employee & rhs) 58: { 59: if (this == &rhs) 60: return *this; 61: 62: itsFirstName = rhs.GetFirstName(); 63: itsLastName = rhs.GetLastName(); 64: itsAddress = rhs.GetAddress(); 65: itsSalary = rhs.GetSalary(); 66: 67: return *this; 68: } 69: 70: int main() 71: { 72: cout << "Creating Edie...\n"; 73: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000); 74: Edie,SetSalary(20000); 75: cout << "Calling SetFirstName with char *...\n"; 76: Edie,SetFirstName("Edythe"); 77: cout << "Creating temporary string LastName...\n"; 78: String LastName("Levine"); 79: Edis,SetLastName(LastName); 80: 81: cout << "Name: "; 82: cout << Edle.QetFirstName().GetString(); 83: cout << " " << Edie,GstLastName().GitString(); 84: cout << "\nAddress; "; 85: cout << Edi6.GetAddress(),GetString(); 86: cout << "\nSalary; " ; 87: cout << Edie.GstSalary(); 88: cout << endl; 89: return 0; 90: } Результат: Creating Edie... String(char*) constructor String(char*) constructor String(char*) constructor Calling SetFirstName with char *... String(char*) constructor String destructor Creating temporary string LastName... String(char*) constructor Name: Edythe Levine Address: 1461 Shore Parkway Salary: 20000 String destructor String destructor String destructor String destructor Анализ: В листинге 15.3 используются классы, объявленные ранее в листингах 15.1 и 15.2. Единственное отличие состоит в том, что операторы cout разблокированы. Чтобы упростить обсуждение, строки, выводимые программой на экран, были пронумерованы. В строке 72 листинга 15.3 выводится сообщение Creating Edie..., которому соответствует первая строка вывода. Для создания объекта Edie класса Employee задаются четыре параметра. Для инициализации трех из них задействуются конструкторы класса String, о чем свидетельствуют три следующие строки вывода. Строка 75 информирует о вызове функции SetFirstName. Следующая строка программы, Edie.SetFirstName("Edythe"), создает временный объект класса String из строковой константы "Edythe", для чего вновь задействуются соответствующие конструкторы класса String (см. 6-ю строку вывода). Обратите внимание, что этот временный объект уничтожается сразу же после присвоения его значения переменной-члену, о чем свидетельствует вызов деструктора класса String (см. 7-ю строку вывода). Присвоив имя, программа приступает к присвоению фамилии служащего. Это можно было бы выполнить так же, как и в случае с присвоением имени с помощью автоматически создаваемого временного объекта класса String. Но чтобы показать все возможности, в строке 78 явно создается объект класса String. Конструктор, создающий этот объект, дал о себе знать 9-й строкой вывода. Деструктор не вызывается, поскольку этот объект не удаляется до тех пор, пока не выйдет за границы своей области видимости в конце функции. Наконец программа выводит на экран персональные сведения о служащем и выходит за область видимости объекта Employee, в результате чего вызываются четыре деструктора класса для удаления объектов этого класса, вложенных в объект Employee, и созданного ранее временного объекта LastName. Передача объекта как значенияВ листинге 15.3 показано, как создание одного объекта Employee приводит к вызову пяти конструкторов класса String. Листинг 15.4 — это еще один переписанный вариант программы. В нем нет дополнительных операторов вывода помимо представленных в листинге 15.1 (сейчас они разблокированы) и используется статическая переменная-член ConstructorCount, объявленная в классе String. Как следует из объявления в листинге 15.1, значение переменной ConstructorCount увеличивается на единицу при каждом вызове конструктора класса String. В конце программы, представленной в листинге 15.4, объект Employee передается на печать сначала как ссылка, а затем как значение. Статическая переменная-член ConstructorCount отслеживает, сколько объектов класса String создается при разных способах передачи объекта Employee как параметра функции. Примечание:Перед компиляцией этого листинга в программе листинга 15.1 дополнительно к тем строкам, которые были разблокированы для листинга 15.3, следует снять символы комментариев со строк 23, 39, 52, 64, 76 и 153. Листинг 15.4. Передача объекта как значения 1: #include "String.hpp" 2: 3: class Employee 4: { 5: 6: public: 7: Employee(); 8: Employee(char *, char *, char *, long); 9: ~Employee(); 10: Employee(const Employee&); 11: Employee & operator= (const Employee &); 12: 13: const String & GetFirstName() const 14: { return itsFirstName; } 15: const String & GetLastName() const { return itsLastName; } 16: const String & GetAddress() const { return itsAddress; 17: long GetSalary() const { return itsSalary; } 18: 19: void SetFirstName(const String & fName) 20: { itsFirstName = fName; } 21: void SetLastName(const String & lName) 22: { itsLastName = lName; } 23: void SetAddress(const String & address) 24: { itsAddress = address; } 25: void SetSalary(long salary) { itsSalary = salary; } 26: private: 27: String itsFirstName; 28: String itsLastName; 29: String itsAddress; 30: long itsSalary; 31: }; 32: 33: Employee::Employee(); 34: itsFirstName(""), 35: itsLastName(""), 36: itsAddress(""), 37: itsSalary(0) 38: { } 39: 40: Employee::Employee(char * firstName, char * lastName, 41: char * address, long salary): 42: itsFirstName(firstName), 43: itsLastName(lastName), 44: itsAddress(address), 45: itsSalary(salary) 46: { } 47: 48: Employee::Employee(const Employee & rhs): 49: itsFirstName(rhs.GetFi rstName()), 50: itsLastName(rhs.GetLastName()), 51: itsAddress(rhs.GetAddress()), 52: itsSalary(rhs.GetSalary()) 53: { } 54: 55: Employee::~Employee() { } 56: 57: Employee & Employee::operator= (const Employee & rhs) 58: { 59: if (this == &rhs) 60: return *this; 61: 62: itsFirstName = rhs.GetFirstName(); 63: itsLastName = rhs.GetLastName(); 64: itsAddress = rhs.GetAddress(); 65: itsSalary = rhs.GetSalary(); 66: 67: return *this; 68: } 69: 70: void PrintFunc(Employee); 71: void rPrintFuno(const Employee&): 72: 73: int main() 74: { 75: Employee Edie("Jane","Doe","1461 Shore Parkway", 20000); 76: Edie.SetSalary(20000); 77: Edie.SetFirstName("Edythe"); 78: String LastName("Levine"); 79: Edie.SetLastName(LastName); 80: 81: cout << "Constructor count: " ; 82: cout << String;:ConstruotorCount << endl; 83: rPrintFunc(Edie); 84: cout << "Constructor count: "; 85: cout << String::ConstructorCount << endl; 86: PrintFunc(Edie); 87: cout << "Constructor count: "; 88: cout << String::ConstructorCount << endl; 89: return 0; 90: } 91: void PrintFunc (Employee Edie) 92: { 93: 94: cout << "Name: "; 95: cout << Edie.GetFirstName().GetString(); 96: cout << " " << Edie.GetLastName().GetString(); 97: cout << ".\nAddress: "; 98: cout << Edie.GetAddress().GetString(); 99: cout << ".\nSalary: " ; 100: cout << Edie.GetSalary(); 101: cout << endl; 102: 103: } 104: 105: void rPrintFunc (const Employee& Edie) 106: { 107: cout << "Name: "; 108: cout << Edie.GetFirstName().GetString(); 109: cout << " " << Edie.GetLastName().GetString(); 110: cout << "\nAddress: "; 111: cout << Edie.GetAddress().GetString(); 112: cout << "\nSalary: " ; 113: cout << Edie.GetSalary(); 114: cout << endl; 115: } Результат: String(char*) constructor String(char*) constructor String(char*) constructor String(char*) constructor String destructor String(char*) constructor Constructor count: 5 Name: Edythe Levine Address: 1461 Shore Parkway Salary: 20000 Constructor count; 5 String(String&) constructor String(String&) constructor String(String&) constructor Name: Edythe Levine Address: 1461 Shore Parkway Salary: 20000 String destructor String destructor String destructor Constructor count: 8 String destructor String destructor String destructor String destructor Анализ: Как видно по данным, выводимым программой, в процессе создания одного объекта Employee создается пять объектов класса String. Когда объект Employee передается в функцию rPrintFunc() как ссылка, дополнительные объекты Employee не создаются. Соответственно не создаются и дополнительные объекты String. (Все они, кстати, также автоматически передаются как ссылки.) Когда объект Employee передается в функцию PrintFunc() как значение, создается копия объекта Employee вместе с тремя объектами класса String (для этого используется конструктор-копировщик). Различные пути передачи функциональности классуВ некоторых случаях одному классу необходимо передать некоторые свойства другого. Предположим, например, что вам необходимо создать класс каталога деталей PartsCatalog. На основе класса PartsCatalog предполагается создать коллекцию объектов, представляющую различные запчасти с уникальными номерами. В базе данных на основе класса PartsCatalog запрещается дублирование объектов, а для доступа к объекту необходимо указать его идентификационный номер. Ранее, в обзоре за вторую неделю, уже был объявлен и детально проанализирован класс PartsList. Чтобы не начинать работу с нуля, можно взять этот класс за основу при объявлении класса PartsCatalog. Для этого можно вложить класс PartsList в класс PartsCatalog, чтобы затем делегировать классу PartsCatalog ответственность за поддержание связанного списка в класс PartsList. Существует альтернативный путь. Можно произвести класс PartsCatalog от класса PartsList, таким образом унаследовав все свойства последнего. Помните однако, что открытое наследование (со спецификатором public) предполагает логическую принадлежность производного класса более общему базовому классу. Действительно ли в нашем случае класс PartsCatalog является частным проявлением класса PartList? Чтобы разобраться в этом, попробуйте ответить на ряд вопросов. 1. Содержит ли базовый класс PartsList методы, не применимые в классе PartsCatalog? Если да, то, вероятно, от открытого наследования лучше отказаться. 2. Будет ли один объект класса PartsCatalog соответствовать одному объекту класса PartsList? Если для создания объекта требуется не менее двух объектов PartsList, то, безусловно, необходимо применять вложение. 3. Обеспечит ли наследование от базового класса преимущества в работе благодаря использованию виртуальных функций или методов доступа к защищенным членам базового класса? В случае положительного ответа имеет смысл воспользоваться открытым или закрытым наследованием. Ответив на приведенные выше вопросы, вы должны принять решение, использовать ли вам в программе открытое наследование, закрытое наследование (см. далее в этом занятии) или вложение. Познакомимся с некоторыми терминами, которые потребуются нам при дальнейшем обсуждении этой темы. • Вложение — объект, относящийся к другому классу, используется в текущий класс. • Делегирование — передача ответственности за выполнение специальных функций вложенному классу. • Выполнение средствами класса — реализация специальных функций в классе за счет другого класса без использования открытого наследования. ДелегированиеПочему же класс PartsCatalog нельзя произвести от PartsList? Дело в том, что класс PartsCatalog должен обладать совершенно иными свойствами и ero невозможно представить как частную реализацию класса PartsList. Посмотрите, класс PartsList — это коллекция объектов, упорядоченная по возрастанию номеров, элементы которой могут повторяться. Класс PartsCatalog представляет неупорядоченную коллекцию уникальных объектов. Конечно, при желании можно произвести класс PartsList от класса PartsList со спецификатором public, после чего соответствующим образом заместить функцию Insert() и оператор индексирования ([]). Однако такие действия крайне нелогичны и противоречат самой сути наследования. Вместо этого следует создать новый класс PartsCatalog, в котором нет оператора индексирования, не разрешается дублирование записей и перегружается operator+ для суммирования наборов записей. Функцию управления связанным списком оставим классу PartsList. Попробуем сначала решить эту задачу путем вложения одного класса в другой с делегированием ответственности от класса классу, как показано в листинге 15.5. Листинг 15.5. Делегирование ответственности классу PartsList, включенному в класс PartsCatalog 1: #include <iostream.h> 2: 3: // **************** Класс Part ************ 4: 5: // Абстрактный базовый класс всех деталей 6: class Part 7: { 8: public: 9: Part():itsPartNumber(1) { } 10: Part(int PartNumber): 11: itsPartNumber(PartNumber){ } 12: virtual ~Part(){ } 13: int GetPartNumber() const 14: { return itsPartNumber; } 15: virtual void Display() const =0; 16: private: 17: int itsPartNumber; 18: }; 19: 20: // выполнение чистой виртуальной функции в 21: // стандартном виде для всех производных классов 22: void Part::Display() const 23: { 24: cout << "\nPart Number: " << itsPartNumber << endl; 25: } 26: 27: // ************ Автомобильные детали ********** 28: 29: class CarPart : public Part 30: { 31: public: 32: CarPart():itsModelYear(94){ } 33: CarPart(int year, int partNumber); 34: virtual void Display() const 35: { 36: Part::Display(); 37: cout << "Model Year: "; 38: cout << itsModelYear << endl; 39: } 40: private: 41: int itsModelYear; 42: }; 43: 44: CarPart::CarPart(int year, int partNumber): 45: itsModelYear(year), 46: Part(partNumber) 47: { } 48: 49: 50: // ************* Авиационные детали ************ 51: 52: class AirPlanePart : public Part 53: { 54: public: 55: AirPlanePart():itsEngineNumber(1){ } 56: AirPlanePart 57: (int EngineNumber, int PartNumber) 58: virtual void Dlsplay() const 59: { 60: Part::Display(); 61: cout << " Engine No.: "; 62: cout << itsEngineNumber << endl; 63: } 64: private: 65: int itsEngineNumber; 66: }; 67: 68: AirPlanePart::AirPlanePart 69: (int EngineNumber, int PartNumber): 70: itsEngineNumber(EngineNumber), 71: Part(PartNumber) 72: { } 73: 74: // *************** Узлы списка деталей ********** 75: class PartNode 76: { 77: public: 78: PartNode (Part*); 79: ~PartNode(); 80: void SetNext(PartNode * node) 81: { itsNext = node; } 82: PartNode * GetNext() const; 83: Part * GetPart() const; 84: private: 85: Part *itsPart; 86: PartNode * itsNext; 87: }; 88: // Выполнение PartNode... 89: 90: PartNode::PartNode(Part* pPart): 91: itsPart(pPart), 92: itsNext(0) 93: { } 94: 95: PartNode::~PartNode() 96: { 97: delete itsPart; 98: itsPart = 0; 99: delete itsNext; 100: itsNext = 0; 101: } 102: 103: // Возвращается NULL, если нет следующего узла PartNode 104: PartNode * PartNode::GetNext() const 105: { 106: return itsNext; 107: } 108: 109: Part * PartNode::GetPart() const 110: { 111: if (itsPart) 112: return itsPart; 113: else 114: return NULL; //ошибка 115: } 116: 117: 118: 119: // **************** Список деталей *********** 120: class PartsList 121: { 122: public: 123: PartsList(); 124: ~PartsList(); 125: // необходимо, чтобы конструктор-копировщик и оператор соответствовали друг другу! 126: void Iterate(void (Part::*f)()const) const; 127: Part* Find(int & position, int PartNumber) const; 128: Part* GetFirst() const; 129: void Insert(Part *); 130: Part* operator[](int) const; 131: int GetCount() const { return itsCount;} 132: static PartsList& GetGlobalPartsList() 133: { 134: return GiobalPartsList; 135: } 136: private: 137: PartNode * pHead; 138: int itsCount; 139: static PartsList GiobalPartsList; 140: }; 141: 142: PartsList PartsList::GlobalPartsList; 143: 144: 145: PartsList::PartsList(): 146: pHead(0), 147: itsCount(0) 148: { } 149: 150: PartsList::~PartsList() 151: { 152: delete pHead; 153: } 154: 155: Part* PartsList::GetFirst() const 156: { 157: if (pHead) 158: return pHead->GetPart(); 159: else 160: return NULL; // ловушка ошибок 161: } 162: 163: Part * PartsList::operator[](int offSet) const 164: { 165: PartNode* pNode = pHead; 166: 167: if (!pHead) 168: return NULL; // ловушка ошибок 169: 170: if (offSet > itsCount) 171: return NULL; // ошибка 172: 173: for (int i=0;i<offSet; i++) 174: pNode = pNode->GetNext(); 175: 176: return pNode->GetPart(); 177: } 178: 179: Part* PartsList::Find( 180: int & position, 181: int PartNumber) const 182: { 183: PartNode * pNode = 0; 184: for (pNode = pHead, position = 0; 185: pNode!=NULL; 186: pNode = pNode->GetNext(), position++) 187: { 188: if (pNode->GetPart()->GetPartNumber()== PartNumber) 189: break; 190: } 191: if (pNode == NULL) 192: return NULL; 193: else 194: return pNode->GetPart(); 195: } 196: 197: void PartsList::Iterate(void (Part::*func)()const) const 198: { 199: if (!pHead) 200: return; 201: PartNode* pNode = pHead; 202: do 203: (pNode->GetPart()->*func)(); 204: while (pNode = pNode->GetNext()); 205: } 206: 207: void PartsList::Insert(Part* pPart) 208: { 209: PartNode * pNode = new PartNode(pPart); 210: PartNode * pCurrent - pHead; 211: PartNode * pNext = 0; 212: 213: int New = pPart->GetPartNumber(); 214: int Next = 0; 215: itsCount++; 216: 217: if (!pHead) 218: { 219: pHead = pNode; 220: return; 221: } 222: 223: // если это значение меньше головного узла, 224: // то текущий узел становится головным 225: if (pHead->GetPart()->GetPartNumber()->New) 226: { 227: pNode->SetNext(pHead); 228: pHead = pNode; 229: return; 230: } 231: 232: for (;;) 233: { 234: // если нет следующего, вставляется текущий 235: if (!pCurrent->GetNext()) 236: { 237: pCurrent->SetNext(pNode); 238: return; 239: } 240: 241: // если текущий больше предыдущего, но меньше следующего, то вставляем 242: // здесь. Иначе присваиваем значение указателя Next 243: pNext = pCurrent->GetNext(); 244: Next = pNext->GetPart()->GetPartNumber(); 245: if (Next > New) 246: { 247: pCurrent->SetNext(pNode); 248: pNode->SetNext(pNext); 249: return; 250: } 251: pCurrent = pNext; 252: } 253: } 254: 255: 256: 257: class PartsCatalog 258: { 259: public: 260: void Insert(Part *); 261: int Exists(int PartNumber); 262: Part * Get(int PartNumber); 263: operator+(const PartsCatalog &); 264: void ShowAll() { thePartsList.Iterate(Part::Display); } 265: private: 266: PartsList thePartsList; 267: }; 268: 269: void PartsCatalog::Insert(Part * newPart) 270: { 271: int partNumber = newPart->GetPartNumber(); 272: int offset; 273: 274: if (!thePartsList,Find(offset, partNumber)) 275: 276: thePartsList.Insert(newPart); 277: else 278: { 279: cout << partNumber << " был "; 280: switch (offset) 281: { 282: case 0: cout << "first "; break; 283: case 1: cout << "second "; break; 284: case 2: cout << "third "; break; 285: default; cout << offset+1 << "th "; 286: } 287: cout << "entry. Rejected!\n"; 288: } 289: } 290: 291: int PartsCatalog::Exists(int PartNumber) 292: { 293: int offset; 294: thePartsList.Find(offset,PartNumber); 295: return offset; 296: } 297: 298: Part * PartsCatalog::Get(int PartNumber) 299: { 300: int offset; 301: Part * thePart = thePartsList.Find(offset, PartNumber); 302: return thePart; 303: } 304: 305: 306: int main() 307: { 308: PartsCatalog pc; 309: Part * pPart = 0; 310: int PartNumber; 311: int value; 312: int choice; 313: 314: while (1) 315: { 316: cout << "(0)Quit (1)Car (2)Plane: "; 317: cin >> choice; 318: 319: if (!choice) 320: break; 321: 322: cout << "New PartNumber?: "; 323: cin >> PartNumber; 324: 325: if (choice == 1) 326: { 327: cout << "Model Year?: "; 328: cin >> value; 329: pPart = new CarPart(value,PartNumber); 330: } 331: else 332: { 333: cout << "Engine Number?: "; 334: cin >> value; 335: pPart = new AirPlanePart(value,PartNumber); 335: } 337: pc.Insart(pPart); 338: } 339: pc.ShowAli(); 340: return 0; 341: } Результат: (0)Qult (1)Car (2)Plane: 1 New PartNumber?: 1234 Model Year?: 94 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 4434 Model Year?: 93 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 1234 Model Year?: 94 1234 was the first entry. Rejected! (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 2345 Model Year?: 93 (0)Quit (1)Car (2)Plane: 0 Part Number: 1234 Model Year: 94 Part Number: 2345 Model Year: 93 Part Number: 4434 Model Year: 93 Примечание:Некоторые компиляторы не смогут откомпилировать строку 264, хотя она вполне соответствует стандартам C++. Если ваш компилятор возразит против записи этой строки, замените ее строкой 264: void ShowAll() { thePartsList.Iterate(&Part::Display): } (Обратите внимание на добавление амперсанта (знак &) перед Part:Display.) Если это сработает, свяжитесь с фирмой, поставившей вам этот компилятор, и поинтересуйтесь, где они его "откопали". Анализ: В листинге 15.5 используются классы Part, PartNode и PartsList, с которыми вы уже познакомились при подведении итогов второй недели. Новый класс PartsCatalog объявляется в строках 257—267. Он использует PartsList как свою переменную-член, которой делегирует управление списком. Другими словами, класс PartsCatalog выполняется средствами классе PartsList. Обратите внимание, что клиенты класса PartsCatalog не имеет прямого доступа к классу PartsList. Интерфейс класса PartsList реализуется методами класса PartsCatalog, что существенно изменяет его поведение. Например, метод PartsCatalog::Insert() не позволяет дублировать данные, вводимые в PartsList. Определение выполнения функции PartsCatalog: :Insert() начинается в строке 269. У объекта Part, передаваемого как параметр, запрашивается значение его переменной- члена itsPartNumber. Это значение передается методу Find() класса PartsList, и объект добавляется в список, если только в списке не найден другой объект с таким же номером. В противном случае возвращается сообщение об ошибке. Обратите внимание, что в методе Insert() класса PartCatolog используется переменная-член этого класса thePartList, являющаяся объектом класса PartList. Процедура поддержания связного списка и добавления объектов в него, а также поиска и возвращения данных из списка полностью реализуется вложенным классом PartsList, объект которого является переменной-членом класса PartsCatalog. Вместо того чтобы повторять все процедуры обработки записей списка в классе PartsCatalog, методами этого класса просто создается удобный интерфейс для уже существующего класса PartsList. Именно в этом и состоит суть модульности программирования на C++. Удачно созданный однажды модуль, такой как PartsLists, можно многократно использовать в других программах, например с классом PartsCatalog. При этом разработчиков нового класса PartsCatalog могут совершенно не интересовать детали выполнения модуля PartsList. Интерфейс класса PartsList (в данном случае под интерфейсом понимается его объявление) предоставляет всю информацию, необходимую разработчику нового класса PartsCatalog. Закрытое наследованиеЕсли бы для PartsCatalog был необходим доступ к защищенным членам PartsList (в данном примере таковых нет) или в PartsCatalog использовались замещенные методы PartsList, то его можно было бы просто унаследовать от PartsList. Однако, поскольку PartsCatalog не является объектом PartsList и нежелательно предоставлять весь набор функциональных возможностей PartsList клиентам PartsCatalof, следует применить закрытое наследование. Первое, что необходимо знать: при закрытом наследовании все переменные и функции-члены базового класса трактуются так, как если бы они были объявлены закрытыми, независимо от установок доступа в базовом классе. Таким образом, для любой функции, не являющейся функцией-членом PartsCatalog, недоступны функции, унаследованные из PartsList. Это очень важно: закрытое наследование не передает в производный класс интерфейс базового класса. Класс PartsList невидим для клиентов класса PartsCatalog. Поэтому последним недоступен интерфейс класса PartsList и они не могут вызывать его методы. Однако пользователям будут доступны все методы класса PartsCatalog, имеющие доступ ко всем членам класса PartsList, так как класс PartsCatalog является производным от PartList. Важно также то, что объекты PartsCatalog не являются объектами PartsList, как было бы при использовании открытого наследования. Класс PartsCatalog выполняется методами класса PartsList, как в случае с вложением. Применение закрытого наследования не менее удобно. Использование закрытого наследования показано в листинге 15.6. Класс PartsCatalog производится как private от класса PartsList. Листинг 15.6. Закрытое наследование 1: // Листинг 15.6. Закрытое наследование 2: #include <iostream.h> 3: 4: //****************Класс Part ************ 5: 6: // Абстрактный базовый класс всех деталей 7: class Part 8: { 9: public: 10: Part():itsPartNumber(1) { } 11: Part(int PartNumber): 12: itsPartNumber(PartNumber){ } 13: virtual ~Part(){ } 14: int GetPartNumber() const 15: { return itsPartNumber; } 16: virtual void Display() const =0; 17: private: 18: int itsPartNumber; 19: }; 20: 21: // выполнение чистой виртуальной функции в 22: // стандартном виде для всех производных классов 23: void Part::Display() const 24: { 25: cout << "\nPart Number: " << itsPartNumber << endl; 26: } 27: 28: // **************** Car Part ************ 29: 30: class CarPart : public Part 31: { 32: public: 33: CarPart():itsModelYear(94){ } 34: CarPart(int year, int partNumber); 35: virtual void Display() const 36: { 37: Part::Display(); 38: cout << "Model Year: "; 39: cout << itsModelYear << endl; 40: } 41: private: 42: int itsModelYear; 43: }; 44: 45: CarPart::CarPart(int year, int partNumber): 46: itsModelYear(year), 47: Part(partNumber) 48: { } 49: 50: 51: // *********** Класс AirPlane Part ********** 52: 53: class AirPlanePart : public Part 54: { 55: public: 56: AirPlanePart():itsEngineNumber(1){ } 57: AirPlanePart 58: (int EngineNumber, int PartNumber); 59: virtual void Display() const 60: { 61: Part::Display(); 62: cout << "Engine No.: "; 63: cout << itsEngineNumber << endl; 64: } 65: private: 66: int itsEngineNumDer; 67: }; 68: 69: AirPlanePart::AirPlanePart 70: (int EngineNumber, int PartNumber): 71: itsEngineNumber(EngineNumber), 72: Part(PartNumber) 73: { } 74: 75: // ************ Класс Part Node ************ 76: class PartNode 77: { 78: public: 79: PartNode (Part>>); 80: ~PartNode(); 81: void SetNext(PartNode * node) 82: { itsNext = node; } 83: PartNode * GetNext() const; 84: Part * GetPart() const; 85: private: 86: Part *itsPart; 87: PartNode * itsNext; 88: }; 89: //Выполнение PartNode... 90: 91: PartNode::PartNode(Part* pPart): 92: itsPart(pPart), 93: itsNext(0) 94: { } 95: 96: PartNode::~PartNode() 97: { 98: delete itsPart; 99: itsPart = 0; 100: delete itsNext; 101: itsNext = 0; 102: } 103: 104: // Возвращает NULL NULL, если нет следующего узла PartNode 105: PartNode * PartNode::GetNext() const 106: { 107: return itsNext; 108: } 109: 110: Part * PartNode::GetPart() const 111: { 112: if (itsPart) 113: return itsPart; 114: else 115: return NULL; //ошибка 116: } 117: 118: 119: 120: // ************ Класс Part List ************ 121: class PartsList 122: { 123: public: 124: PartsList(); 125: ~PartsList(); 126: // Необходимо, чтобы конструктор-копировщик и оператор соответствовали друг другу! 127: void Iterate(void (Part::*f)()const) const; 128: Part* Find(int & position, int PartNumber) const; 129: Part* GetFirst() const; 130: void Insert(Part *); 131: Part* operator[](int) const; 132: int GetCount() const { return itsCount; } 133: static PartsList& GetGlobalPartsList() 134: { 135: return GiobalPartsList; 136: } 137: private: 138: PartNode * pHead; 139: int itsCount; 140: static PartsList GiobalPartsList; 141: }; 142: 143: PartsList PartsList::GlobalPartsList; 144: 145: 146: PartsList::PartsList(): 147: pHead(0), 148: itsCount(0) 149: { } 150: 151: PartsList::~PartsList() 152: { 153: delete pHead; 154: } 155: 156: Part* PartsList::GetFirst() const 157: { 158: if (pHead) 159: return pHead->GetPart(); 160: else 161: return NULL; // ловушка ошибок 162: } 163: 164: Part * PartsList::operator[](int offSet) const 165: { 166: PartNode* pNode = pHead; 167: 168: if (!pHead) 169: return NULL; // ловушка ошибок 170: 171: if (offSet > itsCount) 172: return NULL; // ошибка 173: 174: for (int i=0;i<offSet; i++) 175: pNode = pNode->GetNext(); 176: 177: return pNode->GetPart(); 178: } 179: 180: Part* PartsList::Find( 181: int & position, 182: int PartNumber) const 183: { 184: PartNode * pNode = 0; 185: for (pNode = pHead, position = 0; 186: pNode!=NULL; 187: pNode = pNode->GetNext(), position++) 188: { 189: if (pNode->GetPart()->GetPartNumber() == PartNumber) 190: break; 191: } 192: if (pNode == NULL) 193: return NULL; 194: else 195: return pNode->GetPart(); 196: } 197: 198: void PartsList::Iterate(void (Part::*func)()const) const 199: { 200: if (!pHead) 201: return; 202: PartNode* pNode = pHead; 203: do 204: (pNode->GetPart( )->*func)(); 205: while (pNode = pNode->GetNext()); 206: } 207: 208: void PartsList::Insert(Part* pPart) 209: { 210: PartNode * pNode = new PartNode(pPart); 211: PartNode * pCurrent = pHead; 212: PartNode * pNext = 0; 213: 214: int New = pPart->GetPartNumber(); 215: int Next = 0; 216: itsCount++; 217: 218: if (!pHead) 219: { 220: pHead = pNode; 221: return; 222: } 223: 224: // если это значение меньше головного узла, 225: // то текущий узел становится головным 226: if (pHead->GetPart()->GetPartNumber()->New) 227: { 228: pNode->SetNext(pHead); 229: pHead = pNode; 230: return; 231: } 232: 233: for (;;) 234: { 235: // еcли нет следующего, вставляется текущий 236: if (!pCurrent->GetNext()) 237: { 238: pCurrent->SetNext(pNode); 239: return; 240: } 241: 242: // если текущий больше предыдущего, но меньше следующего, то вставляем 243: // здесь, Иначе присваиваем значение указателя Next 244: pNext = pCurrent->GetNext(); 245: Next = pNext->GetPart()->GetPartNumber(); 246: if (Next > New) 247: { 248: pCurrent->SetNext(pNode); 249: pNode->SetNext(pNext); 250: return; 251: } 252: pCurrent = pNext; 253: } 254: } 255: 256: 257: 258: class PartsCatalog : private PartsList 259: { 260: public: 261: void Insert(Part *); 262: int Exists(int PartNumber); 263: Part * Get(int PartNumber); 264: operator+(const PartsCatalog &); 265: void ShowAll() { Iterate(Part::Display); } 266: private: 267: }; 268: 269: void PartsCatalog::Insert(Part * newPart) 270: { 271: int partNumber = newPart->GetPartNumber(); 272: int offset; 273: 274: if (!Find(offset, partNumber)) 275: PartsList::Insert(newPart); 276: else 277: { 278: cout << partNumber << " was the "; 279: switch (offset) 280: { 281: case 0: cout << "first "; break; 282: case 1: cout << "second "; break; 283: case 2: cout << "third "; break; 284: default: cout << offset+1 << "th "; 285: } 286: cout << "entry. Rejected!\n"; 287: } 288: } 289: 290: int PartsCatalog::Exists(int PartNumber) 291: { 292: int offset; 293: Find(offset,PartNumber); 294: return offset; 295: } 296: 297: Part * PartsCatalog::Get(int PartNumber) 298: { 299: int offset; 300: return (Find(offset, PartNumber)); 301: 302: } 303: 304: int main() 305: { 306: PartsCatalog pc; 307: Part * pPart = 0; 308: int PartNumber; 309: int value; 310: int choice; 311: 312: while (1) 313: { 314: cout << "(0)Quit (1)Car (2)Plane: "; 315: cin >> choice; 316: 317: if (!choice) 318: break; 319: 320: cout << "New PartNumber?: "; 321: cin >> PartNumber; 322: 323: if (choice == 1) 324: { 325: cout << "Model Year?: "; 326: cin >> value; 327: pPart = new CarPart(value,PartNumber); 328: } 329: else 330: { 331: cout << "Engine Number?: "; 332: cin >> value; 333: pPart = newAirPlanePart(value,PartNumber); 334: } 335: pc.Insert(pPart); 336: } 337: pc.ShowAll(); 338: return 0; 339: } Результат: (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 1234 Model Year?: 94 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 4434 Model Year?: 93 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 1234 Model Year?: 94 1234 was the first entry. Rejected! (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 2345 Model Year?: 93 (0)Quit (1)Car (2)Plane: 0 Part Number: 1234 Model Year: 94 Part Number: 2345 Model Year: 93 Part Number: 4434 Model Year: 93 Анализ: В листинге 15.6 был изменен интерфейс класса PartsCatalog и переписана функция main(). Интерфейсы других классов остались такими же, как и в листинге 15.5. В строке 258 листинга 15.6 класс PartsCatalog производится как private от класса PartsList. Интерфейс класса PartsCatalog остался таким же, как и в листинге 15.5, хотя, конечно же, необходимость в объектах класса PartsList как переменных-членах отпала. Функция-член ShowAll() класса PartsCatalog вызывает функцию Iterate() из PartsList, параметром которой задается указатель на функцию-член класса Part. Таким образом, функция ShowAll() выполняет роль открытого интерфейса, позволяя пользователям получать информацию, не обращаясь напрямую к закрытой функции Iterate(), прямой доступ к которой закрыт для клиентов класса PartsCatalog. Функция Insert( )тоже изменилась. Обратите внимание, в строке 274 функция Find() теперь вызывается непосредственно, поскольку она наследуется из базового класса. Чтобы при вызове функции Insert() не возникло зацикливания функции на самое себя, в строке 275 делается явный вызов функции с указанием имени класса. Таким образом, если методам класса PartsCatalog необходимо вызвать методы PartsList, они могут делать это напрямую. Единствейное исключение состоит в том, что при необходимости заместить метод базового класса в классе PartsList следует явно указать класс и имя функции. Закрытое наследование позволяет PartsCatalog унаследовать функциональность базового класса и создавать интерфейс, косвенно открывающий доступ к его методам, которые нельзя вызывать напрямую. Рекомендуется:Применяйте открытое наследование, когда производный класс является разновидностью базового. Используйте вложение классов, когда необходимо делегировать выполнение задач другому классу, ограничив при этом доступ к его защищенным членам. Применяйте закрытое наследование, если необходимо реализовать один класс в пределах другого и обеспечить доступ к защищенным членам базового класса. Не рекомендуется:Не применяйте закрытое наследование, если необходимо использовать более одного объекта базового класса. Для этих целей больше подойдет вложение классов. Например, если для одного объекта PartsCatalog необходимы два объекта PartsList, вы не сможете использовать закрытое наследование. Не используйте открытое наследование, если необходимо закрыть клиентам производного класса прямой доступ к методам базового класса. Классы друзьяИногда для выполнения задач, поставленных перед программой, необходимо обеспечить взаимодействие нескольких независимых классов. Например, классы PartNode и PartsList тесно взаимосвязаны, и было бы удобно, если бы в PartsList можно было напрямую использовать указатель itsPart класса PartNode. Конечно, можно было бы объявить itsPart как открытую или хотя бы защищенную переменную-член, но это далеко не лучший путь, противоречащий самой идее использования классов. Поскольку указатель itsPart является специфическим членом класса PartNode, его следует оставить недоступным для внешних классов. Однако, если вы хотите предоставить данные или закрытые методы какому-либо иному классу, достаточно объявить этот класс другом. Это расширит интерфейс вашего класса возможностями класса-друга. После того как в PartsNode класс PartsList будет объявлен другом, переменные- члены и методы класса PartsNode станут доступными для PartsList. Важно заметить, что дружественность класса не передается на другие классы. Иными словами, если вы мой друг, а Ваня — ваш друг, это вовсе не значит, что Ваня также и мой друг. Кроме того, дружба не наследуется. Опять же, хотя вы мой друг и я хочу рассказать вам свои секреты, это не означает, что я желаю поделиться ими с вашими детьми. Наконец, дружественность классов односторонняя. Объявление одного класса другом какого-либо иного класса не делает последний другом первого. Вы при желании может поделиться своими секретами со мной, но это не значит, что я должен рассказать вам свои секреты. В листинге 15.7 представлена версия листинга 15.6, в которой используется объявление класса друга. Так, класс PartsList объявляется как друг класса PartNode. Еще раз напомним, что это объявление не делает класс PartNode другом класса PartsList. Листинг 15.7. Использование классов-друзей 1: #include <iostream.h> 2: 3: 4: 5: 6: // **************** Класс Part ************ 7: 8: // Абстрактный базовый класс всех деталей 9: class Part 10: { 11: public: 12: Part():itsPartNumber(1) { } 13: Part(int PartNumber): 14: itsPartNumber(PartNumber){ } 15: virtual ~Part(){ } 16: int GetPartNumber() const 17: { return itsPartNumber; } 18: virtual void Display() const =0; 19: private: 20: int itsPartNumber; 21: }; 22: 23: // выполнение чистой виртуальной функции в 24: // стандартном виде для всех производных классов 25: void Part::Display() const 26: { 27: cout << "\nPart Number: "; 28: cout << itsPartNumber << endl; 29: } 30: 31: // ************** Класс Car Part ************ 32: 33: class CarPart : public Part 34: { 35: public: 36: CarPart():itsModelYear(94){ } 37: CarPart(int year, int partNumber); 38: virtual void Display() const 39: { 40: Part::Display(); 41: cout << "Model Year: "; 42: cout << itsModelYear << endl; 43: } 44: private: 45: int itsModelYear; 46: }; 47: 48: CarPart::CarPart(int year, int partNumber): 49: itsModelYear(year), 50: Part(partNumber) 51: { } 52: 53: 54: // *********** Класс AirPlane Part *********** 55: 56: class AirPlanePart : public Part 57: { 58: public: 59: AirPlanePart():itsEngineNumber(1){ }; 60: AirPlanePart 61: (int EngineNumber, int PartNumber); 62: virtual void Display() const 63: { 64: Part::Display(); 65: cout << "Engine No.: "; 66: cout << itsEngineNumber << endl; 67: } 68: private: 69: int itsEngineNumber; 70: }; 71: 72: AirPlanePart::AirPlanePart 73: (int EngineNumber, int PartNumber): 74: itsEngineNumber(EngineNumber), 75: Part(PartNumber) 76: { } 77: 78: // **************** Класс Part Node ************ 79: class PartNode 80: { 81: public: 82: friend class PartsList; 83: PartNode (Part*); 84: ~PartNode(); 85: void SetNext(PartNode * node) 86: { itsNext = node; } 87: PartNode * GetNext() const; 88: Part * GetPart() const; 89: private: 90: Part *itsPart; 91: PartNode * itsNext; 92: }; 93: 94: 95: PartNode::PartNode(Part* pPart): 96: itsPart(pPart), 97: itsNext(0) 98: { } 99: 100: PartNode::~PartNode() 101: { 102: delete itsPart; 103: itsPart = 0; 104: delete itsNext; 105: itsNext = 0; 106: } 107: 108: // Возвращается NULL, если нет следующего узла PartNode 109: PartNode * PartNode::GetNext() const 110: { 111: return itsNext; 112: } 113: 114: Part * PartNode::GetPart() const 115: { 116: if (itsPart) 117: return itsPart; 118: else 119: return NULL; //ошибка 120: } 121: 122: 123: // ************** Класс Part List 124: class PartsList 125: { 126: public: 127: PartsList(); 128: ~PartsList(); 129: // Необходимо, чтобы конструктор-копировщик и оператор соответствовали друг другу 130: void Iterate(void (Part::*f)()const) const; 131: Part* Find(int & position, int PartNumber) const; 132: Part* GetFirst() const; 133: void Insert(Part *); 134: Part* operator[](int) const; 135: int GetCount() const { return itsCount; } 136: static PartsList& GetGlobalPartsList() 137: { 138: return GiobalPartsList; 139: } 140: private: 141: PartNode * pHead; 142: int itsCount; 143: static PartsList GiobalPartsList; 144: }; 145: 146: PartsList PartsList::GlobalPartsList; 147: 148: // Implementations for Lists... 149: 150: PartsList::PartsList(); 151: pHead(0), 152: itsCount(0) 153: { } 154: 155: PartsList::~PartsList() 156: { 157: delete pHead; 158: } 159: 160: Part* PartsList::GetFirst() const 161: { 162: if (pHead) 163: return pHead->itsPart; 164: else 165: return NULL; // ловушка ошибок 166: } 167: 168: Part * PartsList::operator[](int offSet) const 169: { 170: PartNode* pNode = pHead; 171: 172: if (!pHead) 173: return NULL; // ловушка ошибок 174: 175: if (offSet > itsCount) 176: return NULL; // ошибка 177: 178: for (int i=0;i<offSet; i++) 179: pNode = pNode->itsNext; 180: 181: return pNode->itsPart; 182: } 183: 184: Part* PartsList::Find(int & position, int PartNumber) const 185: { 186: PartNode * pNode = 0; 187: for (pNode = pHead, position = 0; 188: pNode!=NULL; 189: pNode = pNode->itsNext, position++) 190: { 191: if (pNode->itsPart->GetPartNumber() == PartNumber) 192: break; 193: } 194: if (pNode == NULL) 195: return NULL; 196: else 197: return pNode->itsPart; 198: } 199: 200: void PartsList::Iterate(void (Part::*func)()const) const 201: { 202: if (!pHead) 203: return; 204: PartNode* pNode = pHead; 205: do 206: (pNode->itsPart->*func)(); 207: while (pNode = pNode->itsNext); 208: } 209: 210: void PartsList::Insert(Part* pPart) 211: { 212: PartNode * pNode = new PartNode(pPart); 213: PartNode * pCurrent = pHead; 214: PartNode * pNext = 0; 215: 216: int New = pPart->GetPartNumber(); 217: int Next = 0; 218: itsCount++; 219: 220: if (!pHead) 221: { 222: pHead = pNode; 223: return; 224: } 225: 226: // если это значение меньше головного узла, 227: // то текущий узел становится головным 228: if (pHead->itsPart->GetPartNumber() > New) 229: { 230: pNode->itsNext = pHead; 231: pHead = pNode; 232: return; 233: } 234: 235: for (;;) 236: { 237: // если нет следующего, вставляется текущий 238: if (!pCurrent->itsNext) 239: { 240: pCurrent->itsNext = pNode; 241: return; 242: } 243: 244: // если текущий больше предыдущего, но меньше следующего, то вставляем 245: // здесь. Иначе присваиваем значение указателя Next 246: pNext = pCurrent->itsNext; 247: Next = pNext->itsPart->GetPartNumber(); 248: if (Next > New) 249: { 250: pCurrent->itsNext = pNode; 251: pNode->itsNext = pNext; 252: return; 253: } 254: pCurrent = pNext; 255: } 256: } 257: 258: class PartsCatalog : private PartsList 259: { 260: public: 261: void Insert(Part *); 262: int Exists(int PartNumber); 263: Part * Get(int PartNumber); 264: operator+(const PartsCatalog &); 265: void ShowAll() { Iterate(Part::Display); } 266: private: 267: }; 268: 269: void PartsCatalog::Insert(Part * newPart) 270: { 271: int partNumber = newPart->GetPartNumber(); 272: int offset; 273: 274: if (!Find(offset, partNumber)) 275: PartsList::Insert(newPart); 276: else 277: { 278: cout << partNumber << " was the "; 279: switch (offset) 280: { 281: case 0: cout << "first "; break; 282: case 1: cout << "second "; break; 283: case 2: cout << "third "; break; 284: default: cout << offset+1 << "th "; 285: } 286: cout << "entry. Rejected!\n"; 287: } 288: } 289: 290: int PartsCatalog::Exists(int PartNumber) 291: { 292: int offset; 293: Find(offset,PartNumber); 294: return offset; 295: } 296: 297: Part * PartsCatalog::Get(int PartNumber) 298: { 299: int offset; 300: return (Find(offset, PartNumber)); 301: 302: } 303: 304: int main() 305: { 306: PartsCatalog pc; 307: Part * pPart = 0; 308: int PartNumber; 309: int value; 310: int choice; 311: 312: while (1) 313: { 314: cout << "(0)Quit (1)Car (2)Plane: "; 315: cin >> choice; 316: 317: if (!choice) 318: break; 319: 320: cout << "New PartNumber?: "; 321: cin >> PartNumber; 322: 323: if (choice == 1) 324: { 325: cout << "Model Year?: "; 326: cin >> value; 327: pPart = new CarPart(value,PartNumber); 328: } 329: else 330: { 331: cout << "Engine Number?: "; 332: cin >> value; 333: pPart = new AirPlanePart(value,PartNumber); 334: } 335: pc.Insert(pPart); 336: } 337: pc.ShowAll(); 338: return 0; 339: } Результат: (0)Quit (1)Cat (2}Plane: 1 New PartNumber?: 1234 Model Year?: 94 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 4434 Model Year?: 93 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 1234 Model Year?: 94 1234 was the first entry. Rejected! (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 2345 Model Year?: 93 (0)Quit (1)Car (2)Plane: 0 Part Number: 1234 Model Year: 94 Part Number: 2345 Model Year: 93 Part Number: 4434 Model Year: 93 Анализ: В строке 82 класс PartsList объявляется другом класса PartNode. В данном случае объявление класса другом происходит в разделе public объявления класса PartNode, но так поступать вовсе не обязательно. Это объявление можно размещать в любом месте объявления класса, что не изменит его суть. В результате объявления класса как друга все закрытые методы и переменные-члены класса PartNode становятся доступными любой функции-члену класса PartsList. В строке 160 были внесены изменения в вызове функции-члена GetFirst() с учетом появившихся новых возможностей. Теперь вместо возвращения pHead->GetPart эта функция может возвращать закрытую переменную-член pHead->itsPart. Аналогичным образом в функции Insert() можно написать pNode->itsNext = pHead вместо переменной-члена pHead->SetNext(pHead). В данном случае внесенные изменения существенно не улучшили код программы, поэтому нет особых причин делать класс PartsList другом PartNode. В данном примере просто хотелось проиллюстрировать, как работает ключевое слово friend. Объявление классов-друзей следует применять с осторожностью. Класс объявляется как друг какого-либо иного класса в том случае, когда два класса тесно взаимодействуют друг с другом и открытие доступа одного класса к данным и методам другого класса существенно упрощает код программы. Однако зачастую проще организовать взаимодействие между классами с помощью открытых методов доступа. Примечание:От начинающих программистов C++ часто можно услышать замечание, что объявление классов-друзей противоречит принципу инкапсуляции, лежащему в основе объектно-ориентированного программирования. Это, честно говоря, довольно широко распространенная бессмыслица. Объявление класса-друга просто расширяет интерфейс другого класса, что влияет на инкапсуляцию не больше, чем открытое наследование классов. Дружественный класс Объявление одного класса другом какого-либо иного с помощью ключевого слова friend в объявлении второго класса открывает первому классу доступ к членам второго класса. Иными словами, я могу объявить вас своим другом, но вы не можете объявить себя моим другом. Пример: class PartNode{ public: friend class PartsList: // обьявление класса PartsList другом PartNode Функции друзьяИногда бывает необходимо предоставить права доступа не всему классу, а только одной или нескольким функциям-членам. Это реализуется посредством объявления друзьями функций-членов другого класса. Причем объявлять другом весь класс вовсе не обязательно. Фактически другом можно объявить любую функцию, независимо от того, является ли она функцией-членом другого класса или нет. Функции друзья и перегрузка оператораВ листинге 15.1 представлен класс String, в котором перегружается operator+. В нем также объявляется конструктор, принимающий указатель на константную строку, поэтому объект класса String можно создавать из строки с концевым нулевым символом. Примечание:Строки в С и C++ представляют собой массивы символов, заканчивающиеся концевым нулевым символом. Такая строка получается, например,в следующем выражении присвоения: myString[] = "Hello World". Но чего невозможно сделать в классе String, так это получить новую строку в результате сложения объекта этого класса с массивом символов: char cString[] = { "Hello"} ; String sString(" Worid"); String sStringTwo = cString + sString; //ошибка! Строки нельзя использовать с перегруженной функции operator+. Как объяснялось на занятии 10, выражение cString + sString на самом деле вызывает функцию cString.operator+(sString). Поскольку функция operator+() не может вызываться для символьной строки, данная попытка приведет к ошибке компиляции. Эту проблему можно решить, объявив функцию-друга в классе String, которая перегружает operator+ таким образом, чтобы суммировать два объекта String. Соответствующий конструктор класса String преобразует строки в объекты String, после чего вызывается функция-друг operator+, выполняющая конкатенацию двух объектов. Листинг 15.8. Функция-друг operator+ 1: // Листинг 15.8. Операторы друзья 2: 3: #include <iostream.h> 4: #include <string.h> 5: 6: // Рудиментарный класс string 7: class String 8: { 9: public: 10: // constructors 11: String(); 12: String(const char *const); 13: String(const String &); 14: ~String(); 15: 16: // перегруженные операторы 17: char & operator[](int offset); 18: char operator[](int offset) const; 19: String operator+(const String&); 20: friend String operator+(const String&, const String&); 21: void operator+=(const String&); 22: String & operator= (const String &); 23: 24: // методы общего доступа 25: int GetLen()const { return itsLen; } 26: const char * GetString() const { return itsString; } 27: 28: private: 29: String (int); // закрытый конструктор 30: char * itsString; 31: unsigned short itsLen; 32: }; 33: 34: // конструктор, заданный по умолчанию, создает строку длиной 0 байт 35: String::String() 36: { 37: itsString = new char[1]; 38: itsString[0] = '\0'; 39: itsLen=0; 40: // cout << "\tDefault string constructor\n"; 41: // ConstructorCount++: 42: } 43: 44: // закрытый конструктор, используемый только 45: // методами класса для создания новой строки 46: // указанного размера, заполненной нулями. 47: String::String(int len) 48: { 49: itsString = new char[len+1]; 50: for (int i = 0; i<=len; i++) 51: itsString[i] = '\0'; 52: itsLen=len; 53: // cout << "\tString(int) constructor\n"; 54: // ConstructorCount++; 55: } 56: 57: // Преобразует массив символов в строку 58: String::String(const char * const cString) 59: { 60: itsLen = strlen(cString); 61: itsString = new char[itsLen+1]; 62: for (int i = 0; i<itsLen; i++) 63: itsString[i] = cString[i]; 64: itsString[itsLen]='\0'; 65: // cout << "\tString(char*) constructor\n"; 66: // ConstructorCount++; 67: } 68: 69: // конструктор-копировщик 70: String::String (const String & rhs) 71: { 72: itsLen=rhs.GetLen(); 73: itsString = new char[itsLen+1]; 74: for (int i = 0; i<itsLen;i++) 75: itsString[i] = rhs[i]; 76: itsString[itsLen] = '\0'; 77: // cout << "\tString(String&) constructor\n"; 78: // ConstructorCount++; 79: } 80: 81: // деструктор, освобождает занятую память 82: String::~String () 83: { 84: delete [] itsString; 85: itsLen = 0; 86: // cout << "\tString destructor\n"; 87: } 88: 89: // этот оператор освобождает память, а затем 90: // копирует строку и размер 91: String& String::operator=(const String & rhs) 92: { 93: if (this == &rhs) 94: return <<this; 95: delete [] itsString; 96: itsLen=rhs.GetLen(); 97: itsString = new char[itsLen+1]; 98: for (int i = 0; i<itsLen;i++) 99: itsString[i] = rhs[i]; 100: itsString[itsLen] = 1\0'; 101: return *this; 102: // cout << "\tString operator=\n"; 103: } 104: 105: // неконстантный оператор индексирования, 106: // возвращает ссылку на символ, который можно 107: // изменить! 108: char & String::operator[](int offset) 109: { 110: if (offset > itsLen) 111: return itsString[itsLen-1]; 112: else 113: return itsString[offset]; 114: } 115: 116: // константный оператор индексирования, 117: // используется для константных объектов (см. конструктор-копировщик!) 118: char String::operator[](int offset) const 119: { 120: if (offset > itsLen) 121: return itsString[itsLen-1]; 122: else 123: return itsString[offset]; 124: } 125: // создает новый объект String, добавляя 126: // текущий обьект к rhs 127: String String::operator+(const String& rhs) 128: { 129: int totalLen = itsLen + rhs.GetLen(); 130: String temp(totalLen); 131: int i, j; 132: for (i = 0; i<itsLen; i++) 133: temp[i] = itsString[i]; 134: for (j = 0, i = itsLen; j<rhs.GetLen(); j++, i++) 135: temp[i] = rhs[j]; 136: temp[totalLen]='\0'; 137: return temp; 138: } 139: 140: // создает новый объект String 141: // из двух объектов класса String 142: String operator+(const String& lhs, const String& rhs) 143: { 144: int totalLen = lhs.GetLen() + rhs.GetLen(); 145: String temp(totalLen); 146: int i, j; 147: for (i = 0; i<lhs.GetLen(); i++) 148: temp[i] = lhs[i]; 149: for (j = 0, i = lhs.GetLen();; j<rhs.GetLen(); j++, i++) 150: temp[i] = rhs[j]; 151: temp[totalLen]='\0'; 152: return temp; 153: } 154: 155: int main() 156: { 157: String s1("String 0ne "); 158: String s2("String Two "); 159: char *c1 = { "C-String 0ne " } ; 160: String s3; 161: Stnng s4; 162: String s5; 163: 164: cout << "s1: " << s1.GetString() << endl; 165: cout << "s2: " << s2.GetString() << endl; 166: cout << "c1: " << c1 << endl; 167: s3 = s1 + s2; 168: cout << "s3: " << s3.GetString() << endl; 169: s4 = s1 + cl; 170: cout << "s4: " << s4.GetStnng() << endl; 171: s5 = c1 + s2; 172: cout << "s5: " << s5.GetString() << endl; 173: return 0; 174: } Результат: s1: String 0ne s2: String Two c1: C-String One s3: String One String Two s4: String One C-String One s5: C-String One String Two Анализ: Объявления всех методов класса String, за исключением operator+, остались такими же, как в листинге 15.1. В строке 20 листинга 15.8 перегружается новый operator+, который принимает две ссылки на константные строки и возвращает строку, полученную в результате конкатенации исходных строк. Эта функция объявлена как друг класса String. Обратите внимание, что функция operator+ не является функцией-членом этого или любого другого класса. Она объявляется среди функций-членов класса string как друг, но не как член класса. Тем не менее это все же полноценное объявление функции, и нет необходимости еще раз объявлять в программе прототип этой функции. Выполнение функции operator+ определяется в строках 142—153. Определение выполнения функции аналогично приведенному в версии программы, представленной в листинге 15.1, за тем исключением что функция принимает в качестве аргументов две строки, обращаясь к ними с помощью открытых методов доступа класса. Перегруженный оператор применяется в строке 171, где выполняется конкатенация двух строк. Функции-друзья Для объявления функции как друга класса используется ключевое слово friend, за которым следует объявление функции Это не предоставляет функции доступ к указателю this, но обеспечивает доступ ко всем закрытым и защищенным данным и функциям-членам. Пример: class PartNode { // ... // сделаем функцию-член другого класса другом этого класса friend void PartsList::Insert(Part*) // сделаем другом глобальную функцию friend int SomeFunction(); // ... }; Перегрузка оператора выводаНастало время снабдить наш класс String возможностью использовать объект cout для вывода своих данных так же, как при выводе данных базовых типов. До сих пор для вывода значения переменной-члена приходилось использовать следующее выражение: cout << theString.GetString(); Неплохо было бы иметь возможность написать просто cout << theString; Для этого необходимо перегрузить функцию operator<<(). Более подробно использование потоков iostreams для вывода данных обсуждается на занятии 16. А в листинге 15.9 объявляется перегрузка функции operator<< как друга. Листинг 15.8. Перегрузка operator<<() 1: #include <iostream.h> 2: #include <string.h> 3: 4: class String 5: { 6: public: 7: // конструкторы 8: String(); 9: String(const char *const); 10: String(const String &); 11: ~String(); 12: 13: // перегруженные операторы 14: char & operator[](int offset); 15: char operator[](int offset) const; 16: String operator+(const String&); 17: void operator+=(const String&); 18: String & operator= (const String &); 19: friend ostream& operator<< 20: (ostream& theStream,String& theString); 21: // Общие методы доступа 22: int GetLen()const { return itsLen; } 23: const char * GetString() const { return itsString; } 24: 25: private: 26: String (int); // закрытый конструктор 27: char * itsString; 28: unsigned short itsLen; 29: }; 30: 31: 32: // конструктор, заданный no умолчанию, создает строку длиной 0 байт 33: String::String() 34: { 35: itsString = new char[1]; 36: itsString[0] = '\0' ; 37: itsLen=0; 38: // cout << "\tDefault string constructor\n"; 39: // ConstructorCount++; 40: } 41: 42: // закрытый конструктор, используемый только 43: // методами класса для создания новой строки 44: // указанного размера, заполненной значениями NULL. 45: String::String(int len) 46: { 47: itsString = new char[k:.H]; 48: for (int i = 0; i<=len; i++) 49: itsString[i] = '\0'; 50: itsLen=len; 51: // cout << "\tString(int) constructor\n"; 52: // ConstructorCount++; 53: } 54: 55: // Преобразует массив символов в строку 56: String::String(const char * const cString) 57: { 58: itsLen = strlen(cString); 59: itsString = new char[itsLen+1]; 60: for (int i = 0; i<itsLen; i++) 61: itsString[i] = cString[i]; 62: itsString[itsLen]='\0'; 63: // cout << "\tString(char*) constructor\n"; 64: // ConstructorCount++; 65: } 66: 67: // конструктор-копировщик 68: String::String (const String & rhs) 69: { 70: itsLen=rhs.GetLen(); 71: itsString = new char[itsLen+1]; 72: for (int i = 0; i<itsLen;i++) 73: itsString[i] = rhs[i]; 74: itsString[itsLen] = '\0'; 75: // cout << "\tString(String&) constructor\n"; 76: // ConstructorCount++; 77: } 78: 79: // деструктор освобождает занятую память 80: String::~String () 81: { 82: delete [] itsString; 83: itsLen = 0; 84: // cout << "\tString destructor\n"; 85: } 86: 87: // оператор равенства освобождает память, а затем 88: // копирует строку и размер 89: String& String::operator=(const String & rhs) 90: { 91: if (this == &rhs) 92: return *this; 93: delete [] itsString; 94: itsLen=rhs.GetLen(); 95: itsString = new char[itsLen+1]; 96: for (int i = 0; i<itsLen;i++) 97: itsString[i] = rhs[i]; 98: itsString[itsLen] = '\0'; 99: return *this; 100: // cout << "\tString operator=\n"; 101: } 102: 103: // неконстантный оператор индексирования, 104: // возвращает ссылку на символ, который можно 105: // изменить! 106: char & String::operator[](int offset) 107: { 108: if (offset > itsLen) 109: return itsString[itsLen-1]; 110: else 111: return itsString[offset]; 112: } 113: 114: // константный оператор индексирования, 115: // используется для константных объектов (см. конструктор-копировщик!) 116: char String::operator[](int offset) const 117: { 118: if (offset > itsLen) 119: return itsString[itsLen-1]; 120: else 121: return itsString[offset]; 122: } 123: 124: // создает новую строку, добавляя текущую 125: // строку к rhs 126: String String::operator+(const String& rhs) 127: { 12S: int totalLen = itsLen + rhs.GetLen(); 129: String temp(totalLen); 130: int i, j; 131: for (i = 0; i<itsLen; i++) 132: temp[i] = itsString[i]; 133: for (j = 0; j<rhs.GetLen(); j++, i++) 134: temp[i] = rhs[]; 135: temp[totalLen]='\0'; 136: return temp; 137: } 138: 139: // изменяет текущую строку, ничего не возвращая 140: void String::operator+=(const String& rhs) 141: { 142: unsigned short rhsLen = rhs.GetLen(); 143: unsigned short totalLen = itsLen + rhsLen; 144: String temp(totalLen); 145: int i, j; 146: for (i = 0; i<itsLen; i++) 147: temp[i] = itsString[i]; 148: for (j = 0, i = 0; j<rhs.GetLen(); j++, i++) 149: temp[i] = rhs[i-itsLen]; 150: temp[totalLen]='\0' ; 151: *this = temp; 152: } 153: 154: // int String::ConstructorCount = 155: ostream& operator<< ( ostream& theStream,String& theString) 156: { 157: theStream << theString.itsString; 158: return theStream; 159: } 160: 161: int main() 162: { 163: String theString("Hello world."); 164: cout << theString; 165: return 0; 166: } Результат: Hello world. Анализ: В строке 19 operator<< объявляется как функция-друг, которая принимает ссылки на ostream и String и возвращает ссылку на ostream. Обратите внимание, что она не является функцией-членом класса String. Поскольку эта функция возвращает ссылку на ostream, можно конкатенировать вызовы operator<< следующим образом: cout << "myAge: " << itsAge << " years. "; Выполнение этой функции-друга представлено строками 155—159. Основное назначение функции состоит в том, чтобы скрыть детали процедуры передачи строки в iostream. Больше ничего и не требуется. Более подробно о функции ввода и перегрузке operator>> вы узнаете на следующем занятии. РезюмеСегодня вы узнали, как делегировать ответственность за выполнение специальных задач вложенным объектам, а также выполнять один класс в пределах другого с помощью вложения или открытого наследования. Основное ограничение вложения — отсутствие у нового класса доступа к защищенным членам вложенного класса и возможности замещения функций-членов вложенного объекта. Вложение гораздо проще в использовании, чем закрытое наследование, поэтому по возможности следует применять этот подход. Вы также узнали, как объявлять классы и функции-друзьями другого класса. Объявление функции друга позволяет перегрузить оператор ввода таким образом, что появляется возможность использовать объект cout в пользовательском классе точно так же, как в стандартных встроенных классах. Напомним, что открытое наследования определяет производный класс как уточнение базового класса; вложение подразумевает обладание одним классом объектами другого класса, а закрытое наследование состоит в выполнении одного класса средствами другого класса. Делегирование ответственности реализуется либо вложением, либо закрытым наследованием, хотя первое предпочтительнее. Вопросы и ответыПочему так важно разбираться в особенностях отношений между классами при выборе различных подходов установки взаимосвязей между ними? Язык программирования C++ создавался специально для разработки объектно-ориентированных программ. Характерной особенностью объектно-ориентированного программирования является моделирование в программе реальных отношений между объектами и явлениями окружающего мира, причем при выборе подходов программирования следует учитывать особенности этих отношений, чтобы максимально точно смоделировать реальность. Почему вложение предпочтительнее закрытого наследования? Современное программирование — это разрешение противоречий между достижением максимальной точности моделирования событий и предупреждением чрезвычайного усложнения программ. Поэтому чем больше объектов программы будут использоваться как "черные ящики", тем меньше всевозможных параметров нужно отслеживать при отладке или модернизации программы. Методы вложенных классов скрыты от пользователей, что нельзя сказать о закрытом наследовании. Почему бы не описать все классы, объекты которых используются в других классах, друзьями этих классов? Объявление одного класса другом какого-либо иного открывает закрытые методы и данные класса, что снижает инкапсуляцию класса. Лучше всего держать как можно больше членов одного класса закрытыми от всех остальных классов. Если функция перегружается, нужно ли описывать каждый вариант этой функции другом класса? Да. Если вы перегружаете функцию и хотите представить все варианты этой функции друзьями другого класса, то в описании класса каждый вариант функции должен сопровождаться ключевым словом friend. КоллоквиумВ этом разделе предлагаются вопросы для самоконтроля и укрепления полученных знаний и приводится несколько упражнений, которые помогут закрепить ваши практические навыки. Попытайтесь самостоятельно ответить на вопросы теста и выполнить задания, а потом сверьте полученные результаты с ответами в приложении Г. Не приступайте к изучению материала следующей главы, если для вас остались неясными хотя бы некоторые из вопросов, предложенных ниже. Контрольные вопросы1. Как объявить класс, являющийся частным проявлением другого класса? 2. Как объявить класс, объекты которого должны использоваться в качестве переменных-членов другого класса? 3. В чем состоят различия между вложением и делегированием? 4. В чем состоят различия между делегированием и выполнением класса в пределах другого класса? 5. Что такое функция-друг? 6. Что такое класс-друг? 7. Если класс Dog является другом Boy, то можно ли сказать, что Boy — друг Dog? 8. Если класс Dog является другом Boy, а Terrier произведен от Dog, является ли Terrier другом Boy? 9. Если класс Dog является другом Boy, а Boy — другом House, можно ли считать Dog другом House? 10. Где необходимо размещать объявление функции-друга? Упражнения1. Объявите класс Animal, который содержит переменную-член, являющуюся объектом класса String. 2. Объявите класс BoundedArray, являющийся массивом. 3. Объявите класс Set, выполняемый в пределах массива BoundedArray. 4. Измените листинг 15.1 таким образом, чтобы класс String включал перегруженный оператор вывода (>>). 5. Жучки: найдите ошибки в этом коде: 1: #include <iostream.h> 2: 3: class Animal; 4: 5: void setValue(Animal& , int); 6: 7: 8: class Animal 9: { 10: public: 11: int GetWeight()const { return itsWeight; } 12: int GetAge() const { return itsAge; } 13: private: 14: int itsWeight; 15: int itsAge; 16: }; 17: 18: void setValue(Animal& theAnimal, int theWeight) 19: { 20: friend class Animal; 21: theAnimal.itsWeight = theWeight; 22: } 23: 24: int main() 25: { 26: Animal peppy; 27: setValue(peppy,5); 28: } 6. Исправьте листинг, приведенный в упражнении 5, и откомпилируйте его. 7. Жучки: найдите ошибки в этом коде: 1: #include<iostream.h> 2: 3: class Animal; 4: 5: void setValue(Animal& , int); 6: void setValue(Animal&. ,int,int); 7: 8: class Animal 9: { 10: friend void setValue(Animal& ,int); 11: private: 12: int itsWeight; 13: int itsAge; 14: }; 15: 16: void setValue(Animal& theAnimal, int theWeight) 17: { 18: theAnimal.itsWeight = theWeight; 19: } 20: 21: 22: void setValue(Animal& theAnimal, int theWeight, int theAge) 23: { 24: theAnimal.itsWeight = theWeight; 25: theAnimal.itsAge = theAge; 26: } 27: 28: int main() 29: { 30: Animal peppy; 31: setValue(peppy,5); 32: setValue(peppy, 7, 9); 33: } 8. Исправьте листинг, приведенный в упражнении 7, и откомпилируйте его. День 16-й. ПотокиРанее для вывода на экран и считывания с клавиатуры мы использовали объекты cout и cin, не понимая до конца принципов их работы. Сегодня вы узнаете: • Что такое потоки ввода-вывода и как они используются • Как с помощью потоков управлять вводом и выводом данных • Как с помощью потоков записывать информацию в файл и затем считывать ее Знакомство с потокамиЯзык программирования C++ специально не определяет, каким образом данные выводятся на экран или в файл либо как они считываются программой. Тем не менее эти особенности являются важной частью работы программиста, поэтому стандартная библиотека C++ включает библиотеку iostream, упрощающую ввод-вывод (I/O). Благодаря выделению операций ввода-вывода в отдельную библиотеку упрощается создание аппаратно независимого языка разработки программ для разных платформ. Это позволяет создать программу на C++ для компьютеров PC, а затем откомпилировать ее для рабочей станции Sun. Разработчики снабдили компилятор библиотеками для всех случаев. Так, по крайней мере, должно быть теоретически. Примечание:Библиотека — это набор файлов OBJ, которые можно подключать к программе для получения дополнительных функциональных возможностей. Это наиболее распространенная форма многократного использования кода, и можно сказать, что она существует еще с тех пор, как первобытные программисты каменного века выбивали первые нули и единицы на стенах своих пещер. ИнкапсуляцияКлассы iostream рассматривают информацию, выводимую программой на экран, как побитовый поток данных. Если данные выводятся в файл или на экран, то источник потока, как правило, содержится в программе. Если же поток направлен в противоположную сторону, данные могут поступать с клавиатуры или файла на диске. В этом случае они заносятся в переменные. Одна из основных целей использования потоков состоит в инкапсуляции процедуры обмена данными с диском или дисплеем компьютера. Сама программа работает только с потоками, которые реализуют эти процессы. Схематически эта идея проиллюстрирована на рис. 16.1. 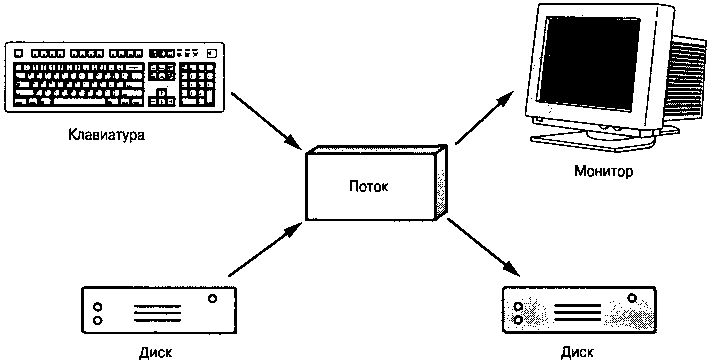 Рис. 16.1. Инкапсуляция с помощью потоков БуферизацияЗапись на диск (и в меньшей степени вывод на экран) обходится очень дорого. Запись данных на диск и считывание их с диска требует довольно много времени, что может надолго заблокировать выполнение программы. Для решения этой проблемы потоки обеспечивают буферизацию. Данные сначала записываются в буфер потока, а после его наполнения вся информация разом записывается на диск. Суть идеи проиллюстрирована на примере знакомого со школьной скамьи бака с в.одой (рис. 16.2). Вода заливается сверху, и бак постепенно наполняется, поскольку нижний вентиль закрыт. Когда вода (данные) достигает верха, нижний вентиль автоматически открывается и вся вода выливается (рис. 16.3). Как только бак опустеет, нижний вентиль закрывается, а верхний открывается вновь, и вода снова поступает в бак (рис. 16.4). В некоторых случаях необходимо, чтобы вода сразу же выливалась из бака, не дожидаясь его наполнения. В программировании такая ситуация называется очисткой буфера (рис. 16.5). 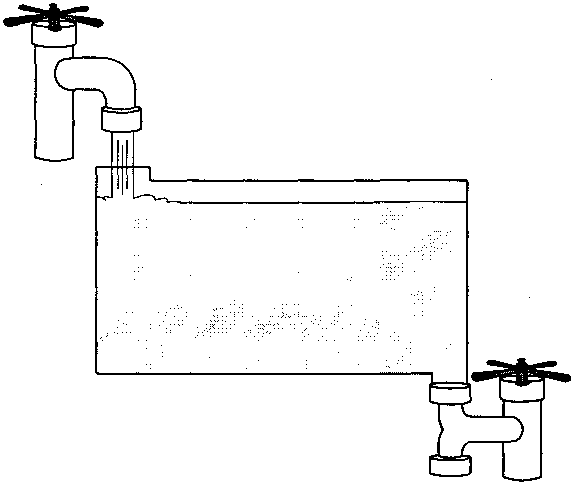 Рис. 16.2. Буфер наполняется данными, как закрытый бак — водой 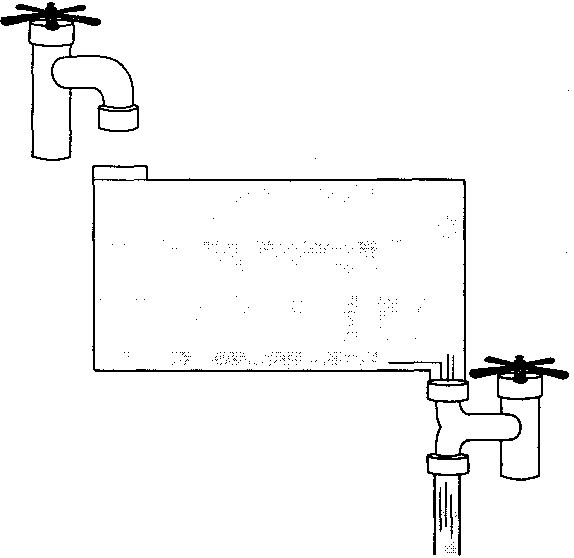 Рис. 16.3. Открывается сливной вентиль, и вода (данные) сливается из бака 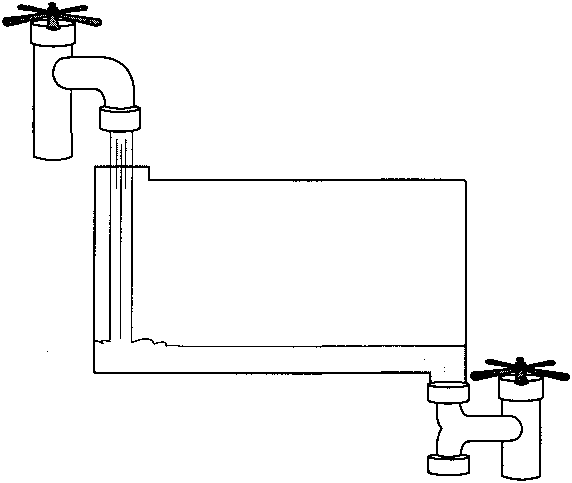 Рис. 16.4. Повторное наполнение бака  Рис. 16.5. Очистка буфера подобна экстренному сливу воды Потоки и буферыВ C++ применяется объектно-ориентированный подход к реализации обмена данными с буферизированными потоками. • Класс streambuf управляет буфером, поэтому его функции предоставляют возможность наполнять, опорожнять и очищать буфер, а также выполнять с ним другие операции. • Класс ios является базовым для классов потоков ввода-вывода. В качестве переменной-члена класса ios выступает объект streambuf. • Классы istream и ostream являются производными от класса ios и отвечают соответственно за потоковый ввод и вывод данных. • Класс iosteam является производным от классов istream и ostream и обеспечивает методы ввода-вывода для печати на экран. • Классы fstream используются для ввода-вывода из файлов. Стандартные объекты ввода-выводаПри запуске программы, включающей классы iostreams, создаются и инициируются четыре объекта. Примечание:Библиотека класса iostream встроена в компилятор. Чтобы добавить в свою программу методы этого класса, достаточно в первых строках программы включить выражение #include<iostream>. • Объект cin (произносится как "си-ин" от английского "see-in") обрабатывает ввод с клавиатуры. • Объект cout (произносится как "си-аут" от английского "see-out") обрабатывает вывод на экран. • Объект cerr (произносится как "си-эр" от английского "see-err") обрабатывает не буферизированный вывод ошибок на стандартное устройство вывода сообщений об ошибках, т.е. на экран. Поскольку вывод не буферизированный, то все данные, направляемые в c err, сразу же выводятся устройством вывода. • Объект clog (произносится как "си-лог" от английского "see-log") обрабатывает буферизированные сообщения об ошибках, которые выводятся на стандартное устройство вывода сообщений об ошибках (экран). Зачастую эти сообщения переадресуются в файл регистрации. Об этом вы узнаете далее в главе. ПереадресацияКаждое стандартное устройство ввода и вывода, в том числе устройство вывода сообщений об ошибках, может осуществлять переадресацию на другие устройства. Например, системные сообщения об ошибках часто переадресуются в файл регистрации. Для ввода и вывода данных программой также можно использовать файлы, для чего служат специальные команды операционной системы. Под переадресацией понимают пересылку выводимых данных в устройство, либо считывание данных с устройства, отличное от установленного по умолчанию. В операционных системах DOS и UNIX используются специальные операторы переадресации ввода (<) и вывода (>). Пайпингом называется использование вывода одной программы в качестве ввода для другой. Операционная система DOS содержит ограниченный набор команд переадресации для вывода (>) и ввода (<). Команды переадресации системы UNIX более разнообразны, однако основная идея остается той же: данные выводятся на экран, записываются в файл или передаются другой программе. Ввод в программу осуществляется из файлов или с клавиатуры. В целом переадресация больше относится к функциям операционной системы, а не библиотек iosream. Язык C++ предоставляет доступ к четырем стандартным устройствам и необходимый набор команд для переадресации устройств ввода-вывода. Вывод данных с помощью cinГлобальный объект cin отвечает за ввод данных и становится доступным при включении в программу класса iostream. В предыдущих примерах используется перегруженный оператор ввода (>>) для присвоения вводимых данных переменным программы. Для ввода данных используется следующий синтаксис". int someVariable; cout << "Enter а number: "; cin >> someVariable; Другой глобальный объект, cout, и его использование для вывода данных обсуждается несколько ниже. Сейчас же остановимся на третьей строке: cin >> someVariable;. Что же представляет собой объект cin? На глобальность этого объекта указывает тот факт, что его не нужно объявлять в коде программы. Объект cin включает перегруженный оператор ввода (>>), который записывает данные, хранимые в буфере cin, в локальную переменную someVariable. Причем оператор ввода перегружен таким образом, что подходит для ввода данных всех базовых типов, включая int&, short&, long&, double&, float&, char&, char* и т.п. Когда компилятор встречает выражение cin >> someVariable, то вызывается вариант оператора ввода, соответствующий типу переменной someVariable. В приведенным выше примере someVariable имеет тип int, поэтому вызывается следующий вариант перегруженной функции: istream & operator>> (int&) Обратите внимание, поскольку параметр передается как ссылка, оператор ввода может изменять исходную переменную. Использование cin показано в листинге 16.1. Листинг 16.1. Использование cin для ввода данных разных типов 1: //Листинг 16.1. Ввод даннах с помощью cin 2: 3: #include <iostream.h> 4: 5: int main() 6: { 7: int myInt; 8: long myLong; 9: double myDouble; 10: float myFloat; 11: unsigned int myUnsigned; 12: 13: cout << "int: "; 14: cin >> myInt; 15: cout << "Long: "; 16: cin >> myLong; 17: cout << "Double: "; 18: cin >> myDouble; 19: cout << "Float: "; 20: cin >> myFloat; 21: cout << "Unsigned: "; 22: cin >> myUnsigned; 23: 24: cout << "\n\nInt:\t" << myInt << endl; 25: cout << "Long:\t" << myLong << endl; 26: cout << "Double:\t" << myDouble << endl; 27: cout << "Float:\t" << myFloat << endl; 28: cout << "Unsigned:\t" <<myUnsigned << endl; 29: return 0; 30: } Результат: int: 2 Long: 70000 Double: 987654321 Float: 3.33 Unsigned: 25 Int: 2 Long: 70000 Double: 9.87654e+08 Float: 3.33 Unsigned: 25 Анализ: В строках 7—11 объявляются переменные разных типов. В строках 13—22 пользователю предлагается ввести значения для этих переменных, после чего результаты выводятся в строках 24—28 (с помощью cin). Выводимая программой информация говорит о том, что переменные записываются и выводятся в соответствии с их типом. СтрокиОбъект cin также может принимать в качестве аргумента указатель на строку символов (char*), что позволяет создавать буфер символов и заполнять его с помощью cin. Например, можно написать следующее: char YourName[50] cout << "Enter your name: "; cin >> YourName; Если ввести имя Jesse, переменная YourName заполнится символами J, e, s, s, e и \0. Последним будет концевой нулевой символ, так как cin автоматически вставляет его. Поэтому при определении размера буфера нужно позаботиться о том, чтобы он был достаточно большим и мог вместить все символы строки, включая концевой нулевой символ. Более подробно о поддержке концевого нулевого символа стандартными библиотечными строковыми функциями речь пойдет на занятии 21. Проблемы, возникающие при вводе строкУспешно выполнив все описанные ранее операции с объектом cin, вы будете неприятно удивлены, если попытаетесь ввести в строке полное имя. Дело в том, что cin рассматривает пробел как заданный по умолчанию разделитель строк. После того как в строке обнаруживается пробел, ввод строки завершается добавлением концевого нулевого символа. Эта проблема показана в листинге 16.2. Листинг 16.2. Попытка ввода бодев одного сша с помощьм cin 1: //Листинг 16.2. Проблемы с вводом строки с помощью cin 2: 3: #include <iostream.h> 4: 5: int main() 6: { 7: char YourName[50]; 8: cout << "Your first name: "; 9: cin >> YourName; 10: cout << "Here it is: " << YourName << endl; 11: cout << "Your entire name: "; 12: cin >> YourName; 13: cout << "Here it is: " << YourName << endl; 14: return 0; 15: } Результат: Your first name: Jesse Here it is: Jesse Your entire name: Jesse Liberty Here it is: Jesse Анализ: Строкой 7 для хранения вводимой пользователем строки создается массив символов. В строке 8 пользователю предлагается ввести имя, и, как видно из вывода, это имя сохраняется правильно. В строке 11 пользователю предлагается ввести не только имя, но и фамилию. Ввод осуществляется только до тех пор, пока cin не обнаружит пробел между именем и фамилией. После этого ввод строки прекращается и оставшаяся информация теряется. Это не совсем то, что было нужно. Чтобы понять, почему cin работает именно так, проанализируйте листинг 16.3, в котором показан пример ввода строки значений. Листинг 16.3. Ввод строки значений 1: //Листинг 16.3. Ввод строки значений с помощью cin 2: 3: #include <iostream.h> 4: 5: int main() 6: { 7: int myInt; 8: long myLong; 9: double myDouble; 10: float myFloat; 11: unsigned int myUnsigned; 12: char myWord[50]; 13: 14: cout << "int: "; 15: cin >> myInt; 16: cout << "Long: "; 17: cin >> myLong; 18: cout << "Double: "; 19: cin >> myDouble; 20: cout << "Float: "; 21: cin >> myFloat; 22: cout << "Word: "; 23: cin >> myWord; 24: cout << "Unsigned: "; 25: cin >> myUnsigned; 26: 27: cout << "\n\nInt:\t" << myInt << endl; 28: cout << "Long:\t" << myLong << endl; 29: cout << "Double:\t" << myDouble << endl; 30: cout << "Float:\t" << myFloat << endl; 31: cout << "Word: \t" << myWord << endl; 32: cout << "Unsigned:\t" << myUnsigned << endl; 33: 34: cout << "\n\nInt, Long, Double, Float, Word, Unsigned: "; 35: cin >> myInt >> myLong >> myDouble; 36: cin >> myFloat >> myWord >> myUnsigned; 37: cout << "\n\nInt:\t" << myInt << endl; 38: cout << "Long:\t" << myLong << endl; 39: cout << "Double:\t" << myDouble << endl; 40: cout << "Float:\t" << myFloat << endl; 41: cout << "Word: \t" << myWord << endl; 42: cout << "Unsigned:\t" << myUnsigned << endl; 43: 44: 45: return 0; 46: } Результат: Int: 2 Long: 30303 Double: 393939397834 Float: 3.33 Word: Hello Unsigned: 85 Int: 2 Long: 30303 Double: 3.93939e+11 Float: 3.33 Word: Hello Unsigned: 85 Int, Long. Double, Float, Word, Unsigned: 3 304938 393847473 6.66 bye -2 Int: 3 Long: 304938 Double: 3.93847e+08 Float: 6.66 Word: bye Unsigned: 4294967294 Вновь в программе объявляются переменные разных типов и массив символов. Пользователю предлагается последовательно ввести данные разных типов, чтобы убедиться что программа поддерживает ввод данных любого типа. Анализ: В строке 34 пользователю предлагается ввести все данные сразу в определенном порядке, после чего каждое введенное значение присваивается соответствующей переменной. Благодаря тому что cin рассматривает пробелы между словами как разделители, становится возможной инициализация всех переменных. В противном случае программа пыталась бы ввести всю строку в одну переменную, что было бы ошибкой. Обратите внимание на строку 42, в которой выводится без знаковое целое число. Пользователь ввел значение -2. Поскольку программа была проинструктирована, что вводится без знаковое целое число, то вместо знакового -2 будет введено без знаковое двоичное представление этого числа. Поэтому при выводе с помощью cout на экране отображается значение 4294967294, являющееся двоичным представлением числа -2. Позже вы узнаете, как вводить в буфер строки, содержащие несколько слов, разделенных пробелами. Сейчас же рассмотрим подробнее использование cin для ввода данных сразу в несколько переменных, как в строках 35-36. Оператор >> возвращает ссылку на объект istreamОператор >> возвращает ссылку на объект istream. Но поскольку cin сам является объектом istream, результат выполнения одной операции ввода может быть началом следующей операции ввода, как показано ниже: Int Var0ne, varTwo, varThree; cout << "Enter three numbers: " cin >> Var0ne >> varTwo >> varThree; В строке cin >> VarOne >> varTwo >> varThree; сначала выполняется первый ввод cin >> VarOne, в результате чего возвращается объект istream, позволяющий выполнить присвоение второго значения переменной varTwo. Это равносильно следующей записи: ((cin >> VarOne) >> varTwo) >> varThree; Аналогичный подход используется с объектом cout, но речь об этом пойдет дальше. Другие методы объекта cinВ дополнение к перегружаемому оператору >> объект cin имеет множество других встроенных методов. Они используются в тех случаях, когда необходим более совершенный контроль над вводом данных. Ввод одного символаВариант operator>>, принимающий ссылку на символ, может использоваться для считывания одного символа со стандартного устройства ввода. Для этого используется функция-член get(). При этом можно применять get() без параметров или использовать вариант этой же функции, принимающей в качестве параметра ссылку на символ. Использование функции gef() без параметровСначала рассмотрим использование функции get() без параметров. В этом случае функция возвращает значение найденного символа или EOF (end of file — конец файла) при достижении конца файла. Функция get () без параметров используется редко. Так, cin.get() нельзя использовать для последовательной инициализации ряда переменных, поскольку возвращаемое функцией значение не является объектом iostream. Именно поэтому следующая запись работать не будет: cin.get() >>myVarOne >> myVarTwo // ошибка Запись cin.get() >> myVarOne возвращает значение типа int, а не объект iostream. Пример использования функции get() без параметров показан в листинге 16.4. Листинг 16.4. Использование функции get() Вез параметров 1: // Листинг 16.4. Использование get() без параметров 2: #include <iostream.h> 3: 4: int main() 5: { 6: char ch; 7: while ( (ch = cin.get()) != EOF) 8: { 9: cout << "ch: " << ch << endl; 10: } 11: cout << "\nDone!\n"; 12: return 0; 13: } Примечание:Для выхода из этой программы придется ввести символ конца файла с клавиатуры. С этой целью в операционной системе DOS используется комбинация клавиш <Ctrl+Z>, а в UNIX — <Ctrl+D>. Результат: Hello ch H ch e ch 1 ch 1 ch о ch World ch W ch о ch r ch 1 ch d ch (ctrl-z) Done! Анализ: В строке 6 объявляется локальная символьная переменная. В цикле while символ, полученный от cin.get(), присваивается ch, и если возвращенный символ не EOF, то он выводится на печать. Цикл завершается вводом EOF, комбинацией клавиш <Ctrl+Z> в DOS или <Ctrl+D> в UNIX. Следует отметить, что не во всех версиях библиотеки istream поддерживается функция-член get(), хотя сейчас она является частью стандарта ANSI/ISO. Использование функции get() с параметромПри установке в функции get() параметра, указывающего на символьную переменную, этой переменной присваивается очередной символ потока ввода. При этом возвращается объект iostream, что позволяет вводить последовательный ряд значений, как показано в листинге 16.5. Листинг 16.5. Использование функции get() с параметрами 1: // Листинг 16.5. Использование get() с параметрами 2: #include <iostream.h> 3: 4: int main() 5: { 6: char а, b, с; 7: 8: cout << "Enter three letters: "; 9: 10: cin.get(a).get(b).get(c); 11: 12: cout << "а: " << а << "\nb: " << b << "\nc: " << с << endl; 13: return 0; 14: } Результат: Enter three letters: one а: о b: n с: e Анализ: В строке 6 объявляются символьные переменные а, b и с. В строке 10 трижды последовательно вызывается функция cin.get(). Сначала вызывается cin.get(a), в результате первый символ буфера ввода заносится в а и возвращается объект cin, после чего происходит вызов cin.get(b), присваивающий очередной символ буфера переменной b. Аналогичным образом вызывается функция cin.get(c), присваивающая следующий символ переменной с. Поскольку cin.get() возвращает cin, можно было записать это следующим образом: cin.get(a) >> b; В этом случае cin.get(a) возвратит cin, поэтому следующее выражение будет иметь вид: cin >> b;. Рекомендуется:Используйте оператор ввода >>, когда необходимо вводить значения, разделенные пробелами в строке. Используйте функцию get() с символьным параметром, если нужно последовательно вводить все символы строки, включая пробелы. Ввод строк со стандартного устройства вводаДля заполнения массива символов можно использовать как оператор ввода (>>), так и методы get() и getline(). Еще один вариант перегруженной функции get() принимает три параметра. Первый параметр — это указатель на массив символов, второй указывает максимальное число символов в строке с учетом концевого нулевого символа, добавляемого автоматически, и третий задает разделитель строк. Если для второго параметра установлено значение 20, функция get() введет 19 символов и оборвет ввод строки, на которую указывал первый параметр, после чего добавит концевой нулевой символ. Третий параметр по умолчанию устанавливается как символ разрыва строки ( \n ). Если этот символ повстречается раньше, чем будет введен последний допустимый символ строки, функция вставит в этом месте концевой нулевой символ, но символ разрыва строки при этом останется в буфере и будет считан очередной функцией ввода. Реализация этого метода ввода показана в листинге 16.6. Листинг 16.6. Использование функции get() для заполнения массива символов 1: // Листинг 16.6. Использование get()c массивом символов 2: #include <iostream.h> 3: 4: int main() 5: { 6: char stringOne[256]; 7: char stringTwo[256]; 8: 9: cout << "Enter string one: "; 10: cin.get(stringOne,256); 11: cout << "stringOne: " << stringOne << endl; 12: 13: cout << "Enter string two: "; 14: cin >> stringTwo; 15: cout << "StringTwo: " << stringTwo << endl; 16: return 0; 17: } Результат: Enter string one: Now is the time stringOne: Now is the time Enter string two: For all good StringTwo: For Анализ: В строках 6 и 7 создаются два массива символов. Строка 9 предлагает пользователю ввести строку, после чего в строке 10 вызывается функция cin.get() с тремя параметрами. Первый параметр ссылается на заполняемый массив символов, второй задает максимально возможное количество символов в строке с учетом нулевого концевого символа ('\0'). Третий параметр не установлен, и используется заданный по умолчанию символ разрыва строки. Пользователь вводит строку Now is the time. Вся строка вместе с концевым нулевым символом помещается в массив stringOne. Вторую строку пользователю предлагается ввести в строке 13, однако в этом случае уже используется оператор ввода. Поскольку он считывает строку до первого пробела, во втором случае в буфер заносится строка Все, что, конечно же, неправильно. Один из способов решения этой проблемы заключается в использовании функции getline(), как показано в листинге 16.7. Листинг 1B.7. Использование функции getline() 1: // Листинг 16.7. Использование getline() 2: #include <iostream.h> 3: 4: int main() 5: { 6: char stringOne[256]; 7: char stringTwo[256]; 8: char stringThree[256]; 9: 10: cout << "Enter string one: "; 11: cin.getline(stringOne,256); 12: cout << "stringOne: " << stringOne << endl; 13: 14: cout << "Enter string two: "; 15: cin >> stringTwo; 16: cout << "stringTwo: " << stringTwo << endl; 17: 18: cout << "Enter string three: "; 19: cin.getline(stringThree,256); 20: cout << "stringThree: " << stringThree << endl; 21: return 0; 22: } Результат: Enter string one: one two three stringOne: one two three Enter string two: four five six stringTwo: four Enter string three: stringThree: five six Анализ: Этот пример требует детального исследования, поскольку возможны некоторые сюрпризы. В строках 6—8 объявляются массивы символов. В строке 10 пользователю предлагается ввести строку текста, которая считывается функцией getline(). Аналогично функции get(), параметры getline() устанавливают буфер ввода и максимальное число символов. Однако, в отличие от get(), функция getline() считывает и удаляет из буфера символ разрыва строки. Как вы помните, функция get() воспринимает символ разрыва строк как разделитель и оставляет его в буфере ввода. В строке 14 пользователю вновь предлагается ввести строку, которая теперь уже считывается оператором ввода. В нашем примере вводится строка four five six, после чего первое слово four присваивается переменной stringTwo. После отображения предложения Enter string three: снова вызывается функция getline(). Так как часть строки five six все еще находится в буфере ввода, она сразу считывается до символа новой строки. Функция getline() завершает свою работу, и строкой 20 выводится значение переменной stringThree. В результате третья строка не вводится в программу, поскольку функция getline() возвращает часть строки, оставшуюся в буфере после операции ввода в строке 15, так как оператор >> считывает строку только до первого пробела и вставляет найденное слово в массив символов. Как вы помните, можно использовать несколько вариантов перегруженной функ- ции-члена get(). В первом варианте она не принимает никаких параметров и возвращает значение полученного символа. Во втором принимается ссылка на односимвольную переменную и возвращается объект istream. В третьей, последней версии в функцию get() устанавливаются массив символов, количество считываемых символов и символ разделения (которым по умолчанию является разрыв строки). Эта версия функции get () возвращает символы в массив либо до тех пор, пока не будет введено максимально возможное количество символов, либо до первого символа разрыва строки. Если функция get() встречает символ разрыва строки, ввод прерывается, а символ разрыва строки остается в буфере ввода. Функция-член getline() также принимает три параметра: буфер ввода, число символов в строке с учетом концевого нулевого символа и символ разделения. Функция getline() действует аналогично описанной выше функции get(), но отличается от последней только тем, что не оставляет в буфере символ разрыва строки. Использование функции cin.ignore()В некоторых случаях возникает необходимость пропустить часть символов строки от начала до достижения конца строки (EOL) или конца файла (EOF). Именно этому и отвечает функция ignore(). Она принимает два параметра: число пропускаемых символов и символ разделения. Например, вызов функции ignore(80, '\n') приведет к пропуску 80 символов, если ранее не будет найден символ начала новой строки. Последний затем будет удален из буфера, после чего функция ignore() завершит свою работу. Использование функции ignore() показано в листинге 16.8. Листинг 16.8. Использование функции ignore() 1: // Листинг 16.8. Использование ignore() 2: #include <iostream.h> 3: 4: int main() 5: { 6: char string0ne[255]; 7: char stringTwo[255]; 8: 9: cout << "Enter string one:"; 10: cin.get(stringOne,255); 11: cout << "String one: " << stringOne << endl; 12: 13: cout << "Enter string two: "; 14: cin.getline(stringTwo,255); 15: cout << "String two: " << stringTwo << endl; 16: 17: cout << "\n\nNow try again...\n"; 18: 19: cin.ignore(255,'\n'); 20: cout << "Enter string two: "; 21: cin.getline(stringTwo,255); 22: 23: cout << "String Two: " << stringTwo<< endl; 24: 25: cout << "Enter string one: "; 26: cin.get(stringOne,255); 27: cout << "String one: " << stringOne<< endl; 28: return 0; 29: } Результат: Enter string one: once upon а time String one: once upon а time Enter string two: String two: Now try again... Enter string one: once upon a time String one: once upon a time Enter string two: there was a String Two: there was a Анализ: В строках 6 и 7 создаются два массива символов. В строке 9 пользователю предлагается ввести строку. В нашем примере вводится строка once upon а time. Ввод завершается нажатием <Enter>. В строке 10 для считывания этой строки используется функция get(), которая присваивает эту строку переменной stringOne и останавливается на символе начала новой строки, оставляя его в буфере ввода. В строке 13 пользователю еще раз предлагается ввести вторую строку, однако в этот раз функция getline() в строке 14 считывает символ разрыва строки, оставшийся в буфере, и сразу же завершает свою работу. В строке 19 пользователю предлагается ввести первую строку. Однако в этом случае для пропуска символа разрыва строки используется функция ignore() (см. в листинге 16.8 строку 23). Таким образом, при вызове getline() строкой 26 буфер ввода пуст, и пользователь получает возможность ввести следующую строку. Функции-члены peek() и putback()Объект cin обладает двумя дополнительными методами, которые могут оказаться весьма полезными. Метод peek()просматривает, но не считывает очередной символ. Метод putback() вставляет символ в поток ввода. Использование этих методов показано в листинге 16.9. Листинг 16.9. Использование функций peek() В putback() 1: // Листинг 16.9. Использование peek() и putback() 2: #include <iostream.h> 3: 4: int main() 5: { 6: char ch; 7: cout << "enter а phrase: "; 8: while ( cin.get(ch) ) 9: { 10: if (ch == '!' ) 11: cin.putback('$'); 12: else 13: cout << ch; 14: while (cin.peek() == '#') 15: cin.ignore(1,'#'); 16: } 17: return 0; 18: } Результат: enter а phrase: Now!is#the!time#for!fun#! Now$isthe$timefor$fun$ Анализ: В строке 6 объявляется символьная переменная ch, а в строке 7 пользователю предлагается ввести строку текста. Назначение этой программы состоит в том, чтобы заменить все встречающиеся во введенной строке восклицательные знаки (!) знаком доллара ($) и удалить все символы (#). Цикл while в теле функции main() программы прокручивается до тех пор, пока не будет возвращен символ конца файла (вводится комбинацией клавиш <Ctrl+C> в Windows или <Ctrl+Z> и <Ctrl+D> в MS DOS и UNIX соответственно). (Не забывайте, что функция cin.get() возвращает 0 в конце файла.) Если текущий символ оказывается восклицательным знаком, он отбрасывается, а в поток ввода функцией putback() возвращается символ $. Если же текущий символ не является восклицательным знаком, он выводится на экран. Если текущий символ оказывается #, то он пропускается функцией ignore(). Указанный подход далеко не самый эффективный способ решения подобных задач (более того, если символ # будет расположен в начале строки, то программа его пропустит). Но наша основная цель состояла в том, чтобы продемонстрировать работу функций putback() и ignore(). Впрочем, их использование достаточно просто и понятно. Примечание:Методы peek() и putback() обычно используются для синтаксического анализа строк. Необходимость в нем возникает, например, при создании компилятора. Ввод данных с помощью coutРанее вы уже использовали объект cout вместе с перегруженным оператором вывода (<<) для выведения на экран строк, чисел и других данных. Этот объект позволяет также форматировать данные, выравнивать столбцы и выводить числовые значения в десятичном и шестнадцатеричном формате. Как это сделать, вы узнаете далее. Очистка буфера выводаВы, вероятно, уже заметили, что использование endl приводит к очистке буфера вывода. Этот оператор вызывает функцию-член flush() объекта cout, которая и осуществляет очистку буфера. Вы можете напрямую вызывать метод flush(), либо вызвав функцию-член flush(), либо написав следующее выражение: cout << flush Указанный метод позволяет явно очистить буфер вывода на тот случай, если не вся информация из него была выведена на экран. Функции-члены объекта coutАналогично тому, как мы обращались к методам объекта cin: get() и getline(), с объектом cout можно использовать функции put() и write(). Функция put() выводит один символ на стандартное устройство вывода. Так как эта функция возвращает ссылку на ostream, а cout является объектом ostream, есть возможность последовательного обращения к функции put() для вывода ряда значений, как и при вводе данных. Реализация этой возможности показана в листинге 16.10. Листинг 16.10. Использование функции put() 1: // Листинг 16.10. Использование put() 2: #include <iostream.h> 3: 4: int main() 5: { 6: cout.put('H' ).put('e' ).put('l').put('l').put('o').put('\n'); 7: return 0; 8: } Результат: Hello Примечание:При запуске этой программы некоторые компиляторы не выведут заданное слово Hello. Если эта проблема коснется и вас, просто пропустите этот листинг и идите дальше. Анализ: Строку 6 можно представить следующим образом: функция cout.put('H') выводит букву H на экран и возвращает объект cout. Оставшуюся часть выражения можно представить следующим образом: cout.put('e').put('l').put('l').put('o').put('\n'); Выводится буква e, после чего остается cout.put('l'). Таким образом, повторяется цикл, на каждом этапе которого выводится следующая бука и возвращается объект cout. После вывода последнего символа ('\n') выполнение функции завершается. Функция write() работает так же, как и оператор ввода (<<), но она принимает параметр, указывающий максимальное количество выводимых символов. Использование этой функции показано в листинге 16.11. Листинг 16.11. Использование функции write() 1: // Листинг 16.11. Использование write() 2: #include <iostream.h> 3: #include <string.h> 4: 5: int main() 6: { 7: char One[] = "One if by land"; 8: 9: 10: 11: int fullLength = strlen(One) 12: int tooShort = fullLength -4; 13: int tooLong = fullLength +6; 14: 15: cout.write(One,fullLength) << "\n"; 16: cout.write(One,tooShort) << "\n"; 17: cout.write(One,tooLong) << "\n"; 18: return 0; 19: } Результат: One if by land One if by One if by land i?! Примечание:На вашем компьютере последняя строка вывода может выглядеть иначе. Анализ: В строке 7 создается массив символов для заданной строки текста. Длина введенного текста присваивается в строке 11 целочисленной переменной fullLength. Установленное значение переменной tooShort меньше этой длины на четыре единицы, а значение переменной tooLong больше на шесть. В строке 15 с помощью функции write() выводится вся строка, поскольку в качестве первого параметра функции задается полная длина текстовой строки. Строкой 16 вновь выводится строка, однако длина ее на четыре символа меньше, что и отражается в выводе. Еще один вывод данных выполняется в строке 17, однако в этом случае функция write() выводит на шесть символов больше. После заданной строки на экране появятся символы, расположенные в ячейках памяти, следующих за ячейками массива символов. Манипуляторы, флаги и команды форматированияПоток вывода поддерживает установку большого количества флагов состояния, определяющих основание чисел (десятичное или шестнадцатеричное), ширину полей вывода и символы, используемые для заполнения полей. Флаг состояния представляет собой байт информации, каждый бит которого имеет специальное предназначение. Установка двоичных флагов более детально рассматривается на занятии 21. Для установки флагов потока ostream можно использовать функции-члены и манипуляторы. Использование функции cout.width()По умолчанию ширина поля вывода автоматически устанавливается такой, чтобы точно вместить все символы строки из буфера вывода. Но с помощью функции width() можно установить точное значение ширины поля вывода. Эта функция вызывается как метод объекта cout, поскольку является его функцией-членом. Функция width() изменяет ширину только следующего поля вывода. Использование этой функции проиллюстрировано в листинге 16.12. Листинг 16.12. Настройка ширины поля вывода 1: // Листинг 16.12. Настройка ширины поля вывода 2: #include <iostream.h> 3: 4: int main() 5: { 6: cout << "Start >"; 7: cout.width(25); 8: cout << 123 << "< End\n"; 9: 10: cout << "Start >"; 11: cout.width(25); 12: cout << 123 << "< Next >"; 13: cout << 456 << "< End\n"; 14: 15: cout << "Start >"; 16: cout.width(4); 17: cout << 123456 << "< End\n"; 18: 19: return 0: 20: } Результат: Start > 123< End Start > 123< Next >456< End Start >123456< End Анализ: Сначала (строки 6—8) число 123 выводится в поле шириной в 25 символов. Ширина поля задается в строке 7. Результат этого форматирования показан в первой строке вывода. Во второй строке вывода значение 123 распечатывается опять же в поле шириной 25, а затем сразу же выводится значение 456. Как видите, установка ширины поля применяется только первый раз, а для второго выражения с объектом cout уже не действует. Таким образом, установки функции width() применяются только к следующему выражению вывода данных. В последней строке вывода видно, что установка ширины поля меньшей размера заносимого в него значения игнорируется программой. В этом случае ширина поля устанавливается равной размерам выводимых данных. Установка символов заполненияОбычно объект cout заполняет пробелами пустые позиции поля, заданные функцией width(), как было показано в приведенном выше примере. Однако иногда возникает необходимость заполнить пустые позиции другими символами, например звездочками (*). Для этого нужно использовать функцию fill(), в параметре которой указать символ заполнения. Использование функции fill() показано в листинге 16.13. Листинг 16.13. Использование функции fill() 1: // Листинг 16.13. Функция fill() 2: 3: #include <iostream.h> 4: 5: int main() 6: { 7: cout << "Start >"; 8: cout.width(25); 9: cout << 123 << "< End\n"; 10: 11: 12: cout << "Start >"; 13: cout.width(25); 14: cout.fill('*'); 15: cout << 123 << "< End\n"; 16: return 0; 17: } Результат: Start > 123< End Start >******************123< End Анализ: Строки 7—9 переписаны из предыдущего листинга. То же можно сказать и о строках 12—15, однако в строке 14 этого листинга используется функция fill('*') для установки символа звездочки (*) в качестве символа заполнения, что Наглядно отражается в выводе программы. Установка флаговДля отслеживания состояния объектов iostream используются флаги. Установку флагов осуществляют с помощью функции setf(), в качестве параметра которой используется одна из стандартных заранее установленных констант. О состоянии объекта говорят в том случае, если режим использования некоторых или всех его данных может изменяться в ходе работы программы. Например, можно изменить режим отображения чисел и запретить вывод на экран нулевых десятичных значений (чтобы число 20,00 выглядело как 20). Для этого вызывается функция setf(ios::showpoint). Область видимости перечисления констант ограничена классом iostream (ios), поэтому необходимо использовать явное указание имени константы с именем класса ios::имяфлага, например ios::showpoint. Для добавления знака "плюс" (+) перед положительными значениями устанавливается флаг ios::showpos. Чтобы изменить выравнивание выводимых данных на экране влево, вправо и по центру поля вывода, используются флаги ios::left, ios::right и ios::interval соответственно. Наконец, установка основания отображаемых числовых значений выполняется с помощью флагов ios::dec (десятичные числа), ios::oct (восьмеричные числа) или ios::hex (шестнадцатеричные числа). Эти флаги можно использовать в паре с оператором ввода (<<). Пример установки флагов показан в листинге 16.4. Листинг 16.14. Установка флагов с ппмощью setf 1: // Листинг 16.14. Использование функции setf 2: #include <iostream.h> 3: #include <iomanip.h> 4: 5: int main() 6: { 7: const int number = 185; 8: cout << "The number is " << number << endl; 9: 10: cout << "The number is " << hex << number << endl; 11: 12: cout.setf(ios::showbase); 13: cout << "The number is " << hex << number << endl; 14: 15: cout << "The number is " ; 16: cout.width(10); 17: cout << hex << number << endl; 18: 19: cout << "The number is " ; 20: cout.width(10); 21: cout.setf(ios::left); 22: cout << hex << number << endl; 23: 24: cout << "The number is " ; 25: cout.width(10); 26: cout.setf(ios::internal); 27: cout << hex << number << endl; 28: 29: cout << "The number is:" << setw(10) << hex << number << endl; 30: return 0; 31: } Результат: The number is 185 The number is b9 The number is 0xb9 The number is 0xb9 The number is 0xb9 The number is 0x b9 The number is 0x b9 Анализ: В строке 7 целочисленная константа number инициируется значением 185, которое выводится на экран в строке 8. Это же значение выводится строкой 10, однако, поскольку здесь задействован манипулятор hex, оно отображается в шестнадцатеричном формате как b9. (Числу b в шестнадцатеричном коде соответствует 11 в десятичном. Умножение 11 на 16 дает 176. Добавив 9, получаем десятичное значение 185.) В строке 12 установлен флаг showbase, что приводит к добавлению префикса 0x ко всем шестнадцатеричным значениям. В строке 16 ширина поля устанавливается равной 10. Поэтому выводимое значение сдвинуто вправо. В строке 20 ширина также устанавливается равной 10, однако применяется выравнивание влево. Этот момент хорошо виден в выводе программы. В строке 25 ширина остается равной 10, однако применяется выравнивание по ширине поля. Поэтому 0x вводится по левому краю поля, а b9 — по правому. Наконец, в строке 29 повторяются те же установки, но в этот раз функция setw() используется не в отдельной строке, а в паре с оператором вывода (<<). Результат получается тот же. Сравнение потоков и функции printf()Большинство версий компиляторов C++ включают также стандартные библиотеки ввода-вывода языка С, позволяющие использовать для этого функцию printf(). Хотя использовать printf() немного проще, чем cout, применять ее не желательно. Функция printf() не обеспечивает должного контроля за типами данных, поэтому можно легко ошибиться и отобразить число как символ или символ как число. Кроме того, функция printf() не поддерживает классы, поэтому ее трудно использовать для вывода данных объектов классов. Приходится задавать каждый член класса для p г i n t f () в отдельности. С другой стороны, эта функция значительно упрощает форматирование выводимых данных, так как позволяет вставлять спецификаторы форматирования в качестве параметров функции. Поскольку функция printf() все еще эффективно применяется в некоторых программах и пользуется популярностью у многих программистов, этот раздел посвятим краткому обзору ее использования. Для использования функции printf() необходимо включить в программу файл заголовка stdio.h. В самой простой форме функция printf() принимает в качестве параметра строку для форматированного вывода в виде текста, взятого в кавычки. Перед строкой могут быть установлены самые различные наборы спецификаторов форматирования. В табл. 16.1 показаны наиболее часто используемые спецификаторы преобразований типов, начинающиеся всегда с символа %. Таблица 16.1. Спецификаторы преобразования типов  Каждый спецификатор преобразования может также дополняться установкой общего числа знаков в выводимом значении и числа знаков после десятичной запятой. Эта установка имеет вид десятичного значения с плавающей точкой, где символы слева от точки устанавливают общее число знаков в выводимых значениях, а символы справа — число знаков после запятой. Например, спецификатор %5d задает вывод целочисленного значения длиной 5 знаков, а %15.5f — вывод числа с плавающей запятой общей длиной в 15 знаков, пять из которых составляют дробную часть. Различные способы использования printf() показаны в листинге 16.15. Листинг 16.15. Вывод данных с помощью фцнкции printf() 1: #include <stdio.h> 2: int main() 3: { 4: printf("%s","hello world\n"); 5: 6: char *phrase = "Hello again!\n"; 7: printf("%s",phrase); 8: 9: int x = 5; 10: printf("%d\n",x); 11: 12: char *phraseTwo = "Here's some values: "; 13: char *phraseThree = " and also these: "; 14: int у = 7, z = 35; 15: long longVar = 98456; 16: float floatVar = 8.8f; 17: 18: printf("%s %d %d %s %ld %f\n",phraseTwo,y,z, phraseThree,longVar,floatVar); 19: 20: char *phraseFour = "Formatted: "; 21: printf("%s %5d %10d %10.5f\n",phraseFour,y,z,floatVar); 22: return 0; 23: } Результат: hello world Hello again! 5 Here's some values: 7 35 and also these: 98456 8.800000 Formatted: 7 35 8.800000 Анализ: Первый раз функция printf() вызывается в строке 4 и имеет стандартную форму: за именем функции printf следует спецификатор преобразования (в данном случае %s) и константная строка в кавычках, выводимая на экран. Спецификатор %s указывает, что в данный момент выводится текстовая' строка, указанная далее, — "hello world". Второй вызов функции printf в строке 7 аналогичен первому, но в данном случае вместо константной строки, заключенной в кавычки, используется указатель типа char. В третьем вызове printf() в строке 10 используется спецификатор вывода целочисленного значения, хранимого в переменной x. Еще более сложным оказывается четвертый вариант вызова функции printf(), показанный в строке 18. Здесь выводится сразу шесть значений. Каждому приведенному спецификатору отвечает свое значение, отделенное от остальных с помощью запятых. Наконец, в строке 21 в уже хорошо известной вам функции printf() используются спецификаторы форматирования, определяющие длину и точность выводимых значений. Многие считают, что форматирование вывода данных с помощью спецификаторов функции printf() намного проще, чем с помощью манипуляторов объекта cout. Ранее уже отмечались основные недостатки функции printf() — отсутствие строгого контроля за типами данных и невозможность объявления этой функции как друга или метода класса. Поэтому при необходимости распечатать данные различных членов класса нужно использовать явно заданные методы доступа к членам класса. Обобщение методов управления выводом данных в программах на C++ Для форматирования вывода данных в C++ можно использовать комбинации специальных символов, манипуляторов и флагов. В выражениях с объектом cout используются следующие специальные символы: \n — новая строка; \r — возврат каретки; \t — табуляция; \\ — обратный слеш; \ddd (число в восьмеричном коде) — символ ASCII; \a — звуковой сигнал (звонок). Пример выражения вывода строки: cout << "\aAn error occured\t" Указанное выражение не только выводит сообщение об ошибке на экран компьютера. но подает предупреждающий звуковой сигнал и выполняет переход к следующей позиции табуляции. С оператором cout используются также манипуляторы. Однако для использования большинства манипуляторов нужно включить в программу файл iomanip.h. Далее вашему вниманию представлен список манипуляторов, не требующих включения iomanip.h: flush — очищает буфер вывода; endl — вставляет символ разрыва строки и очищает буфер вывода; oct — устанавливает восьмеричное основание для выводимых чисел; dec — устанавливает десятичное основание для выводимых чисел; hex — устанавливает шестнадцатеричное основание для выводимых чисел. А теперь приведем набор манипуляторов, для которых необходимо включение iomanip.h: setbase (основание) — устанавливает основание для выводимых чисел (0 = десятичная, 8 = восьмеричная, 10 = десятичная, 16 = шестнадцатеричная); setw (ширина) — устанавливает минимальную ширину поля вывода; setfill (символ) — устанавливает символ заполнения незанятых позиций поля вывода; setprecision (точность) — устанавливает число знаков после плавающей запятой; setiosflags (флаг) —устанавливает один или несколько флагов; resetiosflags (флаг) — сбрасывает один или несколько флагов. Например, в строке cout << setw(12) << setfill ("#') << hex << x <<endl; устанавливается ширина поля в 12 знаков, символ заполнения #, восьмеричное основание выводимых чисел, после чего выводится значение переменной x, добавляется символ разрыва строки и очищается буфер. Все манипуляторы, за исключением flush, endl и setw, остаются включенными на протяжении всей работы программы, если, конечно, не будут сделаны другие установки. Установка манипулятора setw отменяется сразу же после текущего вывода с объектом cout. С манипуляторами setiosflags и resetiosflags могут использоваться следующие ювнфлаги: iоs::left — выравнивает данные по левому краю поля вывода; ios::right — выравнивает данные по правому краю поля вывода; ios::interval — выравнивает данные по ширине поля вывода; ios::dec — выводит данные в десятичном формате; ios::oct — выводит данные в восьмеричном формате; ios::hex — выводит данные в шестнадцатеричном формате; ios::showbase — добавляет префикс 0x к шестнадцатеричным значениям и О к восьмеричным значениям; ios::showpoint — заполняет нулями недостающие знаки в значениях заданной длины; ios::uppercase — отображает в верхнем регистре шестнадцатеричные и экспоненциальные значения; ios::showpos — добавляет знак '+' перед положительными числами; ios::scientific — отображает числа с плавающей запятой в экспоненциальном представлении; ios::fixed — отображает числа с плавающей запятой в шестнадцатеричном представлении. Дополнительную информацию можно получить из файла ios.h или из справочной системы компилятора. Использование файлов для ввода и вывода данныхПотоки C++ обеспечивают универсальные методы обработки данных, поступающих с клавиатуры или диска, а также выводимых на экран и диск. В любом случае можно использовать либо операторы ввода и вывода, либо другие стандартные функции и манипуляторы. Дальнейшие разделы главы посвящены операциям открытия и закрытия файлов, которые сопровождаются созданием объектов ifstream и ofstream. Объекты ofstreamОбъекты, создаваемые для считывания или записи данных в файл, называются ofstream. Они являются производными от уже знакомого вам класса iostream. Чтобы приступить к записи в файл, нужно сначала создать объект ofstream, а затем связать его с определенным файлом на диске. Использование объектов ofstream требует включения в программу файла заголовка fstream.h. Примечание:Поскольку fstream содержит в себе iostream.h, нет необходимости в отдельном включении файла iostream.h. Состояния условийОбъектами iostream поддерживаются флаги, отражающие состояние ввода и вывода. Значение каждого из этих флагов можно проверить с помощью функций, возвращающих TRUE или FALSE: eof(), bad(), fail() и good(). Функция eof() возвращает значение TRUE, если в объекте iostream встретился символ EOF (end of file — конец файла). Функция bad() возвращает значение TRUE при попытке выполнить ошибочную операцию. Функция fail() возвращает значение TRUE каждый раз, когда это же значение возвращает функция bad(), а также в тех случаях, когда операция невыполнима в данных условиях. Наконец, функция good() возвращает значение TRUE, когда все идет хорошо, т.е. все. остальные функции возвращают значение FALSE. Открытие файлов для ввода-выводаДля открытия файла myfile.cpp с помощью объекта ofstream нужно объявить экземпляр этого объекта, передав ему в качестве параметра имя файла: ofstream fout("myfile.cpp"); Открытие файла для ввода выполняется аналогичным образом, за тем исключением, что для этого используется объект ifstream: ifstream fin("myfile.cpp"); Обратите внимание, что в выражениях задаются имена объектов fout и fin, которые можно использовать так же, как объекты cout и cin соответственно. Очень важным методом, используемым в файловых потоках, является функция-член close(). Каждый создаваемый вами объект файлового потока открывает файл для чтения или записи (или и для того и другого сразу). По завершении работы файл необходимо закрыть с помощью функции close(), чтобы впоследствии не повредить его и записанные в нем данные. После связывания объектов потока с соответствующими файлами их можно использовать так же, как остальные объекты ввода-вывода. Пример использования объектов для обмена данными с файлами показан в листинге 16.16. Листинг 16.16. Открытие файла для чтения и записи 1: #include <fstream.h> 2: int main() 3: { 4: char fileName[80]; 5: char buffer[255]; // для ввода данных пользователем 6: cout << "File паше: "; 7: cin >> fileName; 8: 9: ofstream fout(fileName); // открытие файла для записи 10: fout << "This line written directly to the file...\n"; 11: cout << "Enter text for the file: "; 12: cin.ignore(1,'\n'); // пропускает символ разрыва строки после имени файла 13: cin.getline(buffer,255); // принимает данные, введенные пользователем, 14: fout << buffer << "\n"; // и записывает их в файл 15: fout.close(); // закрывает файл, после чего его вновь можно открыть 16: 17: ifstream fin(fileName); // открывается тот же файл для чтения 18: cout << "Here's the contents of the file:\n"; 19: char ch; 20: while (fin.get(ch)) 21: cout << ch; 22: 23: cout << "\n*** End of file contents.***\n"; 24: 25: fin.close(); // не забудь закрыть файл в конце программы 26: return 0; 27: } Результат: File name: test1 Enter text for the file: This text is written to the file! Here's the contents of the file: This line written directly to the file... This text is written to the file! ***End of file contents.*** Анализ: В строке 4 создается массив для записи имени файла, а в строке 5 — еще один массив для временного хранения информации, вводимой пользователем. В строке 6 пользователю предлагается ввести имя файла, которое записывается в массив fileName. В строке 9 создается объект ofstream с именем fout, который связывается с введенным ранее именем файла. В результате происходит открытие файла. Если файл с таким именем уже существует, содержащаяся в нем информация будет замещена. Строкой 10 введенный текст записывается прямо в файл, а в строке 11 пользователю вновь предлагается ввести новый текст. Символ разрыва строки, оставшийся в буфере после ввода имени файла, удаляется строкой 12, после чего все введенные пользователем данные записываются в массив в строке 13. Введенный текст записывается в файл вместе с символом разрыва строки, а затем в строке 15 этот файл закрывается. В строке 17 файл открывается заново, но в этот раз для чтения, и его содержимое посимвольно вводится в программу в строках 20—21. Настройка открытия файла объектом ofstreamПо умолчанию при связывании объекта ofstream с именем файла создается новый файл с указанным именем, если таковой не существует, или удаляется содержимое уже существующего файла с таким же именем. Чтобы изменить установки по умолчанию, используется второй аргумент конструктора объекта ofstream. Для второго аргумента можно устанавливать следующие константные значения: • ios::app — добавляет данные в конец файла вместо удаления всего содержимого файла; • ios::ate — переводит точку ввода в конец файла, но у вас есть возможность вводить новые данные в любом месте файла; • ios::trunc — устанавливается по умолчанию; полностью удаляет (отбрасывает) текущее содержимое файла; • ios::nocreate — если файл не существует, операция открытия не выполняется; • ios::noreplace — если файл уже существует, операция открытия не выполняется. Имена констант являются аббревиатурами выполняемых действий: app — apend (добавить), ate — at end (в конец), trunc — truncate (отбросить) и т.п. Листинг 16.17 является модификацией листинга 16.16 с установкой опции добавления данных в файл при его повторном открытии. Листинг 16.17. Добавление данных в конец файла 1: #include <fstream.h> 2: int main() // возвращает 1 в случае ошибки 3: { 4: char fileName[80]; 5: char buffer[255]; 6: cout << "Please re-enter the file name: "; 7: cin >> fileName; 8: 9: ifstream fin(fileName); 10: if (fin) // файл уже существует? 11: { 12: cout << "Current file contents:\n"; 13: char ch; 14: while (fin.get(ch)) 15: cout << ch; 16: cout << "\n***End of file contents.***\n"; 17: } 18: fin.close(); 19: 20: cout << "\nOpening " << fileName << " in append mode...\n"; 21: 22: ofstream fout(fileName,ios::app); 23: if (!fout) 24: { 25: cout << "Unable to open " << fileName << " for appending.\n"; 26: return(1); 27: } 28: 29: cout << "\nEnter text for the file: "; 30: cin.ignore(1,'\n'); 31: cin.getline(buffer,255); 32: fout << buffer << "\n"; 33: fout.close(); 34: 35: fin.open(fileName); // переопределение существующего объекта fin! 36: if (!fin) 37: { 38: cout << "Unable to open " << fileName << " for reading.\n"; 39: return(1); 40: } 41: cout << "\nHere's the contents of the file:\n"; 42: char ch; 43: while (fin.get(ch)) 44: cout << ch; 45: cout << "\n***End of file contents.***\n"; 46: fin.close(); 47: return 0; 48: } Результат: Please re-enter the file name: test1 Current file contents: This line written directly to the file... This text is written to the file! ***End of file contents.*** Opening test1 in append mode... Enter text for the file: More text for the file! Here's the contents of the file: This line written directly to the file... This text is written to the file! More text for the file! ***End of file contents.*** Анализ: Пользователю вновь предлагается ввести имя файла, после чего в строке 9 создается объект файлового потока ввода. В строке 10 проверяется наличие на диске указанного файла и, если он уже существует, его содержимое выводится на экран строками 12—16. Обратите внимание на то, что выражение if(fin) аналогично if(fin. good()). Файл ввода закрывается и снова открывается, однако теперь в режиме добавления (строка 22). После этого открытия (как, впрочем, после каждого открытия) выполняется проверка правильности открытия файла. В этом случае условие if(!fout) подобно условию if (fout.fail()). Пользователю предлагается ввести текст, после чего в строке 33 файл закрывается. Наконец, как и в листинге 16.16, файл открывается в режиме чтения, но в этом случае не нужно повторно объявлять объект fin. Он просто связывается с тем же именем файла. После проверки правильности открытия файла в строке 36 содержимое файла выводится на экран и он окончательно закрывается. Рекомендуется:Постоянно проверяйте правильность открытия файла. Повторно используйте уже существyющиe oбъeкты ifstream и ofstream. Закрывайте все объекты fstream по завершении работы с ними. Не рекомендуется:Не пытайтесь закрыть или переопределить объекты cin и cout. Двоичные и тектовые файлыНекоторые операционные системы, например DOS, различают текстовые и двоичные файлы. В первых все данные хранятся в виде текста (в кодах ASCII). Числовые значения, например 54321, хранятся в виде строки ('5','4','3','2','1'). Возможно это не совсем удобно, однако упрощает считывание информации многими простыми программами для DOS. Чтобы помочь файловой системе отличить текстовый формат файла от двоичного, язык программирования C++ предоставляет флаг ios::binary. Во многих системах этот флаг игнорируется, поскольку все данные хранятся в двоичном формате. А в некоторых закрытых системах этот флаг вообще запрещен и не поддается компиляции! В двоичных файлах могут храниться не только числа и строки, но и целые информационные структуры. Весь блок данных можно вывести сразу, используя метод write() объекта fstream. Записав данные с помощью write(), можно возвратить эти данные обратно с помощью метода read(). В качестве параметра эти функции-члены ожидают получить указатель на символ, поэтому перед использованием функции необходимо привести адрес класса к указателю на строку символов. Второй аргумент этих функций задает количество записываемых символов. Это значение можно определить с помощью функции sizeof(). Запомните, что записываются данные, а не методы. Соответственно и считываются только данные. В листинге 16.18 показано, как записать содержимое класса в файл. Листинг 16.18. Запись класса в файл 1: #include <fstream.h> 2: 3: class Animal 4: { 5: public: 6: Animal(int weight, long days):itsWeight(weight), itsNumberDaysAlive(days){ } 7: ~Animal(){ } 8: 9: int GetWeight()const { return itsWeight; } 10: void SetWeight(int weight) { itsWeight = weight; } 11: 12: long GetDaysAlive()const { return itsNumberDaysAlive; } 13: void SetDaysAlive(long days) { itsNumberDaysAlive = days; } 14: 15: private: 16: int itsWeight; 17: long itsNumberDaysAlive; 18: }; 19: 20: int main() // returns 1 on error 21: { 22: char fileName[80]; 23: 24: 25: cout << "Please enter the file name: ": 26: cin >> fileName; 27: ofstream fout(fileName,ios::binary); 28: if (!fout) 29: { 30: cout << "Unable to open " << fileName << " for writing.\n"; 31: return(1); 32: } 33: 34: Animal Bear(50,100); 35: fout.write((char*) &Bear,sizeof Bear); 36: 37: fout.close(); 38: 39: ifstream fin(fileName,ios::binary); 40: if (!fin) 41: { 42: cout << "Unable to open " << fileName << " for reading.\n"; 43: return(1); 44: } 45: 46: Animal BearTwo(1,1); 47: 48: cout << "BearTwo weight: " << BearTwo.GetWeight() << endl; 49: cout << "BearTwo days: " << BearTwo.GetDaysAlive() << endl; 50: 51: fin.read((char*) &BearTwo, sizeof BearTwo); 52: 53: cout << "BearTwo weight: " << BearTwo.GetWeight() << endl; 54: cout << "BearTwo days: " << BearTwo.GetDaysAlive() << endl; 55: fin.close(); 56: return 0; 57: } Результат: Please enter the file name: Animals BearTwo weight: 1 BearTwo days: 1 BearTwo weight: 50 BearTwo days: 100 Анализ: В строках 3-18 объявляется класс Animal. В строках 22-32 создается файл, который открывается для вывода в двоичном режиме. В строке 34 создается объект Animal со значениями переменных-членов itsWeight = 50 и itsNumberDaysAlive = 100. В следующей строке данные объекта заносятся в файл. В строке 37 файл закрывается, после чего повторно открывается для чтения в двоичном режиме в строке 39. Создается второй объект Animal, значения обоих переменных-членов которого равны 1. В строке 51 данные из файла считываются в новый объект Animal, замещая собой текущие значения объекта. Установка параметров ввода-вывода с помощью коммандной строкиМногие операционные системы, такие как DOS и UNIX, позволяют пользователю выполнять установки некоторых параметров при запуске программы. Эти установки называются опциями командной строки и, как правило, отделяются друг от друга пробелами, например: SomeProgram Param1 Param2 Param3 Эти параметры не передаются напрямую в функцию main(). Вместо этого функция main() программы может принимать два других параметра. Первый — это целочисленное значение, указывающее число аргументов командной строки с учетом имени программы. Поэтому минимальное значение этого параметра равно единице (задается по умолчанию). Для показанной выше командной строки значение параметра будет равно четырем. (Имя SomeProgram плюс три параметра в сумме дают четыре аргумента командной строки.) Второй параметр, передаваемый функции main(), — это массив указателей на строки символов. Так как имя массива является постоянным указателем на первый элемент массива, можно объявить этот аргумент как указатель на указатель типа char, указатель на массив символов или массив массивов символов. Обычно первый аргумент называется argc (argument count — количество аргументов), однако вы можете присвоить ему любое имя, которое вам нравится. Второй аргумент зачастую называется argv (argument vector — вектор аргументов), однако это имя также не является обязательным. Как правило, с помощью argc проверяется количество установленных аргументов коммандной строки, после чего для доступа к ним используется argv. Обратите внимание: argv[0] — это имя программы, а argv[1] — первый аргумент коммандной строки. Если программа принимает в качестве аргументов два числовых значения, нужно будет преобразовать их в строки. На занятии 21 вы узнаете, как выполнить это преобразование с помощью средств, предоставляемых стандартными библиотеками функций. В листинге 16.19 показан пример использования аргументов командной строки. Листинг 16.19. Использование аргументов командной строки 1: #include <iostream.h> 2: int main(int argc, char *>argv) 3: { 4: cout << "Received " << argc << " arguments...\n"; 5: for (int i=0; i<argc; i++) 6: cout << "argument " << i << ": " << argv[i] << endl; 7: return 0; 8: } Результат: TestProgram Teach Yourself C++ In 21 Days Received 7 arguments... argument 0: TestProgram.exe argument 1: Teach argument 2: Yourself argument 3: C++ argument 4: In argument 5: 21 argument 6: Days Примечание: Вам придется либо запустить этот код из командной строки DOS, либо установить параметры командной строки с помощью компилятора (см. документацию компилятора). Анализ: В функции main() объявляются два аргумента: argc — целочисленное значение, указывающее число аргументов командной строки, и argv — указатель на массив строк. Каждый элемент этого массива представляет аргумент командной строки. Обратите внимание, argv можно также объявить как char *argv[] или char[][]. Программист может выбрать вариант, который ему более по душе. Даже если в программе этот аргумент будет объявлен как указатель на указатель, для доступа к определенным элементам можно воспользоваться индексом смещения элемента от начала массива. В строке 4 массив argv используется для вывода числа установленных аргументов командной строки. Всего их оказалось семь, включая имя программы. В строках 5 и 6 задается цикл for, который выводит значения всех аргументов командной строки по отдельности, обращаясь к ним по имени массива argv с указанием смещения [i]. Для вывода значений аргументов используется объект cout. Листинг 16.20 является переписанной версией листинга 16.18, в которой имя файла задается как аргумент командной строки. Листинг 16.20. Использование аргументов командной строки 1: #include <fstream.h> 2: 3: class Animal 4: { 5: public: 6: Animal(intweight, long days):itsWeight(weight), itsNumberDaysAlive(days)( } 7: ~Animal(){ } 8: 9: int GetWeight()const { return itsWeight; } 10: void SetWeight(int weight) { itsWeight = weight; } 11: 12: long GetDaysAlive()const { return itsNumberDaysAlive; } 13: void SetDaysAlive(long days) { itsNumberDaysAlive = days; } 14: 15: private: 16: int itsWeight; 17: long itsNumberDaysAlive; 18: }; 19: 20: int main(int argc, char *argv[]) // возвращает 1 в случае ошибки 21: { 22: if (argc != 2) 23: { 24: cout << "Usage: " << argv[0] << " <filename>" << endl; 25: return(1); 26: } 27: 28: ofstream fout(argv[1],ios::binary); 29: if (!fout) 30: { 31: cout << "Unable to open " << argv[1] << " for writing.\n"; 32: return(1); 33: } 34: 35: Animal Bear(50,100); 36: fout.write((char*) &Bear,sizeof Bear); 37: 38: fout.close(); 39: 40: ifstream fin(argv[1],ios::binary); 41: if (!fin) 42: { 43: cout << "Unable to open " << argv[1] << " for reading.\n"; 44: return(1); 45: } 46: 47: Animal BearTwo(1,1); 48: 49: cout << "BearTwo weight: " << BearTwo.GetWeight() << endl; 50: cout << "BearTwo days: " << BearTwo.GetDaysAlive() << endl; 51: 52: fin.read((char*) &BearTwo, sizeof BearTwo); 53: 54: cout << "BearTwo weight: " << BearTwo.GetWeight() << endl; 55: cout << "BearTwo days: " << BearTwo.GetDaysAlive() << endl; 56: fin.close(); 57: return 0; 58: } Результат: BearTwo weight: 1 BearTwo days: 1 BearTwo weight: 50 BearTwo days: 100 Анализ: Объявление класса Animal аналогично представленному в листинге 16.18. Однако в этом случае пользователю не предлагается ввести имя файла, а используется аргумент командной строки. В строке 2 объявляется функция main(), принимающая два параметра: количество аргументов командной строки и указатель на массив символов, в котором сохраняются аргументы командной строки. В строках 22—26 проверяется, соответствует ли установленное число аргументов ожидаемому. Если пользователь забыл ввести имя файла, то выводится сообщение об ошибке: Usage TestProgram <имя файла> После этого программа завершает свою работу. Обратите внимание, что при выводе имени программы используется не константная строка, а значение argv[0] . Данное выражение будет правильно выводить имя программы, даже если оно будет изменено после компиляции. В строке 28 программа пытается открыть двоичный файл с указанным именем. Однако, вместо того чтобы копировать и хранить имя файла во временном массиве, как это было в листинге 16.18, его можно задать в командной строке и затем возвратить из argv[1 ]. Точно так же имя файла возвращается в строке 40, где этот файл открывается для ввода данных, и в строках 25 и 31 при формировании сообщений об ошибках открытия файлов. РезюмеСегодня вы познакомились с потоками и глобальными объектами cout и cin. Основное предназначение объектов istream и ostream состоит в инкапсулировании буферизированого ввода и вывода данных на стандартные устройства ввода-вывода. В каждой программе создается четыре стандартных потоковых объекта: cout, cin, cerr и clog. Однако в большинстве операционных систем эти объекты можно переадресовывать. Объект cin класса istream используется для ввода данных обычно вместе с перегружаемым оператором ввода (>>). Объект cout класса ostream используется для вывода данных в комбинации с оператором вывода (<<). Стандартные объекты ввода-вывода включают много других функций-членов, например get() и put(). Поскольку эти методы возвращают ссылки на объект потока, несколько вызовов функций можно объединять в одном выражении. Для настройки работы объектов потока используются манипуляторы. С их помощью можно устанавливать не только опции форматирования и отображения, но и многие другие атрибуты объектов потока. Обмен данными с файлами осуществляется с помощью классов fstream, производных от класса iostream. Кроме обычных операторов ввода и вывода, эти классы поддерживают использование функций read() и write(), позволяющих считывать и записывать целые объекты в двоичные файлы. Вопросы и ответыКак определить, когда использовать операторы ввода и вывода, а когда другие функции-члены классов потока? В целом операторы ввода и вывода проще в использовании, поэтому в большинстве случаев лучше обращаться именно к ним. В некоторых других случаях, когда эти операторы не справляются со своей работой (например, при вводе строки из слов, разделенных пробелами), можно прибегнуть к использованию других функций. Какое отличие между cerr и clog? Объект cerr не буферизируется? Другими словами, все данные, поступающие в cerr, немедленно выводятся на экран. Это отлично подходит для вывода ошибок на экран, однако дорого обойдется при записи регистрационной информации на диск. Объект clog буферизирует свой вывод, поэтому в последнем случае может быть более эффективным. Зачем создавать потоки, если отлично работает функция printf()? Функция printf() не контролирует строго типы выводимых данных, чего требуют стандарты C++. Кроме того, эта функция не поддреживает работу с классами. Когда следует применять метод putback()? Этот метод весьма эффективен в тех случаях, когда для определения соответствия введенного символа установленным ограничениям используется одна операция считывания, а для записи символа в буфер используются некоторые другие операций. Наиболее часто это находит применение при анализе синтаксических конструкций файла, например при создании компиляторов. Когда следует использовать функцию ignore()? Наиболее часто она используется после функции get(). Поскольку последняя оставляет в буфере символ разрыва строки, иногда за вызовом функции get() следует вызов ignore(1, '\n');. Эта функция, как и putback(), используется, как правило, при синтаксическом разборе файлов. Мои друзья используют в своих программах на C++ функцию printf(). Можно ли и мне ее использовать? Конечно же, можно. Однако, хотя эта функция более проста в использовании, вы утратите строгий контроль за типами файлов и затрудните работу с объектами классов. КоллоквиумВ этом разделе предлагаются вопросы для самоконтроля и укрепления полученных знаний и приводится несколько упражнений, которые помогут закрепить ваши практические навыки. Попытайтесь самостоятельно ответить на вопросы теста и выполнить задания, а потом сверьте полученные результаты с ответами в приложении Г. Не приступайте к изучению материала следующей главы, если для вас остались неясными хотя бы некоторые из предложенных ниже вопросов. Контрольные вопросы1. Что такое оператор ввода и как он работает? 2. Что такое оператор вывода и как он работает? 3. Перечислите три варианта перегруженной функции cin.get() и укажите основные их отличия. 4. Чем cin.read() отличается от cin.getline()? 5. Какая ширина устанавливается по умолчанию для вывода длинных целых чисел с помощью оператора вывода? 6. Какое значение возвращает оператор вывода? 7. Какой параметр принимается конструктором объекта ofstream? 8. Что устанавливает аргумент ios::ate? Упражнения1. Напишите программу, использующую четыре стандартных объекта класса iostream — cin, cout, cerr и clog. 2. Напишите программу, предлагающую пользователю ввести свое полное имя с последующим выводом этого имени на экран. 3. Перепишите листинг 16.9, отказавшись от использования методов putback() и ignore(). 4. Напишите программу, считывающую имя файла в качестве аргумента командной строки и открывающую файл для чтения. Разработайте алгоритм анализа всех символов, хранящихся в файле, и выведите на экран только текстовые символы и знаки препинания (пропускайте все непечатаемые символы). Закройте файл перед завершением работы программы. 5. Напишите программу, которая выведет заданные аргументы командной строки в обратном порядке, отбросив имя программы. День 17-й. Пространства именОдним из дополнений стандарта ANSI C++ является возможность использования программистами пространств имен, позволяющих избежать конфликтов имен при работе с большим количеством библиотек. Сегодня вы узнаете: • Какие функции и классы вызываются по имени • Как создаются пространства имен • Как используются пространства имен • Как используется стандартное пространство имен std ВведениеКонфликты имен возникают из-за недомолвок между разработчиками С и C++. Стандарты ANSI предлагают способ решения этой проблемы с помощью пространств имен (namespaces). Однако следует проявлять осторожность, так как не все компиляторы поддерживают это средство. Конфликт имен возникает в тех случаях, когда в двух частях программы находятся подобные имена с совпадающими областями видимости. Наиболее часто это случается при использовании различных пакетов библиотек. Например, в разных библиотеках классов контейнеров часто объявляется и используется класс List. (Более подробно классы контейнеров рассматриваются на занятии 19ч) Тот же класс List используется и в библиотеках окон. Предположим, необходимо реализовать набор окон для приложения и применить класс List из библиотеки классов контейнеров. Для этого объявляется экземпляр класса List из библиотеки окон, чтобы поддержать работу окон приложения. Однако в результате может оказаться, что его функции-члены недоступны, поскольку компилятор автоматически связал объявленный класс с аналогичным классом List из стандартной библиотеки классов контейнеров, который вам вовсе не был нужен. ' Пространство имени используется для разделения глобальных пространств имен, чтобы исключить или, по крайней мере, уменьшить количество конфликтов имен. Пространства имен весьма похожи на классы, в том числе и синтаксисом. Объявленные внутри пространства имени элементы принадлежат к этому пространству, но являются открытыми. Пространства имен могут взаимно перекрываться. Соответственно и функции могут объявляться как внутри, так и за пределами пространств имен. В последнем случае при вызове такой функции следует явно указывать соответствующее пространство имен. Вызов по имени функций и классовВ процессе анализа кода программы и создания списка имен функций и переменных компилятор проверяет программу на наличие конфликтов имен. Конфликты, которые сам компилятор решить не в состоянии, могут устраняться компоновщиком. Компилятор не в состоянии проверить конфликты имен в единицах трансляции (например, файлах объектов). Эта задача решается компоновщиком приложений. Поэтому компилятор не покажет даже предупреждение. Довольно часто компоновщик выдает сообщение об ошибке Identifier multiply defined (множественное объявление идентификатора). Это сообщение появится в том случае, если вы попытаетесь описать идентификаторы с одинаковыми именами и перекрывающимися областями видимости. Если два идентификатора будут объявлены с общими областями видимости в одном файле источника, то об ошибке сообщит компилятор. Сообщение об ошибке поступит от компоновщика при попытке скомпилировать и связать следующий код программы: // файл first.сpp int integerValue = 0; int main( ) { int integerValue - 0 ; // ... return 0 ; }; // файл second.cpp int integerValue = 0; // конец second.cpp Компоновщик выдает сообщение in second.obj: integerValue already defined in first.obj (integerValue из second.obj уже объявлен в first.obj). Если бы эти имена располагались в разных областях видимости, то компилятор и компоновщик не имели бы ничего против. Может поступить и такое предупреждение от компилятора: identifier hiding (идентификатор скрыт). Суть его состоит в том, что в файле first.cpp объявление переменной integerValue в функции main() скрывает глобальную переменную с таким же именем. Чтобы использовать в функции main() глобальную переменную integerVaalue, объявленную за пределами main(), необходимо явно указать глобальность этой переменной с помощью оператора видимости (::). Так, в следующем примере значение 10 будет присвоено глобальной переменной integerValue, а не переменной с таким же именем, объявленной внутри main(): // файл first.cpp int integerValue = 0; int main() { int integerValue = 0; ::integerValue = 10; //присваиваем глобальной переменной integerValue // ...return 0 ; }; // файл second.cpp int integerValue = 0; // конец second.cpp Примечание:Обратите внимание на использование оператора видимости (: ), который необходим для указания глобальности переменной integerValue в том случае, если в функции была объявлена переменная с таким же именем. Проблема с двумя глобальными переменными, объявленными за пределами какой-либо функции, заключается в том, что они имеют одинаковые имена и перекрывающиеся области видимости и это вызывает ошибку в работе компоновщика. Новый термин:Под видимостью объекта, который может быть переменной, классом или функцией, понимают ту часть программы, в которой данный объект может использоваться. Например, переменная, объявленная и определенная за пределами всякой функции, имеет файловую, или глобальную область видимости. Ее видимость распространяется от точки объявления до конца файла. Переменная, имеющая модульную, или локальную область видимости, объявляется внутри программного модуля. Чаще всего локальные переменные объявляются в теле функции. Ниже показаны примеры объектов с различными областями видимости: int globaiScopeInt = 5; void f() { int localScopeInt = 10; } int main() { int localScopeInt = 15; { int anotherLocal = 20; int localScopeInt = 30; } return 0; } Первая целочисленная переменная GlobalScopeInt будет видна как внутри функции f(), так и main(). В теле функции f() содержится объявление переменной localScopeInt. Ее область видимости локальна, т.е. ограничивается пределами модуля, содержащего объявление функции. Функция main() не может получить доступ к переменной localScopeInt функции f(). Как только завершается выполнение функции f(), переменная localScopeInt удаляется из памяти компьютера. Объявление третьей переменной, также названной localScopeInt, располагается в теле функции main(). Область ее видимости также локальна. Обратите внимание: переменная localScopeInt функции main() не конфликтует с одноименной переменной функции f(). Видимость следующих двух переменных — anotherLocal и localScopeInt — также ограничена областью модуля. Другими словами, эти переменные видны от места объявления до закрывающей фигурной скобки, ограничивающей тело модуля, в котором эта функция была объявлена. Вы, наверное, обратили внимание, что в программе объявляются две одноименные локальные переменные localScopeInt, причем одна из них объявляется во внешнем модуле, а вторая — во вложенном. Таким образом, их области видимости перекрываются. Переменная, объявленная во внутреннем модуле, будет скрывать в нем переменную внешнего модуля. После закрытия фигурной скобки внутреннего модуля вторая переменная localScopeInt из внешнего модуля вновь становится видимой. Все изменения, внесенные в localScopeInt внутри фигурных скобок, никоим образом не повлияют на значение внешней переменной localScopeInt. Новый термин:Имена могут иметь внутреннюю или внешнюю связь. Оба эти термина относятся к использованию или доступности имени в нескольких или одной программной единице. На всякое имеющее внешнюю связь имя можно ссылать только в пределах определяющей его единицы. Например, переменная, имеющая внутреннюю связь, может использоваться функциями только внутри блока программы, где эта переменная была объявлена. Имена с внешними связями доступны функциям из других блоков. Примеры внутренних и внешних связей иллюстрирует приведенный ниже код. // файл: first.cpp int externalInt = 5; const int j = 10; int main() { return 0 ; } // файл : second.cpp extern int externalInt; int anExternalInt = 10; const int j = 10; Переменная externalInt, объявленная в файле first.cpp, имеет внешнюю связь. Несмотря на то что она объявлена в файле first.cpp, доступ к этой переменной можно получить и из файла second.cpp. В обоих файлах также есть константы j, которые по умолчанию имеют внутренние связи. Чтобы изменить заданную по умолчанию внутреннюю связь констант, необходимо явно указать их глобальность, как это сделано в следующем примере: // файл: first.cpp extern const int j = 10; // файл: second.cpp extern const int j; #include <iostrean> int main() { std::cout << "j = " << j << std::endl; return 0; } Обратите внимание на использование обозначения пространства имени std перед oout, что позволяет ссылаться на все объекты етандартний библиотеки ANSI. После выполнения этого кода на экране появится строка: j = 10 Комитет по стандартизации не рекомендует использовать statie для ограничения области видимости внешней переменной, как в следующем примере: statie int staticInt = 10; int main() { //... } Если сейчас такое использование static просто не рекомендуется, то в будущем подобное выражение вообще может рассматриваться как ошибочное. Поэтому уже сейчас вместо static лучше использовать пространства имен Рекомендуется:Используйте пространства имен. Не рекомендуется:Не применяйте ключевое слово static для ограничения области видимости переменной пределами файла. Создание пространства именСинтаксис объявления пространства имен аналогичен синтаксису объявления структур и классов. После ключевого слова namespace стоит имя пространства имен, которое может и отсутствовать, а затем следует открывающая фигурная скобка. Пространство имен завершается закрывающей фигурной скобкой без точки с запятой в конце выражения. Например: namespace Window { void move( int x, int у); } Имя Window идентифицирует пространство имен. Можно создавать множество экземпляров именованных пространств имен, расположенных внутри одного файла или в разных единицах трансляции. Примером тому может быть пространство имен std стандартной библиотеки C++. Его использование обосновано в данном случае тем, что стандартная библиотека представляет собой логически единую группу функций. Основное назначение пространств имен состоит в группировании связанных элементов в именованной области программы. Ниже показан пример пространства имен, объединяющего несколько файлов заголовков: // header1.h namespace Window { void move( int x, int у) ; } // header2.h namespace Window { void resize( int x, inl у ) ; } Объявление и определение типовВнутри пространства имен можно объявлять и определять типы и функции. Тут не обойтись без обсуждения стратегических подходов программирования в C++. Правильность структуры программы определяется тем, насколько четко отделен интерфейс программы от ее процедурной части. Этому принципу необходимо следовать не только при работе с классами, но и при создании пространств имен. Ниже показан пример плохо структурированного пространства имен: namespace Window { // ... другие объявления и определения переменных. void move( int x, int у) ; // объявления void resize( int x, int у ) ; // ... другие объявления и определения переменных. void move( int x, int у ) { if( x < MAX_SCREEN_X && x > 0 ) if( у < MAX_SCREEN_Y && у > 0 ) platform.move( x, у ) ; // специальная программа } void resize( int x, int у ) { if( x < MAX_SIZE__X && x > 0 ) if( у < MAX_SIZE_Y && у > 0 ) platform.resize( x, у ); // специальная программа } // ... продолжение определений } Наглядно видно, как быстро пространство имен становится хаотичным и беспорядочным! Причем в этом примере объявление пространства имен составляло всего около 20 строк, а во что превратилась бы программа, будь объявление более длинным? Объявление функций за пределами пространства именФункции пространства имен следует объявлять за пределами тела пространства. Это позволит явно отделить объявления функций от определения их выполнения, не захламляя тело пространства имен. Кроме того, вынос объявлений функции даст возможность разместить пространство имен и его внедренные объявления в файле заголовка, а определения выполнения поместить в исполняемый файл программы. Например: // файл header.h namespace Window { void move( int x, int у); // другие объявления } // file impl.cpp void Window::move( int x, int у ) { // код перемещения окна } Добавление новых членовДобавление новых членов в пространство имен осуществляет только в теле пространства. Невозможно создавать новые члены пространства имен вне тела пространства, указывая его имя, как это делалось с объектами классов. Компилятор ответит на это сообщением об ошибке. Пример такой ошибки показан ниже. namespace Window { // ряд объявлений } // код программы int Window::newIntegerInNamespace; // ошибка Последняя строка неправильна, и компилятор сообщит об этом. Чтобы исправить ошибку, перенесите объявление переменной-члена newIntegerInNamespace в тело пространства имен. Все заключенные в пространстве имени члены являются открытыми. Поэтому неправильным будет и следующий код: namespace Window { private: void move( int x, int у ); } Вложения пространства именОдно пространство имен можно вложить в другое пространство имен. К подобному вложению прибегают в том случае, когда определение выполнения одного пространства имен должно содержать объявление нового пространства. Чтобы обратиться к члену внутреннего пространства имен, необходимо явно указать имена обоих пространств. Так, в следующем примере одно именованное пространство объявляется внутри другого именованного пространства: namespace Window { namespace Pane { void size( int x, int у ); } } Для доступа к функции size() за пределами пространства имен Window нужно дополнить имя вызываемой функции именами пространств имен, внутри которых она была объявлена, например: int main( ) { Window::Pane::size( 10, 20 ); return 0; } Использование пространства именТеперь рассмотрим пример использования пространства имен и связанного с ним оператора видимости. Сначала внутри пространства имен Windowoбъявляютcя все типы и функции, после чего за его пределами следуют определения функций-членов. Чтобы определить функцию, объявленную в пространстве имен, следует перед именем функции установить имя пространства имен и оператор видимости, как это делается в листинге 17.1. Листинг 17.1. Использование пространства имен 1: #include <iostream> 2: 3: namespace Window 4: { 5: const int MAX_X = 30 6: const int MAX_Y = 40 7: class Рапе 8: { 9: public: 10: Pane(); 11: ~Pane(); 12: void size( int x, int у ) 13: void move( int x, int у ) 14: void show( ); 15: private: 16: static int cnt; 17: int x; 18: int у; 19: }; 20: } 21: 22: int Window::Pane::cnt = 0; 23: Window::Pane::Pane() : x(0), y(0) { } 24: Windo::Pane::~Pane() { } 25: 26: void Window;:Pane::size( int x, int y ) 27: { 28: if( x < Window::MAX_X && x > 0 ) 29: Pane;:x = x: 30: if( y < Window;;MAX_Y && y > 0 ) 31: Pane::y = y; 32: } 33: void Window;:Pane::move( int x, int y ) 34: { 35: if( x < Window::MAX_X && x > 0 ) 36: Pane::x = x ; 37: if( y< Window::MAX_Y && y > 0 ) 38: Pane::y = y ; 39: } 40: void Window::Pane::show( ) 41: { 42: std::cout << "x " << Pane::x; 43: std::cout << " y " << Pane::y << std::endl; 44: } 45: 46: int main( ) 47: { 48: Window::Pane pane; 49: 50: pane.move( 20, 20 ); 51: pane.show( ); 52: 53: return 0; 54: } Результат: x 20 y 20 Анализ: Обратите внимание, что класс Pane вложен в пространство имен Window. Поэтому при обращении к объектам класса Pane их имена дополняются идентификатором Window::. Статическая переменная-член cnt, объявленная в строке 16 внутри класса Pane, определяется как обычно. Но при определении функции-члена Pane: :size() и обращениях к переменным-членам MAX_X и MAX_Y в строках 26-32 используется явное указание пространства имен. Дело в том, что статическая переменная-член определяется внутри класса Pane, а определения других функций-членов (это же справедливо для функции Pane::move()) происходят как за пределами класса, так и вне тела пространства имен. Без явного указания пространства имен компилятор покажет сообщение об ошибке. Обратите внимание также на то, что внутри определений функций-членов обращение к объявленным переменным-членам класса происходит с явным указанием имени класса: Pane::x и Pane::y. Зачем это делается? Дело в том, что у вас возникли бы проблемы, если функция Pane::move() определялась бы следующим образом: void Window::Pane::move( int x, int у ) { if( x < Window::MAX_X && x > 0 ) x = x; if( у < Window::MAX_Y && у > 0 ) У = У; Platform::move( x, у ); } Ну что, догадались, в чем проблема? Опасность состоит в том, что компилятор в этом выражении никаких ошибок не заметит. Источник проблемы заключается в аргументах функции. Аргументы x и у скроют закрытые переменные-члены x и у, объявленные в классе Pane, поэтому вместо присвоения значений аргументов переменным-членам произойдет присвоение этих значений самим себе. Чтобы исправить эту ошибку, необходимо явно указать переменные-члены класса: Pane::x = x; Pane::y = у; Ключевое слово usingКлючевое слово using может использоваться и как оператор, и в качестве спецификатора при объявлении членов пространства имен, но синтаксис использования using при этом меняется. Использование using как оператораС помощью ключевого слова using расширяются области видимости всех членов пространства имен. Впоследствии это позволяет ссылаться на члены пространства имен, не указывая соответствующее имя пространства. Использование using показано в следующем примере: namespace Window { int valuo1 = 20; int value2 - 40; } ... Window::value1 = 10; using namespace Window; value2 = 30; Все члены пространства имен Window становятся видимыми, начиная от строки using namespace Window; и до конца соответствующего модуля программы. Обратите внимание, что если для обращения к переменной value1 в верхней части фрагмента программы необходимо указывать пространство имен, то в этом нет необходимости при обращении к переменной value2, поскольку оператор using сделал видимыми все члены пространства имен Window. Оператор using может использовать в любом модуле программы с различной областью видимости. Когда выполнение программы выходит за область видимости данного модуля, автоматически становятся невидимыми все члены пространства имен, открытые в этом модуле. Проанализируйте это на следующем примере: namespace Window { int value1 = 20; int value2 = 40 ; } //... void f() { { using namespace Window ; value2 = 30 ; } value2 = 20 ; //ошибка! } Последняя строка кода функции f() — value2 = 20 — вызовет ошибку во время компиляции, поскольку переменная value2 в этом месте невидима. Видимость этой переменной, заданная оператором using, закончилась сразу за закрывающими фигурными скобками в предыдущей строке программы. В случае объявления внутри модуля локальных переменных все одноименные переменные пространства имен, открытые в этом модуле, будут скрыты. Это аналогично сокрытию глобальных переменных локальными в случае совпадения их областей видимости. Даже если переменная, объявленная в пространстве имен, будет открыта с помощью using после объявления локальной переменной, последняя все равно будет иметь приоритет. Это наглядно показано в следующем примере: namespace Window { int value1 = 20; int value2 = 40 ; } //... void f() { int value2 = 10; using namespace Window; std::cout << value2 << std::endl; } При выполнения этой функции на экране появится значение 10, а не 40, подтверждая тот факт, что переменная value2 пространства имен Window скрывается переменной value2 функции f(). Если все же требуется использовать переменную пространства имен, явно укажите имя пространства. При использовании одноименных идентификаторов, один из которых объявлен как глобальный, а другой — внутри пространства имен, также может возникнуть двусмысленность. Чтобы избежать ее, всегда явно указывайте имя пространства при вызове объекта, как в следующем фрагменте программы: namespace Window { int value1 = 20; } //... using namespace Window; int value1 = 10; void f() { value1 = 10 ; } В данном примере неопределенность возникает внутри функции f(). Оператор using сообщает переменной Window::value1 глобальную область видимости. Однако в программе объявляется другая глобальная переменная с таким же именем. Какая из них используется в функции f()? Обратите внимание, что ошибка будет показана не во время объявления одноименной глобальной переменной, а при обращении к ней в теле функции f(). Использование using в объявленияхНазначение using в объявлениях идентификаторов аналогично использованию using как оператора с той лишь разницей, что обеспечивается более высокий уровень контроля. Этот способ используется для открытия видимости только для одного идентификатора, объявленного в пространстве имен, как показано в следующем примере: namespace Window { int value1 = 20; int value2 = 40; int value3 = 60; } //... using Window::value2; //открытие доступа к value2 в текущем модуле Window::value1 = 10; //для value1 необходимо указание пространства имен value2 = 30; Window::value3 = 10; // для value3 необходимо указание пространства имен Итак, с помощью using можно открыть доступ в текущую область видимости к отдельному идентификатору пространства имен, не повлияв на остальные идентификаторы, заданные в этом пространстве. В предыдущем примере переменная value2 вызывается без явного указания пространства имен, что невозможно при обращении к value1 и value3. Использование using при объявлении обеспечивает дополнительный контроль над видимостью каждого идентификатора пространства имен. В этом и заключается отличие от использования using как оператора, открывающего доступ сразу ко всем идентификаторам пространства имен. Видимость имени распространяется до конца блока, что можно сказать и о любом другом объявлении. С помощью using идентификаторы можно объявлять как глобально, так и в локальной области. Если в локальную область, где уже объявлен идентификатор из пространства имен, добавляется другой идентификатор с таким же именем, это приводит к ошибке компиляции. Ошибкой будет и объявление идентификатора из пространства имен в области, где уже существует другой идентификатор с таким же именем. Это показано в следующем примере: namespace Window { int value1 = 20; int value2 = 40; } //... void f() { int value2 = 10; using Window::value2; // ряд обьявлеиий std::cout << value2 << std::endl; } Компиляция второй строки функции f() приведет к ошибке, поскольку переменная с именем value2 в этом блоке уже объявлена. Тот же результат получится, если объявление с using разместить перед объявлением локальной переменной valuo2. Идентификатор пространства имен, введенный в локальную область с помошью using, скрывает аналогичный идентификатор, объявленный за пределами этой области. Проанализируйте следующий пример: namespace Window { int value1 - 20; int va]ue2 - 40; } int value2 = 10; //... void f() { using Window::value2; std::cout << value2 << std::endl; } Объявление переменной с помощью using в функции f() скрывает глобальную переменную value2. Как отмечалось ранее, этот способ использования using позволяет дополнительно контролировать области видимости отдельных идентификаторов пространства имен. Оператор using открываетдоступ n локальной области ко всем идентификаторам, объявленным в пространстве имен. Поэтому предпочтительней использовать using в объявлениях, а не как оператор, чтобы п полной мере воспользоваться всеми преимуществами, предоставляемыми пространством имени. Явное расширение области видимости для отдельных идентификаторов позволяет снизить вероятность возникновения конфликтов имен. Использование оператора using оправдано только в том случае, если необходимо открыть доступ сразу ко всем идентификаторам пространства имен. Псевдонимы пространства именПсевдонимы пространства имен используется для создания дополнительного имени именованного пространства. Как правило, псевдоним представляет собой информативный термин, используемый для ссылки на пространство имен. Это весьма эффективно, если имя пространства очень длинное. Создание псевдонимов поможет упростить дальнейшую работу с пространствами имен. Рассмотрим следующий пример: namespace the_software_company { int value; //... } the_software_company::value = 10; ... namespace TSC = the_software_company; TSC::value = 20; Недостаток этого метода состоит в том, что подобный псевдоним может уже существовать в указанной области видимости. В этом случае компилятор сообщит об ошибке, и вы сможете просто изменить псевдоним. Неименованные пространства именТакие пространства имен отличаются от именованных тем, что не имеют имени. Наиболее часто они используются для защиты глобальных данных от потенциальных конфликтов имен. Каждая единица программы имеет собственное уникальное неименованное пространство. Все идентификаторы, объявленные внутри такого пространства имен, вызываются просто по имени без каких-либо префиксов. В следующем коде представлены примеры двух неименованных пространств, расположенных в двух разных файлах. // файл: one.cpp namespace { int value; char p(char *p); //... } // файл: two.cpp namespace { int value; char p(char *p); //... } int main() { char с = p(ptr); } В каждом файле объявляется переменная value и функция p(). Благодаря тому что для каждого файла задано свое неименованное пространство, обращения к одноименным идентификаторам внутри файлов одной программы не приводит к конфликтам имен. Это хорошо видно при вызове функции p(). Функционирование неименованного пространства имен аналогично работе статического объекта с внешней связью, такого как static int value = 10 ; Не забывайте, что подобное использование ключевого слова static не рекомендуется комитетом по стандартизации. Для решения подобных задач теперь используются пространства имен. Можно провести еще одну аналогию с неименованными пространствами: они очень похожи на глобальные переменные с внутренней связью. Стандартное пространство имен stdНаилучший пример пространств имен можно найти в стандартной библиотеке C++. Все функции, классы, объекты и шаблоны стандартной библиотеки объявлены внутри пространства имен std. Вероятно, вам приходилось видеть подобные выражения: #include <iostream> using namespace std; Не забывайте, что использование директивы using открывает доступ ко всем идентификаторам именованного пространства имен. Поэтому лучше не обращаться к помощи данного оператора при работе со стандартными библиотеками. Почему? Да потому, что таким образом вы нарушите основное предназначение пространств имен. Глобальное пространство будет буквально заполнено именами различных идентификаторов из файлов заголовков стандартной библиотеки, большая часть которых не используется в данной программе. Помните, что во всех файлах заголовков используется средство пространства имен, поэтому, если вы включите в программу несколько файлов заголовков и используете оператор using, все идентификаторы, объявленные в этих файлах заголовков, получат глобальную видимость. Вы могли заметить, что в большинстве примеров данной книги это правило нарушается. Это сделано исключительно для краткости изложения примеров. Вам же следует использовать в своих программах объявления с ключевым словом using, как в следующем примере: #include <iostream> using std::cin; using std::cout; using std::endl; int main( ) { int value = 0; cout << "So, how many eggs did you say you wanted?" << endl; cin >> value; cout << value << " eggs, sunny-side up!" << endl; return(0); } Выполнение этой программы приведет к следующему выводу: So, how many eggs did you say you wanted? 4 4 eggs, sunny-side up! В качестве альтернативы можно явно обращаться к идентификаторам, объявленным в пространстве имен: #include <iostream> int main() { int value = 0; std::cout << "How many eggs did you want?" << std::endl; std::cin >> value; std::cout << value << " eggs, sunny-side up!" << std::endl; return(0); } Программа выведет следующие данные: How many eggs did you want? 4 4 eggs, sunny-side up! Такой подход вполне годится для небольшой программы, но в больших приложениях будет довольно сложно проследить за всеми явными обращениями к идентификаторам пространства имен. Только представьте себе: вам придется добавлять std:: для каждого имени из стандартной библиотеки! РезюмеСоздать пространство имени так же просто, как описать класс. Есть несколько различий, но они весьма незначительны. Во-первых, после закрывающей фигурной скобки пространства имен не следует точка с запятой. Во-вторых, пространство имен всегда открыто, в то время как класс закрыт. Это означает, что вы можете продолжить объявление пространства имен в других файлах или в разных местах одного файла. Вставлять в пространство имен можно все, что подлежит объявлению. Создавая классы для своей будущей библиотеки, вам следует взять на вооружение средство пространства имен. Объявленные внутри пространства имен функции должны определяться за его пределами. Благодаря этому интерфейс программы отделяется от ее выполнения. Можно вкладывать одно пространство имен в другое. Однако не забывайте, что при обращении к членам внутреннего пространства имен необходимо явно указывать имена внешнего и внутреннего пространств. Для открытия доступа ко всем членам пространства имен в текущей области видимости используется оператор using. Однако в результате этого слишком много идентификаторов могут получить глобальную видимость, что чревато конфликтами имен. Поэтому использование данного оператора не относится к правилам хорошего тона, особенно при работе со стандартными библиотеками. Вместо этого воспользуйтесь ключевым словом using при объявлении в программе идентификаторов из пространства имен. Ключевое слово using в объявлении идентификатора используется для открытия доступа в текущей области видимости только к отдельному идентификатору из пространства имен, что существенно снижает вероятность возникновения конфликтов имен. Псевдонимы пространств имен аналогичны оператору typedef. С их помощью можно создавать дополнительные имена для именованных пространств, что оказывается весьма полезным, если исходное имя длинное и неудобное. Неименованное пространство может содержаться в каждом файле. Как следует из названия, это пространство без имени. Описав неименованное пространство имен с помощью ключевого слова namespace, можно использовать одноименные идентификаторы в разных файлах программы. Благодаря неименованному пространству имена переменных становятся локальными для текущего файла. Неименованные пространства имен рекомендуется использовать вместо ключевого слова static. В стандартной библиотеке C++ используется пространство имен std. Однако избегайте использования оператора using, открывающего доступ ко всем идентификаторам стандартной библиотеки. Воспользуйтесь лучше объявлениями с ключевым словом using. Вопросы и ответыОбязательно ли использовать пространства имен? Нет, вы можете писать простые программы и без помощи пространств имен. Просто убедитесь, что вы используете старые стандартные библиотеки (например, #include <string.h>), а не новые (например, #include <cstring.h>). Каковы отличия между двумя способами использования ключевого слова using? Ключевое слово using можно использовать как оператор и как спецификатор описания. В первом случае открывается доступ ко всем идентификаторам пространства имен. Во втором — доступ можно открыть только для отдельных идентификаторов. Что такое неименованные пространства имен и зачем они нужны? Неименованными называются пространства имен, для которых не задано собственное имя. Они используются для защиты наборов идентификаторов в разных файлах одной программы от возможных конфликтов имен. Идентификаторы неименованных пространств не могут использоваться за пределами области видимости их пространства имен. КоллоквиумКонтрольные вопросы1. Можно ли использовать идентификаторы, объявленные в пространстве имен, без применения ключевого слова using? 2. Назовите основные отличия между именованными и неименованными пространствами имен. 3. Что такое стандартное пространство имен std? Упражнения1. Жучки: найдите ошибку в следующем коде: #include <iostream> int main() { cout << "Hello world!" << end; return 0; } 2. Перечислите три способа устранения ошибки, найденной в коде упражнения 1. День 18-й. Анализ и проектирование объектно-ориентированных программУглубившись в синтаксис C++, легко упустить из виду, как и зачем используются различные подходы и средства программирования. Сегодня вы узнаете: • Как проводить анализ проблем и поиск решений, основываясь на подходах объектно-ориентированного программирования • Как проектировать эффективные объектно-ориентированные программы для нахождения оптимальных решений поставленных задач • Как использовать унифицированный язык моделирования (UML) для документирования анализа и проектирования Являеться ли C++ объектно-ориентированным языком программированияЯзык C++ был создан как связующее звено между новыми принципами объектно- ориентированного программирования и одним из самых популярных в мире языком программирования С для разработки коммерческих программ. Для реализации назревших идей объектного программирования требовалась разработка надежной и эффективной среды программирования. Язык С был разработан как нечто среднее между языками высокого уровня для бизнес- приложений, такими как COBOL, и работающим на уровне "железа", высокоэффективным, но трудным в использовании языком ассемблер. Язык С разрабатывался для реализации структурного программирования, при котором решение задачи разбивается на более мелкие рутинные единицы повторяющихся действий, называемых процедурами. Программы, которые создавались в конце девяностых, принципиально отличаются от написанных в начале десятилетия. Программами, основанными на процедурных подходах, обычно трудно управлять, их тяжело поддерживать и модернизировать. Графические интерфейсы пользователя, Intemet, выход на телефонные линии по цифровым каналам и масса новых технологий резко увеличили сложность проектов, при этом ожидания потребителей относительно качества интерфейса пользователя также постоянно росли. Под натиском такого стремительного усложнения программ разработчики вынуждены были заняться поиском новых подходов программирования. Старые процедурные подходы все более отставали от требований сегодняшнего дня. Программы быстро устаревали, а модернизация процедурной программы проходила не проще, чем разработка новой. По мере увеличения размеров программ значительно усложнялась их отладка. Проекты часто устаревали еще до того, как попадали на рынок. Расходы на поддержку и модернизацию этих проектов превышали доходы от их реализации. Таким образом, внедрение в жизнь новых подходов объектно-ориентированного программирования было не прихотью программистов, а единственным спасением. Объектно-ориентированные языки программирования создают прочную связь между структурами данных и методами, обрабатывающими эти данные. Более важно то, что при таком программировании нет необходимости думать о том, как хранятся и обрабатываются данные в отдельных модулях. Программист просто узнает из интерфейса объекта, какие данные ему нужно передать и что он возвращает, после чего использует готовый модуль в своей программе. Что же представляют собой виртуальные объекты? Сравним их с предметами и объектами окружающего мира: автомобилями, собаками, деревьями, облаками, цветами. Каждый из них имеет свои характеристики: быстрый, дружелюбный, коричневый, густой, красивый. Кроме того, множеству объектов свойственно определенное поведение: они движутся, лают, растут, проливаются дождем, увядают. Под словом "собака" большинство из нас понимают не совокупность пищеварительной, нервной и прочих систем, что может заинтересовать лишь узких специалистов, а мохнатого друга с четырьмя лапами, приветливо машущего хвостом и заливающегося звонким лаем. Для нас важны внешние признаки и поведение собаки, а не ее внутреннее "устройство". Построение моделейЧтобы отследить все признаки и связи объекта окружающего мира, нам пришлось бы создавать модель вселенной, настолько в этом мире все взаимосвязано. Целью модели является создание осмысленной абстракции реального мира. Такая абстракция должна быть проще самого мира, но при этом отображать его достаточно точно, чтобы модель можно было использовать для предсказания поведения предметов в реальном мире. Классической моделью является детский глобус. Модель — это не сам предмет; мы никогда не спутаем детский глобус с планетой Земля, но первое настолько хорошо отображает второе, что мы можем познавать Землю, изучая глобус. Конечно, здесь имеются существенные упрощения. На глобусе моей дочери никогда не бывает дождей, наводнений, "глобусотрясений" и т.п., но я могу его использовать, например, для того, чтобы рассчитать, сколько понадобится времени для полета от дома до Москвы. Это может потребоваться, скажем, при планировании времени и расходов на командировку. Модель, которая не будет проще моделируемого предмета, бесполезна. Стивен Райт (Steven Wright) пошутил на эту тему: "У меня есть карта, где один дюйм равен дюйму. Я живу на E5". Создание хорошей объектно-ориентированной программы по сути своей является моделированием реальных объектов средствами программирования. Для создания такой виртуальной модели важно хорошо знать, во-первых, средства программирования и, во-вторых, последовательность построения программы с помощью этих средств. Проектирование программ: язык моделированияЯзык моделирования — это, по сути, фикция, набор соглашений по поводу принципов предварительного моделирования программы на бумаге. Тем не менее без этого этапа невозможно создать эффективный профессиональный программный продукт. Давайте договоримся изображать классы на бумаге в виде треугольников, а отношения наследования между ними — в виде пунктирных стрелок от базового класса к производному. Для примера смоделируем класс Geranium (Герань), произведенный от класса Flower (Цветок), как показано на рис. 18.1.  Рис. 18.1. Схематическое изображение наследования класса На рисунке видно, что Geranium — особый вид Flower, и это вполне соответствует действительности. Если мы с вами договоримся графически изображать таким способом наследования классов, то будем прекрасно понимать друг друга. Со временем мы, вероятно, захотим моделировать многие сложные отношения и разработаем свой набор соглашений и правил по созданию диаграмм, отображающих взаимосвязи объектов программы. Конечно, нам также придется довести эти соглашения до сведения других сотрудников, которые работают или будут работать вместе с нами над общим проектом. Возможно, мы будем взаимодействовать с другими фирмами, имеющими свои соглашения, и надо будет потратить время, чтобы выработать общие принципы, позволяющие избежать возможных недоразумений. В таком случае было бы полезным существование единого языка моделирования, понятного для всех. (В действительности эту прекрасную идею реализовать ничуть не проще, чем заставить всех жителей Земли говорить на эсперанто.) Тем не менее такой язык был создан, и имя ему — UML (Unified Modeling Language — унифицированный язык моделирования). Его задача состоит в том, чтобы добиться единообразия в отображении взаимоотношений между объектами в диаграммах. В соответствии с соглашениями языка UML нашу схему, представленную на рис. 18.1, следовало бы изобразить иначе (рис. 18.2). 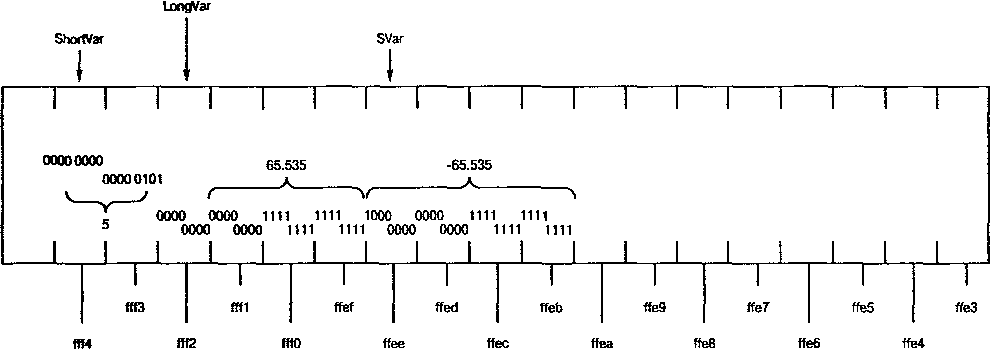 Рис. 18.2. Те же отношения наследования, но с учетом соглашений UML В соответствии с соглашениям и UML классы изображаются в виде прямоугольников, а наследование — в виде стрелки, направленной от производного класса к базовому. Направление стрелки противоречит тому, что подсказывает интуиция большинства из нас, но это не страшно: когда мы все договоримся, система заработает как надо. Соглашения UML совсем несложные. Диаграммы нетрудно понимать и использовать. Мы рассмотрим эти соглашения на конкретных примерах в ходе освоения этой главы, что гораздо проще изучения UML вне контекста. Хотя этой теме можно посвятить целую книгу, по правде говоря, это будет пустая трата времени и бумаги, поскольку язык UML вполне соответствует принципу: лучше один раз увидеть на практике, чем десять раз прочитать. Процесс проектирования программПравильное выполнение анализа и проектирования объектно-ориентированной программы намного важнее, чем соблюдение соглашений языка моделирования. Именно этой тематики посвящено большинство публикаций и конференций. И если по поводу языка моделирования удалось прийти к общим соглашениям и выработать UML, то споры по поводу основополагающих принципов анализа и проектирования программ продолжаются по сей день. Появилась даже новая профессия — методологи: это программисты, которые изучают и разрабатывают методы программирования. Часто в литературе можно встретить статьи, посвященные описанию нового метода программирования. Метод — это совокупность языка моделирования и подходов анализа и проектирования. Три наиболее известных методолога в мире — это Грейди Буч (Grady Booch), создавший метод Буча, Айвер Якобсон (Ivar Ja- cobson), разработавший подходы объектно-ориентированного программирования, и Джеймс Рамбо (James Rumbaugh), создавший технологию объектного моделирования. Вместе они создали метод Objectory~ коммерческий продукт от фирмы Rational Software, Inc. Это фирма, в которой они работают и где их любовно величают "три амигос". Материал, изложенный на этом занятии, приблизительно следует методам Objectory. Точного соответствия не будет, так как я не верю в рабское следование академической теории. Я считаю создание конкурентно способной профессиональной программы более важным, чем точное соответствие этой программы каким бы то ни было абстрактным методам. В конце концов на Objectory свет клином не сошелся, и я рекомендую вам быть эклектиками и выбирать все лучшее из всех методов, которые вам известны. Процесс проектирования программ итеративен. Это значит, что при разработке программы мы периодически повторяем весь процесс, по мере того как растет понимание требований, Проект нацелен на решение задачи, но нюансы, возникающие в ходе поиска оптимального решения, воздействуют на сам проект. Невозможно разработать серьезный крупный проект идя по прямой от начала до конца. Вместо этого на отдельных этапах приходится возвращаться к началу, постоянно совершенствуя интерфейсы и процедуры выполнения отдельных объектов. Итеративную разработку следует отличать от каскадной, при которой выход из одной стадии становится входом в следующую и назад дороги нет (рис. 18.3). Этот процесс напоминает конвейер сборки автомобилей, где на каждом этапе собирается и тестируется один узел, постепенно формируя автомобиль. Но программа, в отличие от автомобиля, продукт штучный. Разработку программ редко удается поставить на конвейер. При итеративном проектировании теоретик предлагает новую идею, а прикладник начинает творческую реализацию этой абстрактной идеи в программе. По мере того как начнут прорисовываться детали проекта, будут меняться наши представления о форме реализации исходной идеи. Работа над проектом начинается с формулирования требований к проекту, которые в ходе разработки могут меняться, что потребует внесения изменений в уже созданные программные блоки. Большой проект разбивается на отдельные блоки, для которых сначала создаются прототипы, а затем процедуры их выполнения. Тестирование выполнения отдельных модулей может привести к необходимости внесения изменений в их прототипы, а изменения отдельных блоков заставляют время от времени пересматривать принципы их взаимодействия в целом проекте. 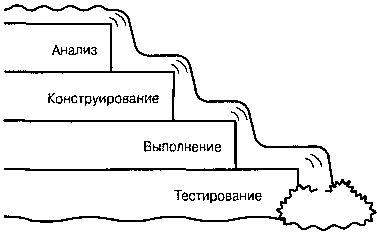 Рис. 18.3. Каскадный процесс проектирования Хотя цикличность работы над проектом очевидна, описать эти процессы в виде какого-то стабильного цикла довольно сложно. Поэтому предлагаю вам лишь логическую последовательность действий: возникновение идеи, анализ и осмысление ее, проектирование, программирование, тестирование и возвращение к тому этапу, который можно модернизировать. Таким образом, итеративность разработки проекта не заставляет вас кружить по замкнутому циклу, а позволяет творчески подойти к решению задач и возвращаться всякий раз к тому этапу, где вы видите возможность повысить эффективность выполнения программы. Еще раз повторим последовательность действий. 1. Разработка концепции. 2. Анализ. 3. Проектирование. 4. Реализация. 5. Тестирование. 6. Возвращение. Разработка концепции — это вынашивание чистой идеи, к сожалению, далекой от реальной жизни. Анализ — это процесс осознания требований к проекту. Проектирование — процесс формирования модели классов, на основе которой будет создаваться код. Реализация — написание кода (например, на C++); тестирование — проверка того, все ли в порядке, и возвращение — это шлифовка вашего продукта до того состояния, когда его можно будет отдать заказчику. Осталось реализовать все это на практике. ИдеяЛюбая гениальная программа начинается с идеи. Некто думает о продукте, который, с его точки зрения, было бы хорошо создать. Реже сногсшибательную идею выдают комитеты. На самой первой стадии анализа и проектирования объектно-ориентированного программного продукта эта самая идея должна быть зафиксирована одним предложением (в крайнем случае, кратким абзацем). Идея становится ведущим принципом разработки, и команда, собравшаяся для ее реализации, по мере продвижения вперед должна на нее оглядываться, а в случае необходимости и корректировать. Дискуссии Много спорят о том. что происходит на каждом этапе процесса итеративного проектирования, и даже о том, какназывается каждый этап. Откроем тайну: это не имеет значения. Основные этапы каждого процесса одни и те же: найдите, что надо постро- ить, спроектируйте решение и реализуйте проект. Хотя на дискуссиях расцвели пышным цветом группы новостей и списки электронных адресов специалистов по объектнымтехнологиям, в сущности, объектно-ориентированный анализ и проектирование довольно просты. В этой главе описан практиче- ский подход к процессу создания архитектуры приложения. Целью всей этой работы является создание кода, соответствующего установленным требованиям, а также отличающегося надежностью, расширяемостью и настраивае- мостью. Не менее важным является создание высококачественного продукта в уста- новленные сроки и в пределах бюджета. Даже если новая идея исходит от группы товарищей из отдела маркетинга, кто-то все-таки должен стать "крестным отцом" этой идеи и блюсти ее чистоту. Из идеи проистекают требования к проекту. Детали исходной идеи могут преобразиться с учетом реалий сроков и требований рынка, но основная задача, которую планируется решить с помощью новой программы, должна оставаться неизменной, иначе зачем же браться за этот проект. Если в ходе проработки деталей вы забудете о том, ради чего был задуман проект, то такой проект обречен. Анализ требованийЭтап разработки концепции, когда формулируется идея, очень короткий. Это не более чем вспышка озарения с последующим изложением на бумаге идеи, рожденной в уме теоретика. Большинство программистов включаются в проект на более поздних этапах, когда основная идея уже сформулирована. Иногда формулирование идеи путают с определением требований к проекту. Сильная идея необходима, но этого недостаточно. Чтобы перейти к анализу, требуется понять, каким образом, где и кем будет использоваться данный программный продукт. Цель этапа анализа состоит в том, чтобы сформулировать и зафиксировать эти требования. Результатом анализа должен быть документ с четкими требованиями к разработчикам проекта. Первым его разделом будет определение ситуаций использования проекта. Ситуация использованияОпределение ситуаций использования проекта лежит в основе анализа и проектирования программного продукта. Ситуация использования — это описание в общих чертах того, каким образом будет использоваться программный продукт. От этого зависит подбор методов и классов для реализации основной идеи. Обсуждение всех возможных ситуаций использования может быть важнейшей задачей анализа. На этом этапе просто необходимо прибегнуть к помощи экспертов, которые помогут учесть многие моменты, далекие от обычного программирования, например особенности спроса и предложения на рынке программных продуктов и многое другое. На этом этапе также следует уделить некоторое внимание проектированию интерфейса программного продукта, но внутренние методы реализации проекта нас еще не должны волновать. Пока наше внимание сконцентрировано на пользователе. Пользователем может быть не только отдельный человек, но и определенная группа людей, организация или другой программный продукт. Таким образом, определение ситуаций использования включает: • формулирование общих представлений о том, где и каким образом будет использоваться создаваемый программный продукт; • работу с экспертами по выяснению особенностей предполагаемого места использования продукта, не связанных с проблемами обычного программирования; • определение пользователя, для которого создается программный продукт. Под ситуацией использования следует понимать больше, нежели просто тип компьютерной системы или конкретная организация-заказчик. Необходимо также учесть особенности взаимодействия будущих пользователей с разрабатываемым программным продуктом. На данном этапе программный продукт следует рассматривать как "черный ящик". Важно четко определить, какие вопросы будет ставить пользователь перед системой и какие ответы он ожидает получить. Определение пользователейОбратите внимание, что пользователи — это не обязательно люди. Системы, которые будут взаимодействовать с создаваемой нами системой, тоже пользователи. Таким образом, если создается программа для автоматизированного кассового аппарата (ATM, известного как банкомат), то пользователем по отношению к нему будут клиенты и банковские клерки, а также другие банковские системы, например система no отслеживанию ипотек или no выдаче ссуд для студентов. Основные характеристики пользователей таковы: • они являются внешними по отношению к системе; • они взаимодействуют с системой. При анализе ситуаций использования нередко самым трудным бывает начало. Лучше на этом этапе слишком много не думать, а сразу броситься в атаку: просто напишите список людей и систем, которые будут взаимодействовать с вашей системой. Помните, что важно не то, как зовут человека, а в какой роли он будет выступать по отношению к новой системе: клерком, менеджером, клиентом и т.д. Один человек может иметь несколько ролей. В случае создания программного обеспечения для ATM необходимо учесть следующих возможных пользователей: • клиент; • менеджер; • компьютерная система банка; • клерк, заправляющий кассовый аппарат деньгами и ответственный за его включение и выключение. Поначалу нет необходимости чрезмерно расширять и детализировать исходный список пользователей. Для описания ситуаций использования достаточно определить трех или четырех пользователей. Каждый из них по-разному взаимодействует с системой. Каждое взаимодействие должно быть учтено при определении ситуаций использования. Определение первой ситуации использованияНачнем с клиента. В общих чертах опишем, как клиент будет взаимодействовать с нашей системой. • Клиент проверяет, что осталось на его счетах. • Клиент кладет деньги на свой счет. • Клиент снимает деньги со своего счета. • Клиент переводит деньги со счета на счет. • Клиент открывает счет. • Клиент закрывает счет. Надо ли различать ситуации, когда клиент кладет деньги на свой расчетный, а когда на депозитный счет, или можно скомбинировать эти действия в одну ситуацию: клиент кладет деньги на свой счет, как было сделано в списке? Ответ зависит от значимости такого различия для конкретного банка. Чтобы определить; представляют ли эти действия одну ситуацию использования или две, надо выяснить, различны ли механизмы обработки (делает ли клиент нечто существенно различное с этими вкладами) и различны ли выходы (реагирует ли система по-разному). На оба вопроса в нашем случае ответ будет отрицательным: механизм внесения клиентом денег на разные счета в целом одинаков и система в обоих случаях прореагирует однотипно — увеличит сумму на соответствующем счете. При условии, что пользователь и система ведут себя более-менее идентично в двух разных ситуациях, эти ситуации можно объединить в одну. Позднее можно конкретизировать сценарии использования системы и разделить эти ситуации, если возникнет необходимость. Анализируя действия разных пользователей, можно обнаружить дополнительные ситуации использования, ответив на ряд вопросов. • Почему пользователь использует систему? Чтобы получить наличные, сделать вклад или проверить остаток на счете. • Какой результат ожидает пользователь от своего запроса к системе? Положить наличные на счет или снять их, чтобы сделать покупку. • Что заставило пользователя прибегнуть к этой системе сейчас? Возможно, ему недавно выплатили зарплату или надо сделать покупку. • Что следует выполнить пользователю, чтобы воспользоваться системой? Вставить карточку в гнездо кассового аппарата ATM. Ага! Нужно учесть ситуацию, когда клиент регистрируется в системе. • Какую информацию клиент должен предоставить системе? Ввести личный идентификационный номер. Ага! Нужно предоставить возможность клиенту получить или изменить личный идентификационный номер. • Какую информацию пользователь хочет получить от системы? Остатки на счетах и т. д. Часто можно обнаружить дополнительные ситуации использования, обратив внимание на структуру учета пользователей в доменах. У клиента есть имя, личный идентификационный номер и номер счета. Предусмотрена ли в системе возможность обработки и изменения этих данных? Счет имеет номер, остаток и записи трансакций. Как в системе будут возвращаться и обновляться эти данные? После детального изучения всех ситуаций использования, связанных с клиентом, следующим шагом будет анализ ситуаций использования для всех оставшихся пользователей. В примере с ATM можно получить следующий список ситуаций использования для разрабатываемой нами системы: • Клиент проверяет остатки на своих счетах. • Клиент кладет деньги на свой счет. • Клиент снимает деньги со своего счета. • Клиент переводит деньги со счета на счет. • Клиент открывает счет. • Клиент закрывает счет. • Клиент получает доступ к своему счету. • Клиент проверяет недавние трансакции. • Банковский служащий получает доступ к специальному управляющему счету. • Банковский служащий регулирует выплаты по счетам клиентов. • Банковская компьютерная система обновляет счет клиента на основе внешних поступлений. • Изменения на счете клиента отображаются и возвращаются в банковскую компьютерную систему. • ATM сигнализирует об отсутствии наличных денег для выдачи. • Банковский клерк заправляет ATM наличными и включает его. Создание модели доменаПосле того как сделан первый набросок ситуаций использования системы, можно приступать к описанию в документе требований модели домена. Модель домена — это документ, фиксирующий все, что известно о домене (области использования программного продукта). Модель домена состоит из объектов домена, каждый из которых соответствует определенному элементу, упоминавшемуся при описании ситуаций использования системы. В нашем примере с кассовым аппаратом необходимо учесть следующие объекты: клиент, персонал банка, банковская компьютерная система, расчетный счет, депозитный счет и т.д. Для каждого из этих объектов домена требуется зафиксировать такие данные: имя (например, клиента, счета и т.д.), основные атрибуты объекта, является ли объект пользователем и прочее. Многие средства моделирования поддерживают фиксирование такого рода информации в описаниях классов. На рис. 18.4 показано, как эта информация фиксируется с помощью системы Rational Rose. Важно понять, что мы имеем дело не с программными объектами, а с реальными фигурантами, которых следует учитывать при разработке проекта. Никто не заставляет нас для каждого объекта домена создавать объекты в программе. 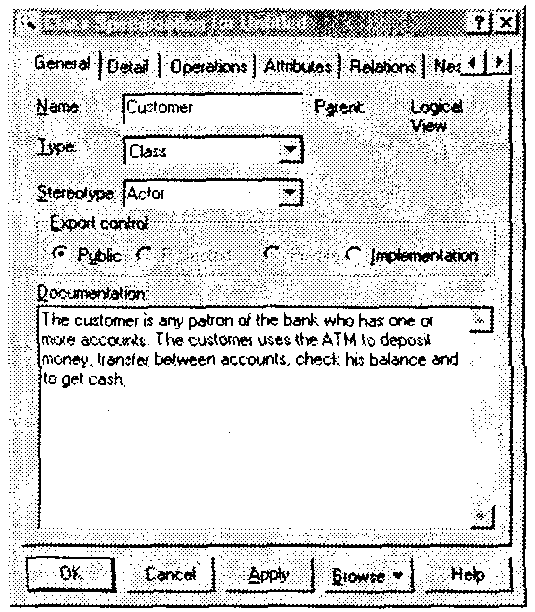 Рис. 18.4. Система Rational Rose Используя соглашения UML, можно создать диаграмму для нашего кассового аппарата, в которой будут отражены отношения между объектами домена точно так же, как изображаются отношения между классами в программе. В этом одна из сильных сторон UML: на всех этапах проектирования можно использовать одни и те же средства. Например, можно зафиксировать, что расчетный и депозитный счета являются уточнениями более общего понятия банковского счета. Как уже отмечалось, в UML обобщение производных классов в базовый отображается с помощью стрелок (рис. 18.5). На диаграмме, показанной на этом рисунке, прямоугольники представляют различные объекты домена, а стрелки, направленные вверх, означают обобщение частных объектов в общий. Таким образом, в терминах языка C++ можно сказать, что объекты домена Расчетный счет и Депозитный счет являются производными от объекта Банковский счет. 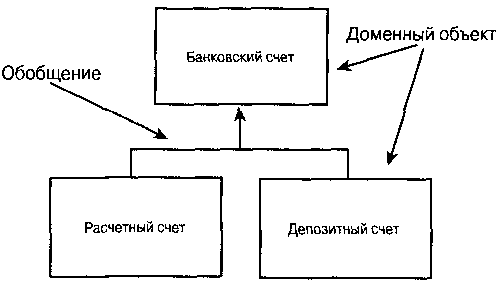 Рис. 18.5. Отношения между объектами домена, выраженные средствами UML UML — богатый язык моделирования, с помощью которого можно фиксировать самые разные отношения. Однако для нас наиболее важными будут отношения обобщения, вложения и ассоциации. Примечание:Вновь обратите внимание, что в данном случае рассматриваются отношения между объектами домена. Позднее, при разработке проекта, возможно, вы захотите реализовать эти отношения между объектами классов CheckingAcnount (Расчетный счет) и BankAccount (Банковский счет), используя наследование классов, но это будет лишь один из возможных вариантов разработки проекта. Пока что мы просто пытаемся разобраться, как взаимодействуют друг с другом реальные объекты домена. ОбобщениеОбобщение часто рассматривают как синоним наследования, но между ними есть существенное отличие. Обобщение описывает вид отношений, а наследование является реализацией обобщения средствами программирования. Обобщение подразумевает, что производный объект является подтипом базового. Таким образом, расчетный счет является видом банковского счета. В свою очередь, банковский счет обобщает атрибуты и свойства расчетного и депозитного счетов. ВложениеЧасто один объект состоит из многих подобъектов. Например, автомобиль состоит из руля, шин, дверей, коробки передач и т.п. Расчетный счет состоит из сальдо, записи трансакций, кода клиента и т.д. Мы говорим, что расчетный счет содержит эти объекты в себе, другими словами, эти объекты вложены в расчетный счет. Вложенность, или содержание в себе средствами UML обозначается стрелкой с ромбом на конце, которая направлена от внешнего объекта к внутреннему (рис. 18.6). 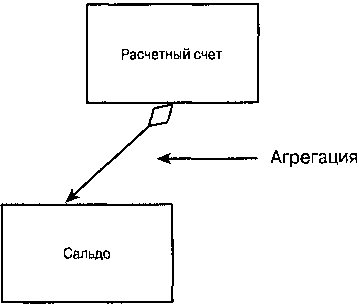 Рис. 18.6. Отношение вложения 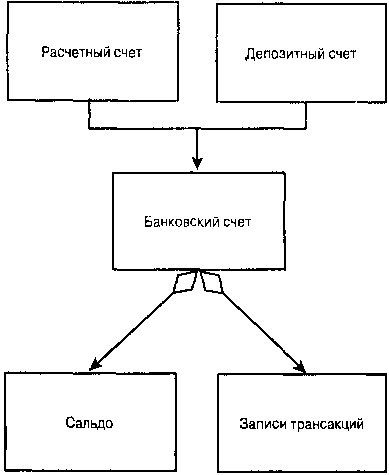 Рис. 18.7. Сложные отношения между объектами Диаграмма на рис. 18.6 показывает, что объект Расчетный счет содержит в себе другой доменный объект — Сальдо, Чтобы показать достаточно сложный набор отношений, две предыдущие диаграммы можно скомбинировать (рис, 18.7). Диаграмма на рис. 18.7 показывает, что объекты Расчетный счет и Депозитный счет обобщены в Банковский счет, а в объект Банковский счет вложены объекта Сальдо и Записи трансакций. АссоциацияТретье отношение — ассоциация обычно фиксируется во время анализа домена Ассоциация предполагает, что два объекта "знают" друг друга и некоторым образом взаимодействуют. Определение станет намного точнее на этапе проектирования, но для анализа лишь предполагается, что Объект А и Объект Б взаимодействуют, но ми один из них не содержит и не является частным видом другого. В UML эта ассоциация показана с помощью простой прямой линии между объектами (рис, 18.8). 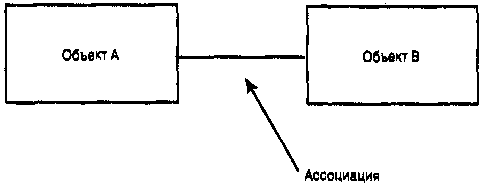 Рис. 18.8. Отношение ассоциации Диаграмма на рис. 18.8 означает, что Объект А некоторым образом взаимодейетву' ет с Объектом Б. Разработка сценариевТеперь, когда мы разобрались со всеми ситуациями использования программы и средствами отображения отношений между объектами домена, можно углубиться в детализацию требований к программному продукту. Каждый случай использования можно разбить на ряд сценариев. Сценарий — это описание определенного набора обстоятельств, конкретизирующих ситуации использования. Например, ситуация использования, при которой клиент снимает деньги со счета, может иметь несколько сценариев. • Клиент делает запрос на снятие $300 с расчетного счета, кладет наличные в кошелек и ожидает квитанции. • Клиент делает запрос на снятие $300 с расчетного счета, но остаток на счете составляет всего $200. Ему поступает информация, что для выполнения операции недостаточно денег на расчетном счете. • Клиент делает запрос на снятие $300 с расчетного счета, но сегодня с этого счета уже сняли $100, а дневной лимит составляет $300. Поступает информация, что ему разрешается снять только $200. • Клиент делает запрос на снятие $300 с расчетного счета, но в рулоне для печатания квитанций закончилась бумага. Ему поступает информация о возникшей технической неисправности и предложение подождать, пока персонал банка устранит эту проблему. Список сценариев можно продолжить. Каждый сценарий определяет вариант первоначальной ситуации использования системы. Часто такие варианты являются исключительными ситуациями (недостаточно денег на счете, техническая неисправность и т.д.). Иногда сценарий содержит в себе вариант решения, предлагаемого пользователю. Например, предложение клиенту перевести деньги со счета до его закрытия. Различных сценариев можно придумать бесчисленное множество, но отобрать среди них следует только те, на которые система готова ответить определенными действиями, сформулированными в требованиях к ней. Разработка путеводителейОпределив список сценариев для каждой ситуации использования, необходимо разработать путеводители для всех сценариев, которые включаются в документ требований и содержат ряд определений. • Предварительные условия, определяющие начало сценария. • Переключатели, включающие выполнение именно этого сценария. • Действия, выполняемые пользователем. • Требуемые результаты выполнения программы. • Информация, возвращаемая пользователю. • Запускаемые циклы и условия выхода из них. • Логическое описание сценария. • Условие завершения сценария. • Итоги выполнения сценария. Кроме того, в документе требований нужно указать ситуацию использования и имя сценария, как в следующем примере. Ситуация использования: Клиент снимает наличные со счета Сценарий: Успешное снятие наличных с расчетного счета Предварительные условия: Клиент уже имеет доступ в систему Переключатель: Запрос от клиента на снятие денег со счета Описание: От клиента поступил запрос на снятие денег с расчетного счета. На счете имеется достаточная сумма. В кассовом аппарате достаточно денег и заправлена бумага для квитанций; сеть включена и работает. ATM просит клиента указать сумму денег для снятия. Клиент указывает сумму, не превышающую $300. Машина выдает деньги и печатает квитанцию Итоги: Со счета клиента снята указанная сумма; сальдо счета уменьшено на эту сумму Эту ситуацию использования можно изобразить с помощью простой диаграммы, представленной на рис. 18.9. Диаграмма не может похвастаться обилием отображаемой информации. Отношения между пользователем и системой показаны довольно абстрактно. Эта диаграмма станет гораздо полезнее, когда будут показаны взаимоотношения между разными ситуациями использования. Таких отношений может быть только два: использование и расширение. Отношение использования означает, что одна ситуация использует другую. Например, невозможно снять деньги со счета без регистрации в системе. Это отношение показано на рис. 18.10. 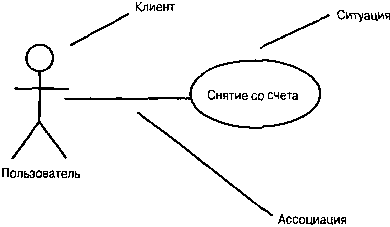 Рис. 18.9. Диаграмма ситуации использования 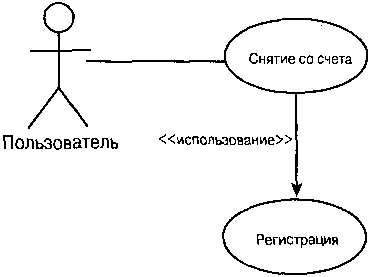 Рис. 18.10. Отношение подчинения между На рис. 18.10 показано, что для снятия денег со счета необходимо выполнить регистрацию в системе. Таким образом, ситуация Снятие со счета использует ситуацию Регистрация в системе, т.е. операция регистрации является частью операции снятия со счета. Расширение ситуации использования подразумевает установление каких-то логических условных отношений между разными ситуациями, что также может реализо- вываться наследованием классов. Вообще, среди специалистов по объектному моделированию существует столько разногласий по поводу того, чем отличается использование от расширения, что многие из них просто не применяют второй термин, считая его слишком неопределенным. Лично я обращаюсь к термину использование, когда одна операция абсолютно необходима для выполнения другой. Если же выполнение операции ограничивается рядом условий, то я пользуюсь термином расширение ситуации использования. Диаграммы взаимодействийХотя диаграмма ситуации использования вряд ли представляет собой большую ценность, такого рода диаграммы можно комбинировать, что значительно улучшает документацию и понимание взаимоотношений объектов системы. Например, известно, что сценарий ситуации Снятие со счета представляет взаимодействие между такими объектами домена, как клиент, расчетный счет и интерфейс пользователя системы. Это можно документировать диаграммой взаимодействий, показанной на рис. 18.11. Эта диаграмма фиксирует детали сценария, которые могут не быть очевидными при чтении текста. Взаимодействующие объекты являются объектами домена. Весь пользовательский интерфейс кассового аппарата рассматривается как единый объект. В деталях рассматривается только определение системой расчетного счета в банке и снятие с него заказанной суммы денег. 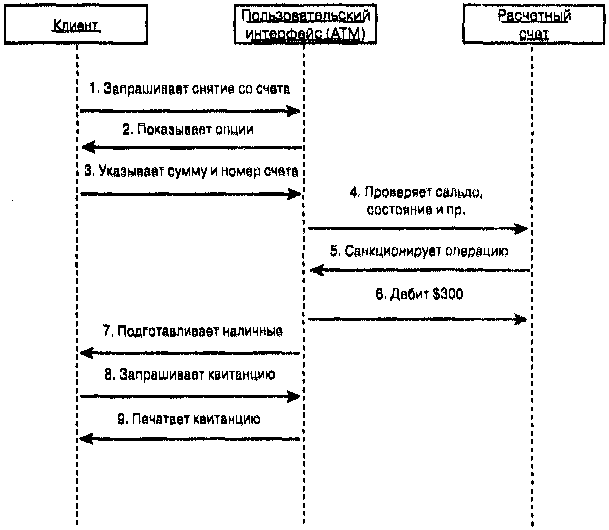 Рис.18.11. Диаграмма взаимодействий системы кассового аппарата АTM с клиентом при выполнении операции снятия со счета Отношения между объектами домена пока раскрыты лишь в общих чертах, но это уже большой шаг в выявлении ключевых моментов этих отношений, на базе которых будут формироваться требования к разрабатываемой системе. Создание пакетовТак как при анализе любой более-менее серьезной проблемы число возможных ситуаций использования разрастается как снежный ком, бывает сложно отобразить все эти ситуации в одной диаграмме. Язык моделирования UML предоставляет возможность группировать различные ситуации в пакеты. Пакет напоминает папку в файловой системе компьютера. Он является набором объектов моделирования (классов, деятелей и т.п.). Чтобы упорядочить ситуации использования, их можно распределить по пакетам в соответствии с конкретными логическими концепциями. Так, можно объединить вместе ситуации использования определенных банковских счетов (расчетных или депозитных) либо разделить их по типам клиентов или любым другим важным характеристикам. Одна и та же ситуация использования может быть представлена в разных пакетах, в результате чего между пакетами образуются логические взаимосвязи. Анализ совместимости приложенияВ дополнение к определению ситуаций использования в документе требований следует четко описать предполагаемых клиентов системы, ограничения и требования к вычислительной аппаратуре и операционным системам. Документ требований к приложению можно представить как первого абстрактного пользователя вашей системы, желания и предпочтения которого следует учесть при разработке приложения. От того, насколько точно документ требований будет отражать чаяния, умения и навыки реальных клиентов, зависит успех вашего проекта. На требования к приложению часто накладывают отпечаток реалии существующих аппаратных и программных систем, под которые разрабатывается проект. Очень важно, чтобы новая система органично влилась в те системы и структуры, которые на данный момент уже существуют у заказчика. В идеале программист разрабатывает проект решения поставленных задач, а затем определяет, какая платформа и операционная система максимально подходят для проекта. Этот сценарий сколь идеален, столь и уникален. Чаще заказчик уже давно потратил деньги на определенную операционную систему или аппаратное обеспечение, а теперь хочет с их помощью реализовать новый проект. Важно еще на ранней стадии проектирования зафиксировать реальное программное и аппаратное обеспечение заказчика, чтобы строить новый проект в соответствии с этими реалиями. Анализ существующих системНекоторые программы пишутся, чтобы работать самостоятельно вне каких бы то ни было систем, напрямую взаимодействуя лишь с конечным пользователем. Однако часто приходится разрабатывать проекты, которые необходимо внедрить в уже существующую систему. В таком случае следует проанализировать все детали и механизмы работы систем, с которыми требуется наладить взаимодействие. Будет ли создаваемая система сервером, обслуживающим существующую систему, или ее клиентом? Сможете ли вы добиться однотипности интерфейсов двух систем и адаптировать свой проект к имеющимся стандартам? Будут ли взаимосвязи с существующей системой статическими или динамическими? На эти и аналогичные вопросы следует отвечать на этапе анализа, прежде чем вы приступите к проектированию новой системы. Кроме того, необходимо зафиксировать те ограничения, которые могут возникнуть косвенно в результате взаимодействия двух систем. Не замедлит ли новая система работу существующей системы, не исчерпает ли она предоставляемые ресурсы и машинное время и т.д. Прочая документацияКогда наконец-то придет понимание того, что система должна делать и как себя вести, необходимо уточнить бюджет и сроки проекта. Часто крайний срок диктуется заказчиком: "На эту работу у вас 18 месяцев". У программиста на этот счет может быть свое мнение, которое необходимо высказать. Идеально, если заказчик и исполнитель придут к компромиссу, но в любом случае время и бюджет всякого проекта всегда ограничены. Уложиться в сроки и не превысить бюджет часто бывает труднее, чем написать программу. При определении бюджета и сроков следует учесть два момента. • Если вы определили, во сколько в среднем обойдется проект, то попросите немного больше, тогда, может быть, вам дадут ту сумму, на которую вы рассчитывали. • Закон Либерти утверждает, что на все требуется больше времени, чем ожидалось, даже если был учтен закон Либерти. После того как время и бюджет будут установлены, определитесь с приоритетами. Вы все равно не уложитесь в срок, будьте к этому готовы. Важно, чтобы к тому моменту, когда нужно будет что-то показывать, у вас уже было что показать. Если вы строили мост, а время уже истекло, то позаботьтесь о том, чтобы была проложена хотя бы велосипедная дорожка. Это, конечно, не Бог весть что, но лучше чем ничего. По крайней мере, можно будет попросить денег на продолжение. Если же время истекло, а вы дошли только до середины реки, то это еще хуже. Ко всем цифрам, зафиксированным в документации, следует относиться серьезно, но не "брать дурного в голову". В начале работ фактически невозможно точно оценить сроки выполнения проекта. Желательно приберечь для себя от 20 до 25% времени для маневра, если в ходе выполнения проекта возникнут неожиданности. В конце концов, для всех важен успех проекта и обоснованные колебания в сроках всегда допустимы. Примечание:Мы вовсе не призываем к бесшабашному отношению к срокам, зафиксированным в документе. Просто реалии таковы, что на ранних этапах планирования невозможно точно определить, сколько времени и денег потребуется на разработку этого проекта. Приоритетом при этом должна быть максимальная реализация требований заказчика, что, вполне вероятно, может вызвать необходимость корректировки исходных цифр при выполнении проекта. ВизуализацияВизуализация является финальной частью документа требований. Такое модное название носят диаграммы, рисунки, изображения экранов, прототипы и другие визуальные средства, созданные для того, чтобы помочь в проектировании графического интерфейса пользователя создаваемого продукта. При создании больших проектов бывает полезно разработать полный прототип проекта, чтобы лучше представить, как поведет себя система в тех или иных ситуациях. Часто графическое приложение к документации лучше всего справляется с функцией определения требований к проекту, так как позволяет наглядно увидеть, какой должна быть система и как она должна работать в конечном варианте. АртефактыК концу каждого этапа анализа и проектирования накапливается ряд документов, называемых артефактами. Приблизительный набор таких документов показан в табл. 18.1. Эти документы используются для организации взаимодействия и протоколирования отношений между заказчиком и исполнителем. Их подписание обеими сторонами гарантирует, что исполнитель четко понял и принял все требования заказчика и обязуется разработать в указанные сроки проект, который в окончательном варианте должен выполнять точно определенный ряд функций. Таблица 18.1. Артефакты, составляющие документацию проекта 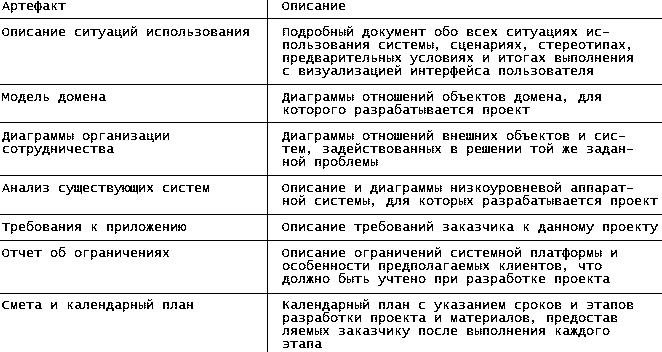 ПроектированиеВо время анализа основное внимание уделяется рассмотрению домена и определению задач и требований к проекту, в то время как проектирование сосредоточено на поиске решений. Проектирование — это планирование практической реализации нашей идеальной модели средствами программирования. Результатом этого процесса является создание документа проекта приложения. Документ проекта состоит из двух разделов: проекта классов и архитектуры приложения. Первый раздел, в свою очередь, содержит статический (описание различных классов, их структуры и характеристик) и динамический (описание взаимодействий классов) подразделы. В разделе "Архитектура приложения" определяется время жизни различных объектов, их взаимоотношения, системы передачи объектов и другие механизмы реализации классов. Далее на этом занятии основное внимание уделяется проектированию классов, а все оставшиеся занятия посвящены рассмотрению различных структур архитектуры приложения. Что такое классыИзучая материалы этой книги, вы уже не раз делали попытку создавать классы в программах на языке C++. Но поскольку в данный момент речь идет не о разработке программы, а о ее проектировании, следует различать проекты классов и их реализацию средствами C++, хотя, безусловно, эти моменты тесно взаимосвязаны. Каждому классу в проекте будет соответствовать класс в программном коде, но все же не надо их путать. Ведь для реализации спроектированного класса можно использовать другой язык программирования, и даже в пределах C++ для реализации класса можно использовать различные средства программирования. Далее не будем заострять на этом внимание, просто помните, что если планируется создать класс Кот с методом Мяу(), то в программу будут добавлены класс Cat с методом Meow(), хотя реализовать их можно по-разному. Обратите внимание, что в тексте книги для классов проекта и классов программы использованы разные стили, чтобы помочь вам отличать их. Классы модели приложения отображаются в диаграммах UML, а классы C++ — в коде программы, который можно скомпилировать и запустить. У начинающих программистов часто возникает проблема с определением необходимого количества классов для программы и функций, которые должен выполнять каждый отдельный класс. Один из наиболее упрощенных подходов к решению этой проблемы состоит в записи сценария для ситуации использования приложения. Затем можно попытаться создать классы для каждого сушествительного (объекта), упоминающегося в этом сценарии. Возьмем для примера приведенный ниже сценарий. Клиент выбирает операцию снятия наличных с расчетного счета. На счете в банке имеется достаточная сумма, в ATM достаточно наличных и заправлена лента для квитанций, а сеть включена и работает. Кассовый аппарат ATM просит указать сумму, которая не должна превышать $300. Машина выдает указанную сумму и печатает квитанцию для клиента. Из этого сценария можно извлечь такие классы: • клиент; • сумма; • наличные; • расчетный счет; • счет; • квитанция; • лента для квитанций; • банк; • ATM; • сеть; • снятие со счета; • машина. Объединив синонимы и явно взаимосвязанные объекты, получаем следующий список: • клиент; • наличные (суммы на счете и снимаемая со счета); • расчетный счет; • счет; • квитанции; • ATM (кассовый аппарат); • сеть. Пока что неплохо для начала. Можно затем отобразить отношения между классами, как показано на рис. 18.12. 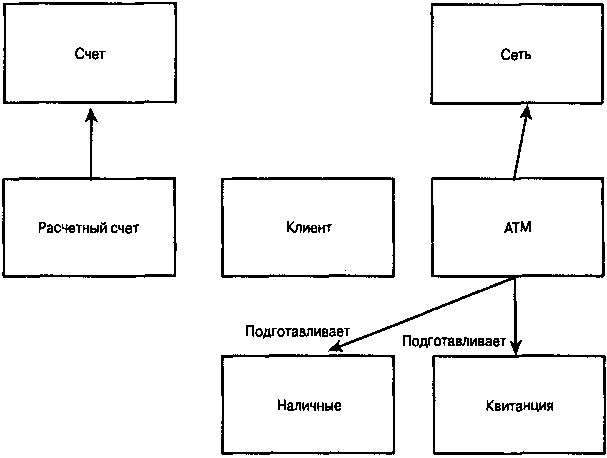 Рис. 18.12. Предварительная схема отношений между классами ПреобразованияОписанный в предыдущем разделе подход называется преобразованием объектов домена в объекты проекта. Большинству объектов домена в проекте соответствуют суррогаты. Термин "суррогат" вводится для того, чтобы отличать реальную квитанцию, выданную кассовым аппаратом, от виртуального объекта в программе, являющегося абстракцией, реализованной в программном коде. Многие объекты домена имеют в проекте изоморфное представление, т.е. между объектами домена и проекта существует отношение один-к-одному. В других случаях, однако, один объект домена представлен в проекте целым рядом объектов. Иногда множества объектов домена могут быть представлены одним объектом в проекте. Обратите внимание: на рис. 18.12 уже зафиксирован факт, что Расчетный счет является специализацией Счета. Аналогично, из анализа объектов домена известно, что кассовый аппарат ATM подготавливает и выдает Наличные и Квитанцию, поэтому данные отношения зависимости классов также отображены на рис. 18.12. Отношение между Клиентом и Расчетным счетом менее очевидно. Известно, что такое отношение существует, но детали его пока скрыты, поэтому оставим анализ этого отношения на потом. Другие преобразованияПосле преобразования объектов домена можно начинать поиск других полезных объектов этапа проектирования. Неплохо начать с создания интерфейсов. Каждый интерфейс между новой системой и любой из существующих (унаследованных) систем должен быть инкапсулирован в класс интерфейса. (Напомним, что мы занимаемся проектированием, а не написанием программы, поэтому не путайте класс интерфейса в проекте приложения с интерфейсом класса в коде приложения. Подмена этих терминов вызовет бессмыслицу.) Если будет осуществляться взаимодействие с базой данных определенного типа, это тоже следует зафиксировать в классе интерфейса. Классы интерфейса инкапсулируют протоколы интерфейса и таким образом защищают код программы от изменений в другой системе. Они позволяют менять ваш собственный проект или подстраиваться к изменениям структуры других систем, не нарушая остального кода. Пока две системы продолжают поддерживать согласованный интерфейс, они могут развиваться независимо друг от друга. Обработка данныхАналогично создаются классы обработки данных. Если надо сделать преобразование из одного формата в другой (например, из градусов Фаренгейта в градусы Цельсия или из английской системы в метрическую), то эти операции можно инкапсулировать внутри класса обработки данных. Этот прием можно использовать при отправке данных в другие системы в определенном формате или для передачи данных в Internet. В общем, каждый раз, когда надо преобразовать данные в определенный формат, протокол следует инкапсулировать в классе обработки данных. ОтчетыКаждый отчет, выводимый системой (или связанная группа отчетов) является кандидатом в классы. Протокол формирования отчета, куда входит сбор информации и способ ее отображения, следует инкапсулировать в класс обзора. УстройстваЕсли система взаимодействует с устройствами или управляет ими (такими как принтеры, модемы, сканеры и т.п.), то особенности протокола устройства следует инкапсулировать в классе устройства. Благодаря этому, внося изменения в класс устройства, можно подключать к системе новые устройства, не нарушая остального кода. Статическая модельКогда создан первоначальный набор классов, пора начинать моделировать их отношения и взаимодействия. Для большей ясности сначала объясним статическую модель, а затем — динамическую. При реальном процессе проектирования можно свободно переходить от одной модели к другой, заполняя обе подробностями, фактически добавляя новые классы и описывая их по мере продвижения. Статическая модель сосредоточена в трех областях: распределении ответственности, атрибутах и взаимодействии. Наиболее важная из них (на что в первую очередь обратим внимание) — это распределение ответственности между классами. Перед каждым классом должна быть поставлена одна конкретная задача, за выполнение котб- рой он несет ответственность. Это не означает, что у каждого класса есть только один метод. Класс может содержать десятки методов. Однако все они должны быть согласованными и взаимосвязанными, т.е. должны обеспечивать выполнение единой задачи. В хорошо спроектированной системе каждый объект является экземпляром класса, имеющего четко определенный набор функций и отвечающего за выполнение конкретной задачи. Классы обычно делегируют несвойственные им задачи другим, связанным с ними классам. Создание классов, имеющих одну область ответственности, — основа написания читабельного и легко поддерживаемого кода. Чтобы разобраться с ответственностью классов, следует начать проектирование с создания карточек CRC. Карточки CRCCRC означает Class (класс), Responsibility (ответственность), Collaboration (сотрудничество). CRC представляет собой обычную бумажную карточку размером, не превышающим используемые в картотеках. Работая с такими карточками, вы, как Чапаев с помощью картошки, сможете наглядно объяснить коллегам, которым будет поручена разработка отдельных классов, как вы мыслите наладить распределение ответственности за выполнение тактических и стратегических задач между классами проекта. Как проводить заседания с карточкамиНа каждое заседание с карточками следует приглашать от трех до шести человек. Если людей больше, то теряется управляемость. Кроме того, во время дискуссии гораздо проще прийти к консенсусу, если в заседании участвует не слишком много людей. Кратко остановимся на том, кто в идеале должен участвовать в разработке серьезного проекта (если вы не хотите свалить на себя всю ответственность за провал). Итак, вы главный исполнитель. Пригласите как минимум одного ведущего специалиста по программной архитектуре, имеющего опыт в анализе и проектировании объектно-ориентированных программ. Не мешает также включить в состав минимум одного или двух "экспертов по домену", не понаслышке знающих проблему, которую вы хотите решить с помощью разрабатываемой программы. В будущем вам потребуются менеджеры (если не адвокат), но не сейчас. Это творческое непринужденное заседание не для прессы и не для рекламы. Цель состоит в том, чтобы провести исследование, высказать рискованные предложения и в ходе дискуссии решить, какой класс нагрузить той или иной проблемой. Заседание по CRC начинается с того, что группа рассаживается за столом, на котором лежит небольшая стопка карточек. В верхней части каждой из них пишется название одного из классов. Начертите сверху вниз линию, разделив карточку на две части, и слева напишите Ответственность, а справа — Сотрудничество. Начинайте заполнять карточки по самым важным из определенных вами классов. С обратной стороны дайте небольшое описание в одно или два предложения. Можно также указать, уточнением (производным) какого класса является данный класс, если это очевидно к моменту работы с карточкой. Просто под именем класса напишите Надкласс: и впишите имя класса, от которого данный класс производится. Сфокусируемся на распределении ответственностиОсновным пунктом повестки дня заседания является определение ответственности каждого класса. Не обращайте много внимания на атрибуты, фиксируйте по мере продвижения только самые существенные и очевидные из них. Если для выполнения задачи класс должен делегировать часть работы другому классу, то эта информация указывается в столбце Сотрудничество. В ходе работы обращайте внимание, сколько пунктов появилось на карточке класса в столбце Ответственность. Если на карточке не хватает места, то это повод задуматься, не следует ли разделить данный класс на два. Помните, каждый класс должен отвечать за выполнение одной задачи, поэтому все пункты в столбце Ответственность должны быть логически и функционально взаимосвязанными. На данном этапе проектирования не стоит задумываться над тем, каким образом будет объявлен класс в программе и сколько открытых и закрытых методов он будет содержать. Обращайте внимание только на то, за что этот класс отвечает. Как сделать класс живымГлавным свойством карточек CRC является то, что их можно сделать антропоморфными, т.е. каждый класс наделяется свойствами человека. Посмотрим, как это работает. После определения первоначального набора классов разложите по кругу на столе карточки CRC в произвольном порядке и вместе пройдитесь по сценарию. Например, вернемся к предложенному ранее сценарию. Клиент выбирает операцию снятия наличных с расчетного счета. На счете в банке имеется достаточная сумма, в ATM достаточно наличных и заправлена лента для квитанций, а сеть включена и работает. Кассовый аппарат ATM просит указать сумму, которая не должна превышать $300. Машина выдает указанную сумму и печатает квитанцию для клиента. Предположим, в заседании участвуют пять человек: Эмма — ваш помощник, сведущая в объектно-ориентированном программировании; Борис — ведущий программист; Сергей — будущий клиент вашей системы; Олег — эксперт по домену; а также Эдик — программист. Эмма держит карточку CRC класса Расчетный счет и говорит: "Я сообщаю клиенту, сколько можно получить денег. Он просит меня дать $300. Я посылаю сообщение на устройство выдачи, чтобы было выдано $300 наличными". Борис держит свою карточку и говорит: "Я устройство выдачи; я выдаю $300 и посылаю Эмме сообщение, чтобы она уменьшила остаток на счете на $300. Кому я должен сообщить, что в машине стало на $300 меньше? Должен ли я это отслеживать?" Сергей: "Думаю, нужен объект для слежения за наличностью в машине". Эдик: "Нет. Кассовый аппарат сам должен знать, сколько у него осталось денег; это не должно нас волновать". Эмма возражает: "Нет. Выдачу денег кто-то должен контролировать. Программа должна знать, доступна ли наличность и достаточно ли у клиента денег на счете. Кроме того, программа должна проследить, было ли выдано аппаратом именно столько денег, сколько было заказано. Учет денег в кассовом аппарате следует делегировать некоему внутреннему счету. Необходимо также, чтобы система оповещала технический персонал банка о том, что в кассовом аппарате закончились деньги". Спор продолжается. Каждый класс реально стал человеком, который держит соответствующую карточку в руках и заполняет столбцы ответственности и сотрудничества. Ограничения карточек CRCХотя карточки CRC могут быть мощным средством в начале проектирования, их возможности ограничены. Первая проблема в том, что большой проект может состоять из большого числа классов. Тогда в карточки можно будет зарыться с головой. Взаимоотношения между классами прорабатываются недостаточно. Правда, фиксируется сотрудничество, но его природа и механизмы не моделируются. По карточкам не видно, какие классы вкладываются в другие классы, какие наследуются, а какие ассоциируются. В карточках не отмечаются атрибуты класса, определяющие его внутреннюю структуру, поэтому трудно перейти от карточек прямо к коду. Нужно помнить, что карточки статичны по своей природе и, хотя в них и записываются в общем виде отношения между классами, они не годятся для построения динамической модели. Короче говоря, карточки CRC являются хорошим началом, но для построения более полной модели проекта нужно перейти к UML. После создания модели UML карточки можно будет отложить в сторону. Они вам больше не потребуются. Создание модели UML no картонкам CRCКаждой карточке будет соответствовать класс диаграммы UML. Пункты из столбца Ответственность становятся методами класса. Также в диаграмму переносятся все зафиксированные атрибуты класса. Определение класса с обратной стороны карточки помещается в документацию класса. На рис. 18.13 показана диаграмма отношения между классами Счет и Расчетный счет, атрибуты класса Расчетный счет взяты с соответствующей карточки CRC, показанной ниже. 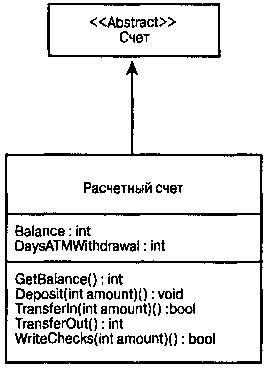 Рис. 18.13. Отображение данных карточки CRC на диаграмме Класс: Расчетный счет Надкласс: Счет Ответственность: Отслеживать текущий остаток Принимать и переводить депозиты Выдавать чеки Переводить деньги при снятии со счета Сохранять баланс выдачи кассового аппарата за текущий день Сотрудничество: Другие счета Компьютерная система банка Устройство выдачи наличных Отношения между классамиПосле того как классы будут отображены средствами UML, можно заняться отношениями между ними. Рассматриваются четыре основных вида отношений. • Обобщение. • Ассоциация. • Агрегирование. • Композиция. Обобщение реализуется в C++ с помощью открытого наследования. Но с точки зрения проектирования больше внимания следует уделять не механизму, а семантике: что именно подразумевает это отношение. Мы уже говорили об обобщении на этапе анализа, но теперь рассмотрим этот вид отношений применительно к классам проекта. Нашей задачей будет вынести общие действия за границы взаимосвязанных классов в общий базовый класс, который инкапсулирует общую ответственность. Таким образом, если обнаружено, что расчетный и депозитный счета используют одни и те же методы для перевода денег, то в базовый класс Счет можно перенести метод TransferFunds(). Чем больше методов будет сосредоточено в базовых классах, тем более полиморфным становится проект. Одним из средств программирования, доступных в C++, но не в Java, является множественное наследование (однако Java имеет похожее, хотя и ограниченное средство, позволяющее создавать множественные интерфейсы). Это средство позволяет производить класс более чем от одного базового класса, добавляя переменные-члены и методы двух и более классов. Опыт показывает, что множественное наследование надо использовать умеренно, так как оно может усложнить программный код проекта. Многие проблемы, вначале решаемые с помощью множественного наследования, теперь решаются путем агрегирования (вложения) классов. Тем не менее множественное наследование остается мощным средством программирования, от которого не следует огульно отказываться при разработке проектов. Множественное наследование против вложенияЯвляется ли объект суммой его частей? Имеет ли смысл классы деталей автомобиля, такие Руль, Двери и Колеса, производить от общего класса Автомобиль, как показано на рис. 18.14? 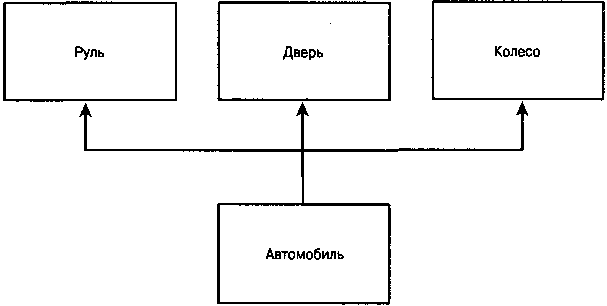 Рис. 18.14. Возможно, но не умно Важно вернуться к основам: открытое наследование должно всегда моделировать обобщение, т.е. производный класс должен быть уточнением базового класса, чего не скажешь о приведенном выше примере. Если требуется смоделировать отношение "иметь" (например, автомобиль имеет руль), то это делается с помощью агрегирования (рис. 18.15). Диаграмма на рис. 18.15 показывает, что автомобиль имеет руль, четыре колеса и от двух до пяти дверей. Это более точная модель отношения автомобиля и его частей. Обратите внимание, что ромбик на диаграмме не закрашен. Это потому, что отношение моделируется с помощью агрегирования, а не композиции. Композиция подразумевает контроль за временем жизни объекта вложенного класса. Хотя автомобиль имеет шины и дверь, но они могут существовать и до того, как станут частями автомобиля, и после того, как перестанут ими быть. 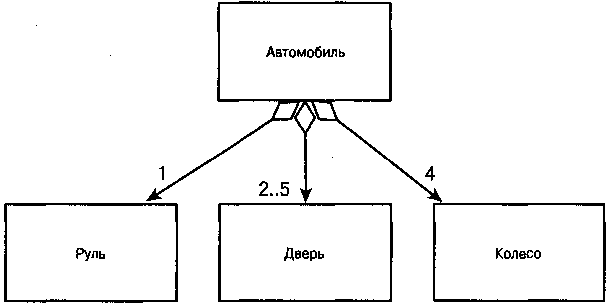 Рис. 18.15. Модель агрегирования На рис. 18.16 показана модель композиции. Эта модель сообщает нам, что класс "тело" не только включает в себя (что можно было бы реализовать агрегированием) голову, две руки и две ноги, но что эти объекты (голова, руки и ноги) будут созданы при создании тела и исчезнут вместе с ним. Иными словами, они не имеют независимого существования. 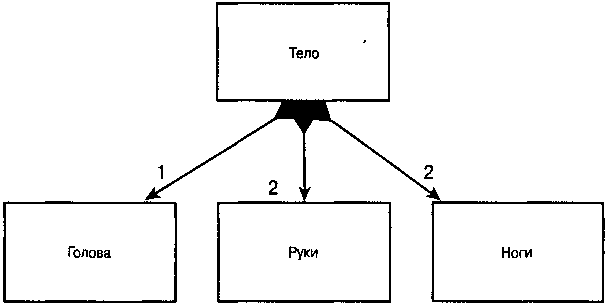 Рис. 18.16. Модель композиции Дискриминаторы и силовые классыКак можно спроектировать производство разных моделей автомобилей одной марки? Предположим, вас наняла фирма Acme Motors, которая производит пять автомобилей: Pluto (компактный малолитражный автомобиль для поездок за покупками), Venus (четырехдверный "седан" с двигателем средней мощности), Mars (спортивный автомобиль типа "купе" с наиболее мощным двигателем, рассчитанный на максимальную скорость), Jupiter (мини-фургон с форсированным двигателем как у спортивного купе, правда, менее скоростной, зато более мощный) и Earth (маломощный, но скоростной фургон). Можно было бы просто произвести все эти модели от общего класса Car, как показано на рис. 18.17. 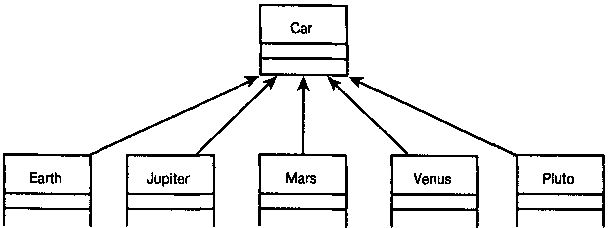 Рис. 18.17. Обобщение подклассов всех моделей в общий базовый класс Но давайте более детально проанализируем различия между моделями. Очевидно, что они различаются мощностью двигателя, типами кузова и специализацией. Комбинируя эти основные признаки, мы получим характеристики различных моделей. Таким образом, в нашем примере важнее сконцентрировать внимание не на названиях моделей, а на их основных признаках. Такие признаки называются дискриминаторами и в UML отображаются особым образом (см. рис. 18.17). 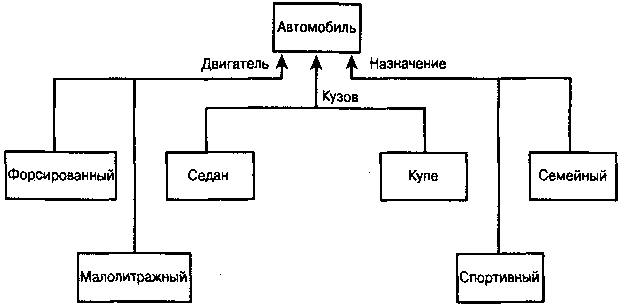 Рис. 18.18. Модель отношения дискриминаторов Диаграмма на рис. 18.18 показывает, что классы разных моделей можно производить от класса Автомобиль, комбинируя такие дискриминаторы, как мощность двигателя, тип кузова и назначение автомобиля. Каждый дискриминатор можно реализовать в виде простого перечисления. Например, объявим перечисление типов кузова: enum BodyType={sedan, coupe, minivan, stationwagon} Однако далеко не каждый дискриминатора можно объявить, просто назвав его. Например, назначение определяется многими параметрами. В таком случае дискриминатор можно смоделировать как класс, и разные типы дискриминатора будут возвращаться как объекты класса. Таким образом, технические характеристики автомобиля, определяющие его использование, могут быть представлены объектом типа performance, содержащим данные о скорости, габаритах и прочих характеристиках. В UML классы, в которых инкапсулирован дискриминатор и которые используются для создания экземпляров другого класса (в нашем примере класса Автомобиль) таким образом, что разные экземпляры класса приобретают характеристики разных типов (например, Спортивный автомобиль и Семейный автомобиль), называются силовыми. В нашем примере класс Назначение (performance) является силовым для класса Автомобиль. При создании объекта класса Автомобиль также создается объект Назначение, который ассоциируется с текущим объектом Автомобиль, как показано на рис. 18.19. Использование силовых классов позволяет создавать различные логические типы, не прибегая к наследованию. Поэтому в программе можно легко манипулировать множеством типов, не создавая класс для каждого нового типа. Обычно в программах на C++ использование силовых классов реализуется с помощью указателей. Так, в нашем примере класс Car (соответствующий классу проекта Автомобиль) будет содержать указатель на объект класса PerformanceCharacteristics (рис. 18.20). Если хотите потренироваться, создайте самостоятельно силовые классы для дискриминаторов Кузов (body) и Двигатель (engine). Class Car:public Vehicle { public: Car(); ~Car(); //другие открытые методы опущены private: PerformanceCharacteristics*pPerformance; }; И наконец, силовые классы дают возможность создавать новые типы данных во время выполнения программы. Поскольку каждый логический тип различается только атрибутами ассоциированных с ним силовых классов, то эти атрибуты могут быть параметрами конструкторов данных силовых классов. Это означает, что можно во время выполнения программы создавать новые типы автомобилей, изменяя установки атрибутов силовых классов. Число новых типов, которые можно создать во время выполнения программы, ограничивается только числом логических комбинаций атрибутов разных силовых классов. Динамическая модельВ модели проекта важно указать не только отношения между классами, но и принципы их взаимодействия. Например, классы Расчетный счет, ATM и Квитанция взаимодействуют с классом Клиент в ситуации Снятие со счета. Возвращаясь к виду последовательных диаграмм, которые использовались в начале анализа (см. рис. 18.11), рассмотрим теперь взаимодействие классов на основе определенных для них методов, как показано на рис. 18.21. 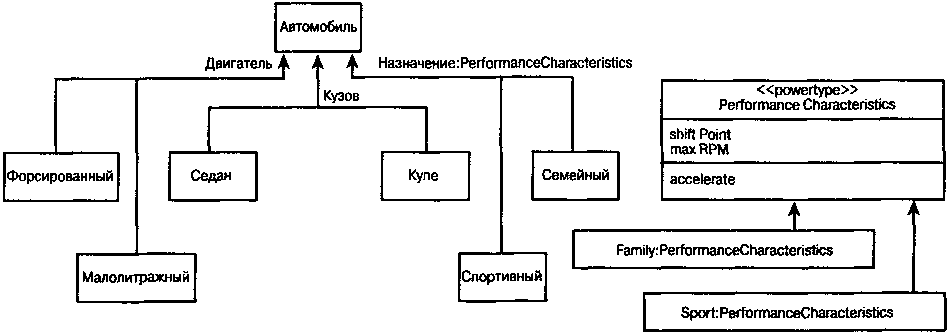 Рис. 18.19. Дискриминатор как силовой класс 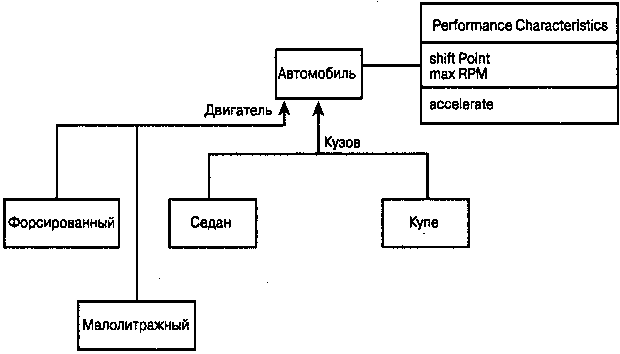 Рис. 18.20. Отношение между объектом класса Автомобиль и связанным с ним силовым классом 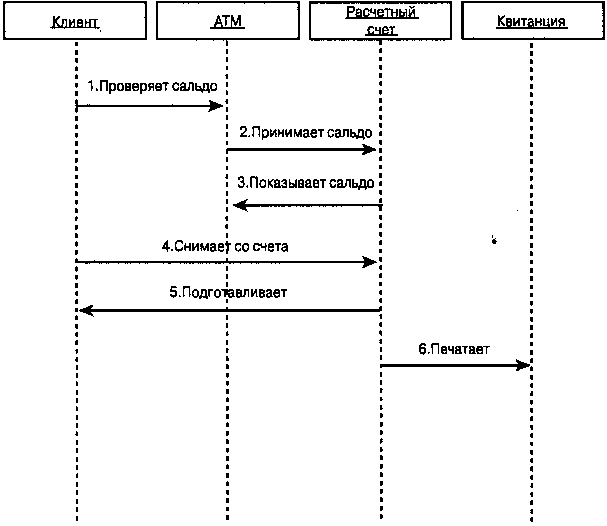 Рис. 18.21. Диаграмма взаимодействия классов Эта простая диаграмма показывает взаимодействие между несколькими классами проекта при определенной ситуации использования программы. Предполагается, что класс ATM делегирует классу Расчетный счет ответственность за учет остатка денег на счете, в то время как Расчетный счет делегирует классу ATM ответственность за доведение этой информации пользователю. Существует два вида диаграмм взаимодействий классов. На рис. 18.21 показана диаграмма последовательности действий. Та же ситуация, но в другом виде, изображена на рис. 18.22 и называется диаграммой сотрудничества. Диаграмма первого типа определяет последовательность событий за некоторое время, а диаграмма второго типа — принципы взаимодействия классов. Диаграмму сотрудничества можно создать прямо из диаграммы последовательности. Такие средства, как Rational Rose, автоматически выполнят это задание после щелчка на кнопке. 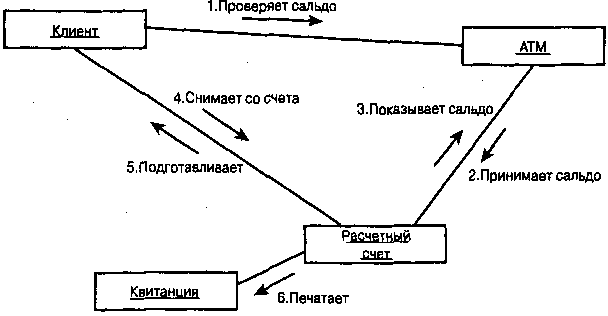 Рис. 18.22. Диаграмма сотрудничества Диаграммы переходов состоянийПосле того как стали понятными взаимодействия между объектами, надо определить различные возможные состояния каждого из них. Моделировать переходы между различными состояниями можно в диаграмме состояний (или диаграмме переходов состояний). На рис. 18.23 показаны различные состояния класса Расчетный счет при регистрации клиента в системе. Каждая диаграмма состояний начинается с состояния Начало и заканчивается нулем или некоторым другим концевым состоянием. Каждое состояние имеет свое имя, и в переходах между состояниями могут быть установлены Сторожа, представляющие собой условия, при выполнении которых возможен переход от состояния к состоянию. СверхсостоянияКлиент может в любое время передумать и не регистрироваться. Он может это сделать после того, как вставил карточку или после ввода пароля. В любом случае система должна принять его запрос на аннулирование и вернуться в состояние Не зарегистрирован (рис. 18.24). Как видите, в более сложной диаграмме, содержащей много состояний, указание на каждом шаге возможности перехода к состоянию Отмена внесет сумятицу. Особенно раздражает тот факт, что отмена является исключительным состоянием, отвлекающим от анализа нормальных переходов между состояниями. Эту диаграмму можно упростить, используя сверхсостояние (рис. 18.25). Диаграмма на рис. 18.25 дает ту же информацию, что и на рис. 18.24, но намного яснее и легче для чтения. В любой момент от начала регистрации и вплоть до ее завершения процесс можно отменить. Если вы это сделаете, то вернетесь в состояние Не зарегистрирован. 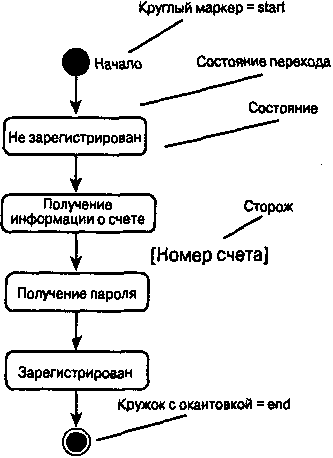 Рис. 18.23. Переходы состояний класса Расчетный счет 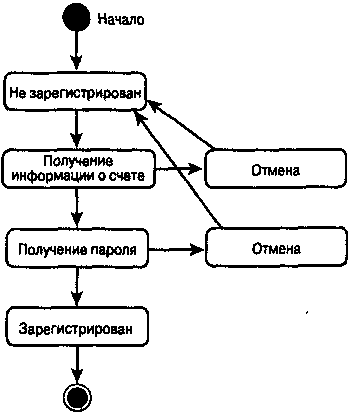 Рис. 18.24. Отмена регистрации 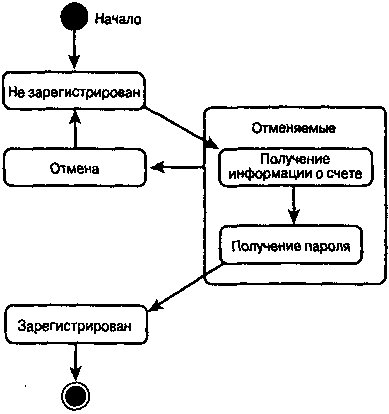 Рис. 18.25. Сверхсостояние РезюмеНа этом занятии в общих чертах рассмотрены вопросы анализа и проектирования объектно-ориентированных программ. Анализ состоит в определении ситуаций и сценариев использования программы, а проектирование заключается в определении классов и моделировании отношений и взаимодействия между ними. Еще не так давно программист быстро набрасывал основные требования к программе и начинали писать код. Современные программы отличаются тем, что работа над ними никогда не заканчивается, если только проект не оказался нежизнеспособным и не был отвергнут. Тщательное планирование проекта в начале гарантирует возможность быстрой и безболезненной модернизации его в будушем. На следующих занятиях рассматриваются средства реализации спланированных проектов. Вопросы тестирования и маркетинга программных продуктов выходят за пределы этой книги, хотя при составлении бизнес-плана их никак нельзя упускать. Вопросы и ответыЧем объектно-ориентированный анализ и проектирование фундаментально отличаются от других подходов? До разработки объектно-ориентированной технологии аналитики и программисты были склонны думать о программах как о группах функций, работающих с данными. Объектно-ориентированное программирование рассматривает интегрированные данные и функции как самостоятельные единицы, содержащие в себе и данные, и методы манипулирования ими. При процедурном программирование внимание сконцентрировано на функциях и их работе с данными. Говорят, что программы на Pascal и С — коллекции процедур, а программы на C++ — коллекции классов. Является ли объектно-ориентированное программирование той палочкой-выручалочкой, которая решит все проблемы программирования? Нет, этого никогда и не ждали. Однако на современном уровне требования к программным продуктам объектно-ориентированные анализ, проектирование и программирование обеспечивают программистов средствами, которые не могло предоставить процедурное программирование. Является ли C++ совершенным объектно-ориентированным языком? C++, если сравнивать его с другими альтернативными объектно-ориентированными языками программирования, имеет множество преимуществ и недостатков. Но одно из безусловных преимуществ состоит в том, что это самый популярный объектно-ориентированный язык программирования на Земле. Откровенно говоря, большинство программистов решают работать на C++ не после изнурительного анализа альтернативных объектно-ориентированных языков. Они идут туда, где происходят основные события, а в 90-х основные события в мире программирования связаны с C++. Тому есть веские причины. Конечно, C++ может многое предложить программисту, но эта книга существует — и бьюсь об заклад, что вы читаете ее, — из-за того, что C++ выбран в качестве языка разработки в очень многих крупных корпорациях, таких как Microsoft. КоллоквиумВ этом разделе предлагаются вопросы для самоконтроля и укрепления полученных знаний, а также ряд упражнений, которые помогут закрепить ваши практические навыки. Попытайтесь самостоятельно ответить на вопросы теста и выполнить задания, а потом сверьте полученные результаты с ответами в приложении Г. Не приступайте к изучению материала следующей главы, если для вас остались неясными хотя бы некоторые из предложенных ниже вопросов. Контрольные вопросы1. Какая разница между объектно-ориентированным и процедурным программированием? 2. Каковы этапы объектно-ориентированного анализа и проектирования? 3. Как связанны диаграммы последовательности и сотрудничества? Упражнения1. Предположим, что есть две пересекающиеся улицы с двусторонним движением, светофорами и пешеходными переходами. Нужно создать виртуальную модель, чтобы определить, позволит ли изменение частоты подачи сигнала светофора сделать дорожное движение более равномерным. 2. Какие объекты и какие классы потребуются для имитации этой ситуации? 3. Усложним ситуацию из упражнения 1. Предположим, что есть три вида водителей: таксисты, переезжающие переход на красный свет; иногородние, которые едут медленно и осторожно; и частники, которые ведут машины по-разному, в зависимости от представлений о своей "крутизне". 4. Также есть два вида пешеходов: местные, которые переходят улицу, где им заблагорассудится, и туристы, которые переходят улицу только на зеленый свет. 5. А кроме того, есть еще велосипедисты, которые ведут себя то как пешеходы, то как водители. 6. Как эти соображения изменят модель? 7. Вам заказали программу планирования времени конференций и встреч, а также бронирования мест в гостинице для визитеров компании и для участников конференций. Определите главные подсистемы. 8. Спроектируйте интерфейсы к классам той части программы, обсуждаемой в упражнении 3, которая относится к резервированию гостиничных номеров. День 19-й. ШаблоныУ программистов, использующих язык C++, появился новый мощный инструмент — "параметризованные типы", или шаблоны. Шаблонами настолько удобно пользоваться, что стандартная библиотека шаблонов (Standard Template Library — STL) бьша принята в состав определений языка C++. Итак, сегодня вы узнаете: • Что такое шаблоны и как их использовать • Как создать класс шаблонов • Как создаются шаблоны функций • Что представляет собой стандартная библиотека шаблонов (STL) и как ею пользоваться Что такое шаблоныПри подведении итогов за вторую неделю обучения вы узнали, как построить объект PartsList и как его использовать для создания объекта PartsCatalog. Если же вы хотите воспользоваться объектом PartsList, чтобы составить, например, список кошек, у вас возникнет проблема: объект PartsList знает только о запчастях. Чтобы решить эту проблему, можно создать базовый класс List и произвести из него классы PartsList и CatsList. Затем можно вырезать и вставить существенную часть класса PartsList в объявление нового класса CatsList. А через неделю, когда вы захотите составить список объектов Car, вам придется опять создавать новый класс и снова "вырезать и вставлять". Очевидно, что это неприемлемое решение. Ведь через какое-то время класс List и его производные классы придется расширять. А работа, которую пришлось бы проделать, чтобы убедиться в том, что все изменения, коснувшиеся базового класса, распространены и на все связанные классы, превратилась бы в настоящий кошмар. Благодаря шаблонам, эта проблема легко решается, а с принятием стандарта ANSI шаблоны стали неотъемлемой частью языка C++, подобно которому они сохраняют тип и очень гибки. Параметризованные типыС помошью шаблонов можно "научить" компилятор составлять список элементов любого типа, а не только заданного: PartsList — это список частей, CatsList — это список кошек. Единственное отличие между ними — тип элементов списка. При использовании шаблонов тип элементов списка становится параметром для определения класса. Обшим компонентом практически всех библиотек C++ является класс массивов. Как показано на примере с классом List, утомительно и крайне неэффективно создавать один класс массивов для целых, другой — для двойных слов, а еще один — для массива элементов типа Animals. Шаблоны позволяют объявить параметризованный класс массивов, а затем указать, какой тип объекта будет содержаться в каждом экземпляре массива. Заметьте, что стандартная библиотека шаблонов предоставляет стандартизированный набор контейнерных классов, включая массивы, списки и т.д. Сейчас мы выясняем, что нужно для создания вашего собственного класса, только для того, чтобы вы до конца поняли, как работают шаблоны; но в коммерческой программе вы почти стопроцентно будете использовать классы библиотеки STL, а не собственного изготовления. Создание экземпляра шаблонаЭкземпляризация (instantiation) — это операция создания определенного типа из шаблона. Отдельные классы называются экземплярами шаблона. Параметризованные шаблоны (parameterized templates) предоставляют возможность создания общего класса и для построения конкретных экземпляров передают этому классу в качестве параметров типы данных. Объявление шаблонаОбъявляем параметризованный объект Array (шаблон для массива) путем записи следующих строк: 1: template <class T> // объявляем шаблон и параметр 2: class Array // параметризуемый класс 3: { 4: public: 5: Array(); 6: // здесь должно быть полное определение класса 7: }; Ключевое слово template используется в начале каждого объявления и определения класса шаблона. Параметры шаблона располагаются за ключевым словом template. Параметры — это элементы, которые изменяются с каждым экземпляром. Например, в приведенном выше шаблоне массивов будет изменяться тип объектов, сохраняемых в массиве. Один экземпляр шаблона может хранить массив целых чисел, а другой — массив объектов класса Animals. В этом примере используется ключевое слово class, за которым следует идентификатор Т. Это ключевое слово означает, что параметром является тип. Идентификатор T используется в остальной части определения шаблона, указывая тем самым на параметризованный тип. В одном экземпляре этого класса вместо идентификатора T повсюду будет стоять тип int, а в другом — тип Cat. Чтобы объявить экземпляры параметризованного класса Array для типов int и Cat, следует написать: Array<int> anIntArray; Array<Cat> aCatArray; Объект anIntArray представляет собой массив целых чисел, а объект aCatArray — массив элементов типа Cat. Теперь вы можете использовать тип Array<int> в любом месте, где обычно указывается какой-либо тип — для возвращаемого функцией значения, для параметра функции и т.д. В листинге 19.1 содержится полное объявление уже рассмотренного нами шаблона Array. Примечание:Программа в листинге 19.1 не завершена! Листинг 19.1. Шаблон класса Array 1: //Листинг 19.1. Шаблон класса массивов 2: #include <iostream.h> 3: const int DefaultSize = 10; 4: 5: template <class T> // объявляем шаблон и параметр 6: class Array // параметризуемый класс 7: { 8: public: 9: // конструкторы 10: Array(int itsSize = DefaultSize); 11: Array(const Array &rhs); 12: ~Array() { delete [] pType; } 13: 14: // операторы 15: Array& operator=(const Array&); 16: T& operator[](int offSet) { return pType[offSet]; } 17: 18: // методы доступа 19: int getSize() { return itsSize; } 20: 21: private: 22: T *pType; 23: int itsSize; 24: }; Результат: Результатов нет. Эта программа не завершена. Анализ: Определение шаблона начинается в строке 5 с ключевого слова template за которым следует параметр. В данном случае параметр идентифицируется как тип за счет использования ключевого слова class, а идентификатор T используется для представления параметризованного типа. Со строки 6 и до конца определения шаблона (строка 24) вся остальная часть объявления аналогична любому другому объявлению класса. Единственное отличие заключается в том, что везде, где обычно должен стоять тип объекта, используется идентификатор T. Например, можно предположить, что operator[] должен возвращать ссылку на объект в массиве, а на самом деле он объявляется для возврата ссылки на идентификатор типа T. Если объявлен экземпляр целочисленного массива, перегруженный оператор присваивания этого класса возвратит ссылку на тип integer. А при объявлении экземпляра массива Animal оператор присваивания возвратит ссылку на объект типа Animal. Использование имени шаблонаВнутри объявления класса слово Array может использоваться без спецификаторов. В другом месте программы этот класс будет упоминаться как Array<T>. Например, если не поместить конструктор внутри объявления класса, то вы должны записать следующее: template <class T> Array<T>::Array(int size): itsSize = size { pType = new T[size]; for (int i = 0; i<size; i++) pType[i] = 0; } Объявление, занимающее первую строку этого фрагмента кода, устанавливает в качестве параметра тип данных (class T). В таком случае в программе на шаблон можно ссылаться как Array<T>, а объявленную функцию-член вызывать строкой Array(int size). Остальная часть функции имеет такой же вид, какой мог быть у любой другой функции. Это обычный и предпочтительный метод создания класса и его функций путем простого объявления до включения в шаблон. Выполнение шаблонаДля выполнения класса шаблона Array необходимо создать конструктор-копировщик, перегрузить оператор присваивания (operator=) и т.д. В листинге 19.2 показана простая консольная программа, предназначенная для выполнения этого шаблона. Примечание:Некоторые более старые компиляторы не поддерживают использование шаблонов. Но шаблоны являются частью стандарта ANSI C++, поэтому компиляторы всех основных производителей поддерживают шаблоны в своих текущих версиях. Если у вас очень старый компилятор, вы не сможете компилировать и выполнять упражнения, приведенные в этой главе. Однако все же стоит прочитать ее до конца, а затем вернуться к этому материалу после модернизации своего компилятора. Листинг 19.2. Использвание шаблона массива 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: // обычный класс Animal для 6: // создания массива животных 7: 8: class Animal 9: { 10: public: 11: Animal(int); 12: Animal(); 13: ~Animal() { } 14: int GetWeight() const { return itsWeight; } 15: void Display() const { cout << itsWeight; } 16: private: 17: int itsWeight; 18: }; 19: 20: Animal::Animal(int weight): 21: itsWeight(weight) 22: { } 23: 24: Animal::Animal(): 25: itsWeight(0) 26: { } 27: 28: 29: template <class T> // обьявляем шаблон и параметр 30: class Array // параметризованный класс 31: { 32: public: 33: // конструкторы 34: Array(int itsSize - DefaultSize); 35: Array(const Array &rhs); 36: ~Array() { delete [] pType; } 37: 38: // операторы 39: Array& operator=(const Array&); 40: T& operator[](int offSet) { return pType[offSet]; } 41: const T& operator[](int offSet) const 42: { return pType[offSet]; } 43: // методы доступа 44: int GetSize() const { return itsSize; } 45: 46: private: 47: T *рТуре; 48: int itsSize; 49: }; 50: 51: // выполнения... 52: 53: // выполняем конструктор 54: template <class T> 55: Array<T>::Array(int size): 56: itsSize(size) 57: { 58: pType = new T[size]; 59: for (int i = 0; i<size; i++) 60: pType[i] = 0; 61: } 62: 63: // конструктор-копировщик 64: template <class T> 65: Array<T>::Array(const Array &rhs) 66: { 67: itsSize = rhs.GetSize(); 68: pType = new T[itsSize]; 69: for (int i = 0; i<itsSize; i++) 70: pType[i] = rhs[i]; 71: } 72: 73: // оператор присваивания 74: template <class T> 75: Array<T>& Array<T>::operator=(const Array &rhs) 76: { 77: if (this == &rhs) 78: return *this; 79: delete [] pType; 80: itsSize = rhs.GetSize(); 81: pType = new T[itsSize]; 82: for (int i = 0; i<itsSize: i++) 83: pType[i] = rhs[i]; 84: return *this; 85: } 86: 87: // исполняемая программа 88: int main() 89: { 90: Array<int> theArray; // массив целых 91: Array<Animal> theZoo; // массив животных 92: Animal *pAnimal; 93: 94: // заполняем массивы 95: for (int i = 0; i < theArray.GetSize(); i++) 96: { 97: theArray[i] = i*2; 98: pAnimal = new Animal(i*3); 99: theZoo[i] = *pAnimal; 100: delete pAnimal; 101: } 102: // выводим на печать содержимое массивов 103: for (int j = 0; j < theArray.GetSize(); j++) 104: { 105: cout << "theArray[" << j << "]:\t"; 106: cout << theArray[j] << "\t\t"; 107: cout << "theZoo[" << j << "]:\t"; 108: theZoo[j].Display(); 109: cout << endl; 110: } 111: 112: return 0; 113: } Результат: theArray[0] 0 theZoo[0] 0 theArray[1] 2 theZoo[1] 3 theArray[2] 4 theZoo[2] - 6 theArray[3] 6 theZoo[3] 9 theArray[4] 8 theZoo[4] 12 theArray[5] 10 theZoo[5] 15 theArray[6] 12 theZoo[6] 18 theArray[7] 14 theZoo[7] 21 theArray[8] 16 theZoo[8] 24 theArray[9] 18 theZoo[9] 27 Анализ: В строках 8-26 выполняется создание класса Animal, благодаря которому объекты определяемого пользователем типа можно будет добавлять в массив. Содержимое строки 29 означает, что в следующих за ней строках объявляется шаблон, параметром для которого является тип, обозначенный идентификатором Т. Класс Array содержит два конструктора, причем первый конструктор принимает размер и по умолчанию устанавливает его равным значению целочисленной константы DefaultSize. Затем объявляются операторы присваивания и индексирования, причем объявляются константная и не константная версии оператора индексирования. В качестве единственного метода доступа служит функция GetSize(), которая возвращает размер массива. Можно, конечно, представить себе и более полный интерфейс. Ведь для любой серьезной программы создания массива представленный здесь вариант будет недостаточным. Как минимум, пришлось бы добавить операторы, предназначенные для удаления элементов, для распаковки и упаковки массива и т.д. Все это предусмотрено классами контейнеров библиотеки STL, но к этому мы вернемся в конце занятия. Раздел закрытых данных содержит переменные-члены размера массива и указатель на массив объектов, реально помещенных в память. Функции шаблонаЕсли вы хотите передать функции объект массива, нужно передавать конкретный экземпляр массива, а не шаблон. Поэтому, если некоторая функция SomeFunction() принимает в качестве параметра целочисленный массив, используйте следующую запись: void SomeFunction(Array<int>&); // правильно А запись void SomeFunction(Array<T>&); // ошибка! неверна, поскольку отсюда не ясно, что представляет собой выражение T&. Запись void SomeFunction(Array &); // ошибка! тоже ошибочна, так как объекта класса Array не существует — есть только шаблон и его экземпляры. Чтобы реализовать более общий подход использования объектов, созданных на основе шаблона, нужно объявить функцию шаблона: template <class T> void MyTemplateFunction(Array<T>&); // верно Здесь MyTemplateFunction() объявлена как функция шаблона, на что указывает первая строка объявления. Заметьте, что функции шаблонов, подобно другим функциям, могут иметь любые имена. Функции шаблонов, помимо объектов, заданных в параметризованной форме, могут также принимать и экземпляры шаблона. Проиллюстрируем это на примере: template <class T> void MyOtherFunction(Array<T>&, Array<int>&); // верно Обратите внимание на то, что эта функция принимает два массива: параметризованный массив и массив целых чисел. Первый может быть массивом любых объектов, а второй — только массивом целых чисел. Шаблоны и друзьяВ шаблонах классов могут быть объявлены три типа друзей: • дружественный класс или функция, не являющиеся шаблоном; • дружественный шаблон класса или функция, входящая в шаблон; • дружественный шаблон класса или шаблонная функция, специализированные по типу данных. Дружественные классы и функции, не являющиеся шаблонамиМожно объявить любой класс или функцию, которые будут дружественны по отношению к вашему классу шаблона. В этом случае каждый экземпляр класса: будет обращаться с другом так, как будто объявление класса-друга было сделано в этом конкретном экземпляре. В листинге 19.3 в определении шаблона класса Array добавлена тривиальная дружественная функция Intrude(), а в управляющей.программе делается вызов этой функции. В качестве друга функция Intrude() получает доступ к закрытым данным класса Array. Но поскольку эта функция не является функцией шаблона, то ее можно вызывать только для массива заданного типа (в нашем примере для массива целых чисел). Листинг 18.3. Функция-друг, не являющаяся шаблоном 1: // Листинг 19.3. Использование в шаблонах функций-друзей определенного типа 2: 3: #include <iostream.h> 4: 5: const int DefaultSize = 10; 6: 7: // обьявляем простой класс Animal, чтобы можно 8: // было создать массив животных 9: 10: class Animal 11: { 12: public: 13: Animal(int); 14: Animal(); 15: ~Animal() { } 16: int GetWeight() const { return itsWeight; } 17: void Display() const { cout << itsWeight; > 18: private: 19: int itsWeight; 20: }; 21: 22: Animal::Animal(intweight): 23: itsWeight(weight) 24: { } 25: 26: Animal::Animal(): 27: itsWeight(0) 28: { } 29: 30: template <class T> // обьявляем шаблон и параметр 31: class Array // параметризованный класс 32: { 33: public: 34: // конструкторы 35: Array(int itsSize = DefaultSize); 36: Array(const Array &rhs); 37: ~Array() { delete [] pType; } 38: 39: // операторы 40: Array& operator=(const Array&); 41; T& operator[](int offSet) { return pType[offSet]; } 42: const T& operator[](int offSet) const 43: { return pType[offSet]; } 44: // методы доступа 45: int GetSize() const { return itsSize; } 46: 47: // функция-друг 48: friend void Intrude(Array<int>); 49 50: private: 51: T *рТуре; 52: int itsSize; 53: }; 54: 55: // Поскольку функция-друг не является шаблоном, ее можно использовать только 56: // с массивами целых чисел! Но она получает доступ к закрытым данным класса. 57: void Intrude(Array<int> theArray) 58: { 59: cout << "\n*** Intrude ***\n"; 60: for (int i = 0; i < theArray.itsSize; i++) 61: cout << "i: " << theArray.pType[i] << endl; 62: cout << "\n" 63: } 64: 65: // Ряд выполнений... 66: 67: // выполнение конструктора 68: template <class T> 69: Array<T>::Array(int size): 70: itsSize(size) 71: { 72: pType = new T[size]; 73: for (int i = 0; i<size; i++) 74: pType[i] = 0; 75: } 76: 77: // конструктор-копировщик 78: template <class T> 79: Array<T>::Array(const Array &rhs) 80: { 81: itsSize = rhs.GetSize(); 82: pType = new T[itsSize]; 83: for (int i = 0; i<itsSize; i++) 84: pType[i] = rhs[i]; 85: } 86: 87: // перегрузка оператора присваивания (=) 88: template <class T> 89: Array<T>& Array<T>::operator=(const Array &rhs) 90: { 91: if (this == &rhs) 92: return *this; 93: delete [] pType; 94: itsSize = rhs.GetSize(); 95: pType = new T[itsSize]; 96: for (int i = 0; i<itsSize; i++) 97: pType[i] = rhs[i]; 98: return *this; 99: } 100: 101: // управляющая программа 102: int main() 103: { 104: Array<int> theArray; // массив целых 105: Array<Animal> theZoo; // массив животных 106: Animal *pAnimal; 107: 108: // заполняем массивы 109: for (int i = 0; i < theArray.GetSize(); i++) 110: { 111: theArray[i] = i*2; 112: pAnimal = new Animal(i*3); 113: theZoo[i] = *pAnimal; 114: } 115: 116: int j; 117: for (j = 0; j < theArray.GetSize(); j++) 118: { 119: cout << "theZoo[" << j << "]:\t"; 120: theZoo[j].Display(); 121: cout << endl; 122: } 123: cout << "Now use the friend function to"; 124: cout << "find the members of Array<int>"; 125: Intrude(theArray); 126: 127: cout << "\n\nDone.\n"; 128: return 0; 129: } Результат: theZoo[0]: 0 theZoo[1]: 3 theZoo[2]: 6 theZoo[3]: 9 theZoo[4]: 12 theZoo[5]: 15 theZoo[6]: 18 theZoo[7]: 21 theZoo[8]: 24 theZoo[9]: 27 Now use the friend function to find the members of Array<int> *** Intrude *** i: 0 i: 2 i: 4 i: 6 i: 8 i: 10 i: 12 i: 14 i: 16 i: 18 Done. Анализ: Объявление шаблона Array было расширено за счет включения дружественной функции Intrude(). Это объявление означает, что каждый экземпляр массива типа int будет считать функцию Intrude() дружественной, а следовательно, она будет иметь доступ к закрытым переменным-членам и функциям-членам экземпляра этого массива. В строке 60 функция lntrude() непосредственно обращается к члену itsSize, а в строке 61 получает прямой доступ к переменной-члену pType. В данном случае без использования функции-друга можно было бы обойтись, поскольку класс Array предоставляет открытые методы доступа к этим данным. Этот листинг служит лишь примером того, как можно объявлять и использовать функции-друзья шаблонов. Дружественный класс или функция как общий шаблонВ класс Array было бы весьма полезно добавить оператор вывода данных. Это можно сделать путем объявления оператора вывода для каждого возможного типа массива, но такой подход свел бы не нет саму идею использования класса Array как шаблона. Поэтому нужно найти другое решение. Попробуем добиться того, чтобы оператор вывода работал независимо от типа экземпляра массива. ostream& operator<< (ostream&, Array<T>&); Чтобы этот оператор работал, нужно так объявить operator<<, чтобы он стал функцией шаблона: template <class T> ostream& operator<< (ostream&, Array<T>&) Теперь operator<< является функцией шаблона и его можно использовать в выполнении класса. В листинге 19.4 показано объявление шаблона Array, дополненное объявлением функции оператора вывода operator<<. Листинг 18.4. Использование оператора вывода 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Animal 6: { 7: public: 8: Animal(int); 9: Animal(); 10: ~Animal() { } 11: int GetWeight() const { return itsWeight; } 12: void Display() const { cout << itsWeight; } 13: private: 14: int itsWeight; 15: }; 16: 17: Animal::Animal(int weight): 18: itsWeight(weight) 19: { } 20: 21: Animal::Animal(): 22: itsWeight(0) 23: { } 24: 25: template <class T> // объявляем шаблон и параметр 26: class Array // параметризованный класс 27: { 28: public: 29: // конструкторы 30: Array(int itsSize = DefaultSize); 31: Array(const Array &rhs); 32: ~Array() { delete [] pType; } 33: 34: // операторы 35: Array& operator=(const Array&); 36: T& operator[](int offSet) { return pType[offSet]; } 37: const T& operator[](int offSet) const 38: { return pType[offSet]; } 39: // методы доступа 40: int GetSize() const { return itsSize; } 41: 42: friend ostream& operator<< (ostream&, Array<T>&); 43: 44: private: 45: T *pType; 46: int itsSize; 47: }; 48: 49: template <class T> 50: ostream& operator<< (ostream& output, Array<T>& theArray) 51: { 52: for (int i = 0; i<theArray.GetSize(); i++) 53: output << "[" << i << "] " << theArray[i] << endl; return output; 54: } 55: 56: // Ряд выполнений... 57: 58: // выполнение конструктора 59: template <class T> 60: Array<T>::Array(int size): 61: itsSize(size) 62: { 63: pType = new T[size]; 64: for (int i = 0; i<size; i++) 65: pType[i] = 0; 66: } 67: 68: // конструктор-копировщик 69: template <class T> 70: Array<T>::Array(const Array &rhs) 71: { 72: itsSize = rhs.GetSize(); 73: pType = new T[itsSize]; 74: for (int i = 0; i<itsSize; i++) 75: pType[i] = rhs[i]; 76: } 77: 78: // перегрузка оператора присваивания (=) 79: template <class T> 80: Array<T>& Array<T>::operator=(const Array &rhs) 81: { 82: if (this == &rhs) 83: return *this; 84: delete [] pType; 85: itsSize = rhs.GetSize(); 86: pType = new T[itsSize]; 87: for (int i = 0; i<itsSize; i++) 88: pType[i] = rhs[i]; 89: return *this; 90: } 91: 92: int main() 93: { 94: bool Stop = false; // признак для цикла 95: int offset, value; 96: Array<int> theArray; 97: 98: while (!Stop) 99: { 100: cout << "Enter an offset (0-9) "; 101: cout << "and a value. (-1 to stop): "; 102: cin >> offset >> value; 103: 104: if (offset < 0) 105: break; 106: 107: if (offset > 9) 108: { 109: cout << "***Please use values between 0 and 9.***\n"; 110: continue; 111: } 112: 113: theArray[offset] = value; 114: } 115: 116: cout << "\nHere's the entire array:\n"; 117: cout << theArray << endl; 118: return 0; 119: } Результат: Enter an offset (0 -9 and а value. (-1 to stop) 1 10 Enter an offset (0 -9 and а value. (-1 to stop) 2 20 Enter an offset (0 -9 and а value. (-1 to stop) 3 30 Enter an offset (0 -9 and а value. (-1 to stop) 4 40 Enter an offset (0 -9 and а value. (-1 to stop) 5 50 Enter an offset (0 -9 and а value. (-1 to stop) 6 60 Enter an offset (0 -9 and а value. (-1 to stop) 7 70 Enter an offset (0 -9 and а value. (-1 to stop) 8 80 Enter an offset (0 -9 and а value. (-1 to stop) 9 90 Enter an offset (0 -9 and а value. (-1 to stop) 1С 10 ***Please use values between 0 and 9.* >>* Enter an offset (0 -9) and а value. (-1 to stop) -1 -1 Here's the entire array: [0] 0 [1] 10 [2] 20 [3] 30 [4] 40 [5] 50 [6] 60 [7] 70 [8] 80 [9] 90 Анализ: В строке 42 объявляется шаблон функции operator<<() в качестве друга шаблона класса Array. Поскольку operator<<() реализован в виде функции шаблона, то каждый экземпляр этого типа параметризованного массива будет автоматически иметь функцию operator<<() для вывода данных соответствующего типа. Выполнение этого оператора начинается в строке 49. Каждый член массива вызывается по очереди. Этот метод работает только в том случае, если функция operator<<() определена для каждого типа объекта, сохраняемого в массиве. Использование экземпляров шаблонаС экземплярами шаблона можно обращаться так же, как с любыми другими типами данных. Их можно передавать в функции как ссылки или как значения и возвращать как результат выполнения функции (тоже как ссылки или как значения). Способы передачи экземпляров шаблона показаны в листинге 19.5. Листинг 19.5. Передача в функцию экземпляра шаблона 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: // Обычный класс, из объектов которого будет состоять массив 6: class Animal 7: { 8: public: 9: // конструкторы 10: Animal(int); 11: Animal(); 12: ~Animal(); 13: 14: // методы доступа 15: int GetWeight() const { return itsWeight; } 16: void SetWeight(int theWeight) { itsWeight = theWeight; } 17: 18: // дружественные операторы 19: friend ostream& operator<< (ostream&, const Animal&); 20: 21: private: 22: int itsWeight; 23: }; 24: 25: // оператор вывода объектов типа Animal 26: ostream& operator<< 27: (ostream& theStream, const Animal& theAnimal) 28: { 29: theStream << theAnimal.GetWeight(); 30: return theStream; 31: } 32: 33: Animal::Animal(int weight): 34: itsWeight(weight) 35: { 36: // cout << "Animal(int)\n"; 37: } 38: 39: Animal::Animal(): 40: itsWeight(0) 41: { 42: // cout << "Animal()\n"; 43: } 44: 45: Animal::~Animal() 46: { 47: // cout << "Destroyed an animal...\n"; 48: } 49: 50: template <class T> // объявление шаблона и параметра 51: class Array // параметризованный класс 52: { 53: public: 54: Array(int itsSlze = DefaultSize); 55: Array(const Array &rhs); 56: ~Array() { delete [] pType; } 57: 56: Array& operator=(const Array&); 59: T& operator[](int offSet) { return pType[offSet]; } 60: const T& operator[](int offSet) const 61: { return pType[offSet]; } 62: int GetSize() const { return itsSize; } 63: 64: // функция-друг 65: friend ostream& operator<< (ostream&, const Array<T>&); 66: 67: private: 68: T *рТуре; 69: int itsSize; 70: }; 71: 70: template <class T> 72: ostream& operator<< (ostream& output, const Array<T>& theArray) 73: { 74: for (int i = 0; i<theArray.GetSize(); i++) 75: output << "[" << i << "] " << theArray[i] << endl; 76: return output; 77: } 78: 79: // Ряд выполнений... 80: 81: // выполнение конструктора 82: template <class T> 83: Array<T>::Array(int size): 84: itsSize(size) 85: { 86: рТуре = new T[size]; 67: for (int i = 0; i<size; i++) 88: pType[i] = 0; 89: } 90: 91: // конструктор-копировщик 92: template <class T> 93: Array<T>::Array(const Array &rhs) 94: { 95: itsSize = rhs.GetSize(); 96: рТуре = new T[itsSize]; 97: for (int i = 0; i<itsSize; i++) 98: pType[i] = rhs[i]; 99: } 100: 101: void IntFillFunction(Array<int>& theArray); 102: void AnimalFillFunction(Array<Animal>& theArray); 103: 104: int main() 105: { 106: Array<int> intArray; 107: Array<Animal> animalArray; 108: IntFillFunction(intArray); 109: AnimalFillFunction(animalArray); 110: cout << "intArray...\n" << intArray; 111: cout << "\nanimalArray...\n" << aninalArray << endl; 112: return 0; 113: } 114: 115: void IntFillFunction(Array<int>& theArray) 116: { 117: bool Stop = false; 118: int offset, value; 119: while (!Stop) 120: { 121: cout << "Enter an offset (0-9) "; 122: cout << "and a value, (-1 to stop): " ; 123: cin >> offset >> value; 124: if (offset < 0) 125: break; 126: if (offset > 9) 127: { 128: cout << "***Please use values between 0 and 9.***\n"; 129: continue; 130: } 131: theArray[offset] = value; 132: } 133: } 134: 135: 136: void AnimalFillFunction(Array<Animal>& theArray) 137: { 138: Animal * pAnimal; 139: for (int i = 0; i<theArray,GetSize(); i++) 140: { 141: pAnimal = new Animal; 142: pAnimal->SetWeight(i*100); 143: theArray[i] = *pAnimal; 144: delete pAnimal; // копия была помещена в массив 145: } 146: } Результат: Enter an offset (0- 9) and а value. ( -1 to stop) 1 10 Enter an offset (0- 9) and а value. ( -1 to stop) 2 20 Enter an offset (0- 9) and а value. ( -1 to stop) 3 30 Enter an offset (0- 9) and а value. ( -1 to stop) 4 40 Enter an offset (0- 9) and а value. ( -1 to stop) 5 50 Enter an offset (0- 9) and а value. ( -1 to stop) 6 60 Enter an offset (0- 9) and а value. ( -1 to stop) 7 70 Enter an offset (0- 9) and а value. ( -1 to stop) 8 80 Enter an offset (0- 9) and а value. ( -1 to stop) 9 90 Enter an offset (0-9) and а value. ( -1 to stop) 10 10 ***Please use values between 0 and 9.*** Enter an offset (0-9) and a value. (-1 to stop): -1 -1 intArray:... [0] 0 [1] 10 [2] 20 [3] 30 [4] 40 [5] 50 [6] 60 [7] 70 [8] 80 [9] 90 animalArray:... [0] 0 [1] 100 [2] 200 [3] 300 [4] 400 [5] 500 [6] 600 [7] 700 [8] 800 [9] 900 Анализ: В целях экономии места большая часть выполнения класса Array не показана в этом листинге. Класс Animal объявляется в строках 6—23. И хотя структура этого класса предельно упрощена, тем не менее в нем содержится собственный оператор вывода (<<), позволяющий выводить на экран объекты массива типа Animal. Обратите внимание, что в классе Animal объявлен конструктор по умолчанию (конструктор без параметров, который еще называют стандартный). Без этого объявления нельзя обойтись, поскольку при добавлении объекта в массив используется конструктор по умолчанию данного объекта. При этом возникают определенные трудности, о которых речь пойдет ниже. В строке 101 объявляется функция IntFillFunction(), параметром которой является целочисленный массив. Обратите внимание, что эта функция не принадлежит шаблону, поэтому может принять только массив целочисленных значений. Аналогичным образом в строке 102 объявляется функция AnimalFillFunction(), которая принимает массив объектов типа Animal. Эти функции выполняются по-разному, поскольку заполнение массива целых чисел отличается от заполнения массива объектов Animal. Специализированные функцииЕсли разблокировать выражения вывода на экран в конструкторах и деструкторе класса Animal (см. листинг 19.5), то обнаружится, что конструктор и деструктор объектов Animal вызываются значительно чаще, чем ожидалось. При добавлении объекта в массив вызывается стандартный конструктор объекта. Однако конструктор класса Array также используется для присвоения нулевых значений каждому члену массива, как показано в строках 59 и 60 листинга 19.2. В выражении someAnimal = (Animal) 0; вызывается стандартный оператор operator= для класса Animal. Это приводит к созданию временного объекта Animal с помощью конструктора, который принимает целое число (нуль). Этот временный объект выступает правым операндом в операции присваивания, после чего удаляется деструктором. Такой подход крайне неэффективен, поскольку объект Animal уже инициализирован должным образом. Однако эту строку нельзя удалить, потому что при создании массива целочисленные значения не будут автоматически инициализироваться нулевыми значениями. Выход состоит в том, чтобы объявить в шаблоне дополнительный специализированный конструктор для создания массива объектов Animal. Эта идея реализована в листинге 19.6 путем явного выполнения класса Animal. Листинг 19.6. Специальные реализации шаблона 1: #include <iostream.h> 2: 3: const int DefaultSize = 3; 4: 5: // Обычный класс, из объектов которого создается массив 6: class Animal 7: { 8: public: 9: // конструкторы 10: Animal(int); 11: Animal(); 12: ~Animal(); 13: 14: // методы доступа 15: int GetWeight() const { return itsWeight; } 16: void SetWeight(int theWeight) { itsWeight = theWeight; } 17: 18: // дружественные операторы 19: friend ostream& operator<< (ostream&, const Animal&); 20: 21: private: 22: int itsWeight; 23: }; 24: 25: // оператор вывода обьектов типа Animal 26: ostream& operator<< 27: (ostream& theStream, const Animal& theAnimal) 28: { 29: theStream << theAnimal.GetWeight(); 30: return theStream; 31: } 32: 33: Animal::Animal(int weight): 34: itsWeight(weight) 35: { 36: cout << "animal(int) "; 37: } 38: 39: Animal::Animal(): 40: itsWeight(0) 41: { 42: cout << "animal() "; 43: } 44: 45: Animal::~Animal() 46: { 47: cout << "Destroyed an animal..."; 48: } 49: 50: template <class T> // обьявляем шаблон и параметр 51: class Array // параметризованный класс 52: { 53: public: 54: Array(int itsSize = DefaultSize); 55: Array(const Array &rhs); 56: ~Array() { delete [] pType; } 57: 58: // операторы 59: Array& operator=(const Array&); 60: T& operator[](int offSet) { return pType[offSet]; } 61: const T& operator[](int offSet) const 62: { return pType[offSet]; } 62: 63: // методы доступа 64: int GetSize() const { return itsSize; } 65: 66: // функция-друг 67: friend ostream& operator<< (ostream&, const Array<T>&); 68: 69: private: 70: T *pType; 71: int itsSize; 72: }; 73: 74: template <class T> 75: Array<T>::Array(int size = DefaultSize): 76: itsSize(size) 77: { 78: pType = new T[size]; 79: for (int i = 0; i<size; i++) 80: pType[i] = (T)0; 81: } 82: 83: template <class T> 84: Array<T>& Array<T>::operator=(const Array &rhs) 85: { 86: if (this == &rhs) 87: return *this; 88: delete [] pType; 89: itsSize = rhs.GetSize(); 90: pType = new T[itsSize]; 91: for (int i = 0; i<itsSize; i++) 92: pType[i] = rhs[i]; 93: return *this; 94: } 95: template <class T> 96: Array<T>::Array(const Array &rhs) 97: { 98: itsSize = rhs.GetSize(); 99: pType = new T[itsSize]; 100: for (int i = 0; i<itsSize; i++) 101: pType[i] = rhs[i]; 102: } 103: 104: 105: template <olass T> 106: ostream& operator<< (ostream& output, const Array<T>& theArray) 107: { 108: for (int i = 0; i<theArray.GetSize(); i++) 109; output << "[" << i << "] " << theArray[i] << endl; 110: return output; 111: } 112: 113: 114: Array<Animal>::Array(int AnimalArraySize): 115: itsSize(AnimalArraySize) 116: { 117: pType = new Animal[AnimalArraySize]; 118: } 119: 120: 121: void IntFillFunction(Array<int>& theArray); 122: void AnimalFillFunction(Array<Animal>& theArray); 123: 124: int main() 125: { 126: Array<int> intArray; 127: Array<Animal> animalArray; 128: IntFillFunction(intArray); 129: AnimalFillFunction(animalArray); 130: cout << "intArray...\n" << intArray; 131: cout << "\nanimaiArray...\n" << animalArray << endl; 132: return 0; 133: } 134: 135: void IntFillFunction(Array<int>& theArray) 136: { 137: bool Stop = false; 138: int offset, value; 139: while (!Stop) 140: { 141: cout << "Enter an offset (0-9) and a value, "; 142: cout << "(-1 to stop): "; 143: cin >> offset >> value; 144: if (offset < 0) 145: break; 146: if (offset > 9) 147: { 148: cout << "***Please use values between 0 and 9.***\n"; 149: continue; 150: } 151: theArray[offset] = value; 152: } 153: } 154: 155: 156: void AnimalFillFunction(Array<Animal>& theArr, 157: { 158: Animal * pAnimal; 159: for (int i = 0; i<theArray.GetSize(); i++) 160: { 161: pAnimal = new Animal(i*10); 162: theArray[i] = *pAnimal; 163: delete pAnimal; 164: } 165: } Примечание:Для облегчения анализа в приведенные ниже результаты работы программы добавлены номера строк, но в действительности они не выводятся. Результат: 1: animal() animal() animal() Enter an offset (0-9) and a value. (-1 to stop): 0 0 2: Enter an offset (0-9) and a value. (-1 to stop): 1 1 3: Enter an offset (0-9) and a value. (-1 to stop): 2 2 4: Enter an offset (0-9) and a value. (-1 to stop): 3 3 5: Enter an offset (0-9) and a value. (-1 to stop): -1 -1 6: animal(int) Destroyed an animal...animal(int) Destroyed an animal...animal(int) Destroyed an animal...initArray... 7: [0] 0 8: [1] 1 9: [2] 2 10: 11: animal array 12: [0] 0 13: [1] 10 14: [2] 20 15: 16: Destroyed an animal...Destroyed an animal...Destroyed an animal 17: <<< Second run >>> 18: animal(int) Destroyed an animal.. 19: animal(int) Destroyed an animal.. 20: animal(int) Destroyed an animal.. 21: Enter an offset (0-9) and a value. (-1 to stop): 0 0 22: Enter an offset (0-9) and a value. (-1 to stop): 1 1 23: Enter an offset (0-9) and a value. (-1 to stop): 2 2 24: Enter an offset (0-9) and a value. (-1 to stop): 3 3 25: animal(int) 26: Destroyed an animal... 27: animal(int) 28: Destroyed an animal... 29: animal(int) 30: Destroyed an animal... 31: initArray. . . 32: [0] 0 33: [1] 1 34: [2] 2 35: 36: animal array 37: [0] 0 38: [1] 10 39: [2] 20 40: 41: Destroyed an animal... 42: Destroyed an animal... 43: Destroyed an animal... Анализ: В листинге 19.6 оба класса воспроизведены во всей своей полноте, чтобы лучше наблюдать за созданием и удалением временных объектов Animal. Для упрощения результатов работы значение DefaultSize было уменьшено до 3. Все конструкторы и деструкторы класса Animal (строки 33—48) выводят на экран сообщения, сигнализирующие об их вызове. В строках 74-81 объявляется конструктор класса Array. В строках 114-118 показан специализированный конструктор Array для массива объектов типа Animal. Обратите внимание, что в этом специализированном конструкторе не делается никаких явных присвоений и исходные значения для каждого объекта Animal устанавливаются стандартным конструктором. При первом выполнении этой программы на экран выводится ряд сообщений. В строке 1 результатов выполнения программы зафиксированы сообщения трех стандартных конструкторов, вызванных при создании массива. Затем пользователь вводит четыре числа, которые помещаются в массив целых чисел. После этого управление передается функции AnimalFillFunction(). Здесь в области динамического обмена создается временный объект Animal (строка 161), а его значение используется для модификации объекта Animal в массиве (строка 162). В следующей же строке (с номером 163) временный объект Animal удаляется. Этот процесс повторяется для каждого члена массива и отражен в строке 6 результатов выполнения программы. В конце программы созданные массивы удаляются, а при вызове их деструкторов также удаляются и все их объекты. Процесс удаления отражен в строке 16 результатов выполнения программы. При следующем выполнении программы (результаты показаны в строках 18-43) были закомментированы несколько строк программного кода (со 114 по 118), содержащие специализированный конструктор класса Array. В результате при выполнении программы для создания массива объектов Animal вызывается конструктор шаблона, показанныйвстроках74-81. Это приводит к созданию временных объектов Animal для каждого члена массива (строки программы 79 и 80), что отражается в строках 18-20 результатов выполнения программы. Во всех остальных аспектах, результаты выполнения двух вариантов программы, как и следовало ожидать, идентичны. Статические члены и шаблоныВ шаблоне можно объявлять статические переменные-члены. В результате каждый экземпляр шаблона будет иметь собственный набор статических данных. Например, если добавить статическую переменную-член в шаблон Array (например, для подсчета количества созданных массивов), то в рассмотренной выше программе будут созданы две статические переменные-члена: одна для подсчета массивов объектов типа Animal и другая для массивов целых чисел. Добавление статической переменной-члена и статической функции в шаблон Array показано в листинге 19.7. Листинг 19.7. Использование статических переменных-членов и функций-членов с шаблонам 1: #include <iostream.h> 2: 3: const int DefaultSize = 3; 4: 5: // Обычный класс, из объектов которого создается массив 6: class Animal 7: { 8: public: 9: // конструкторы 10: Animal(int); 11: Animal(); 12: ~Animal(); 13: 14: // методы доступа 15: int GetWeight() const { return itsWeight: } 16: void SetWeight(int theWeight) { itsWeight = theWeight } 17: 18: // дружественные операторы 19: friend ostream& operator<< (ostream&, const Animal&); 20: 21: private: 22: int itsWeight; 23: }; 24: 25: // оператор вывода обьектов типа Anlmal 26: ostream& operator<< 27: (ostream& theStream, const Animal& theAnimal) 28: { 29: theStream << theAnimal.GetWeight(); 30: return theStream; 31: } 32: 33: Animal::Animal(int weight): 34: itsWeight(weight) 35: { 36: //cout << "animal(int) "; 37: } 38: 39: Animal::Animal(): 40: itsWeight(0) 41: { 42: // cout << "animal() "; 43: } 44: 45: Animal::~Animal() 46: { 47: // cout << "Destroyed an animal..."; 48: } 49: 50: template <class T> // объявляем шаблон и параметр 51: class Array // параметризованный класс 52: { 53: public: 54: // конструкторы 55: Array(int itsSize = DefaultSize); 56: Array(const Array &rhs); 57: ~Array() { delete [] рТуре; itsNumberArrays-; } 58: 59: // операторы 60: Array& operator=(const Array&); 61: T& operator[](int offSet) { return pType[offSet]; } 62: const T& operator[](int offSet) const 63: { return pType[offSet]; } 64: // аксессоры 65: int GetSize() const { return itsSize; } 66: static int GetNumberArrays() { return itsNumberArrays; } 67: 68: // функция-друг 69: friend ostream& operator<< (ostream&, const Array<T>&); 70: 71: private: 72: T *pType; 73: int itsSize; 74: static int itsNumberArrays; 75: }; 76: 77: template <class T> 78: int Array<T>::itsNumberArrays = 0; 79: 80: template <class T> 81: Array<T>::Array(int size = DefaultSize): 82: itsSize(size) 83: { 84: pType = new T[size]; 85: for (int i = 0; i<size; i++) 86: pType[i] = (T)0; 87: itsNumberArrays++; 88: } 89: 90: template <class T> 91: Array<T>& Array<T>::operator=(const Array &rhs) 92: { 93: if (this == &rhs) 94: return *this; 95: delete [] pType; 96: itsSize = rhs.GetSize(); 97: pType = new T[itsSize]; 98: for (int i = 0; i<itsSize; i++) 99: pType[i] = rhs[i]; 100: } 101: 102: template <class T> 103: Array<T>::Array(const Array &rhs) 104: { 105: itsSize = rhs.GetSize(); 106: pType = new T[itsSize]; 107: for (int i = 0; i<itsSize; i++) 108: pType[i] = rhs[i]; 109: itsNumberArrays++; 110: } 111: 112: 113: template <class T> 114: ostream& operator<< (ostream& output, const Array<T>& theArray) 115: { 116: for (int i = 0: i<theArray.GetSize(); i++) 117: output'<< "[" << i << "] " << theArray[i] << endl; 118: return output; 119: } 120: 121: 122: 123: int main() 124: { 125: 126: cout << Array<int>::GetNumberArrays() << " integer arrays\n"; 127: cout << Array<Animal>::GetNumberArrays(); 128: cout << " animal arrays\n\n"; 129: Array<int> intArray; 130: Array<Animal> animalArray; 131: 132: cout << intArray.GetNumberArrays() << " integer arrays\n"; 133: cout << animalArray.GetNumberArrays(); 134: cout << " animal arrays\n\n"; 135: 136: Array<int> *pIntArray = new Array<int>; 137: 138: cout << Array<int>::GetNumberArrays() << " integer arrays\n"; 139: cout << Array<Animal>::GetNumberArrays(); 140: cout << " animal arrays\n\n"; 141: 142: delete pIntArray; 143: 144: cout << Array<int>::GetNumberArrays() << " integer arrays\n"; 145: cout << Array<Animal>::GetNumberArrays(); 146: cout << " animal arrays\n\n"; 147: return 0; 148: } Результат: 0 integer arrays 0 animal arrays 1 integer arrays 1 animal arrays 2 integer arrays 1 animal arrays 1 integer arrays 1 animal arrays Анализ: Для экономии места в листинге опущено объявление класса Animal. В класс Array добавлена статическая переменная itsNumberArrays (в строке 74), а поскольку эта перемененная объявляется в разделе закрытых членов, в строке 66 добавлен открытый статический метод доступа GetNumberArrays(). Инициализация статической переменной-члена выполняется явно в строках 77 и 78. Конструкторы и деструктор класса Array изменены таким образом, чтобы могли отслеживать число массивов, существующих в любой момент времени. Доступ к статической переменной, заданной в шаблоне, можно получить так же, как и при работе со статическими переменными-членами обычного класса: с помощью метода доступа, вызванного для объекта класса, как показано в строках 132 и 133, или явным обращением к переменной класса, как показано в строках 126 и 127. Обратите внимание, что при обращении к статической переменной-члену необходимо указать тип массива, так как для каждого типа будет создана своя статическая переменная-член. Рекомендуется:Используйте статические члены в шаблонах. Специализируйте выполнение шаблона путем замещения функций шаблона для разных типов. Указывайте параметр типа при вызове статических функций шаблона, чтобы получить доступ к функции требуемого типа. Стандартная библиотека шаблоновОтличительной чертой новой версии языка C++ является принятие стандартной библиотеки шаблонов (Standard Template Library — STL). Все основные разработчики компиляторов теперь предлагают библиотеку STL как составную часть своих программных продуктов. STL — это библиотека классов контейнеров, базирующихся на шаблонах. Она включает векторы, списки, очереди и стеки, а также ряд таких общих алгоритмов, как сортировка и поиск. Цель включения библиотеки STL состоит в том, чтобы избавить вас от очередного изобретения колеса и при разработке выполнить за вас рутинные общепринятые процессы. Библиотека STL оттестирована и отлажена, отличается высокой эффективностью и не требует дополнительных затрат. Важнее всего то, что библиотеку STL можно использовать многократно для разработки собственных приложений. Необходимо только один раз разобраться в принципах использования библиотеки STL и классов- контейнеров. КонтейнерыКонтейнер — это объект, который содержит другие объекты. Стандартная библиотека C++ предоставляет ряд классов-контейнеров, являющихся мощными инструментальными средствами, которые помогают разработчикам C++ решать наиболее общие задачи программирования. Среди классов контейнеров стандартной библиотеки шаблонов (STL) различаются два типа: последовательные и ассоциативные. Последовательные контейнеры предназначены для обеспечения последовательного или произвольного доступа к своим членам, или элементам. Ассоциативные контейнеры оптимизированы таким образом, чтобы получать доступ к своим элементам по ключевым значениям. Подобно другим компонентам стандартной библиотеки C++, библиотека STL совместима с различными операционными системами. Все классы-контейнеры библиотеки STL определены в пространстве имен std. Последовательные контейнерыТакие контейнеры стандартной библиотеки шаблонов обеспечивают эффективный последовательный доступ к списку объектов. Стандартная библиотека C++ предоставляет три вида последовательных контейнеров: векторы, списки и двухсторонние очереди. ВекторМассивы часто используются для хранения ряда элементов и обеспечивают возможность прямого доступа к ним. Элементы в массиве имеют один и тот же тип, а обратиться к ним можно с помощью индекса. Библиотека STL обеспечивает класс- контейнер vector, который ведет себя подобно массиву, но его использование отличается большей мощностью и безопасностью по сравнению со стандартным массивом C++. Вектор — это контейнер, оптимизированный таким образом, чтобы обеспечить быстрый доступ к его элементам по индексу. Класс-контейнер vector определен в файле заголовка <vector> в пространстве имен std (подробнее об использовании пространств имен см. главу 17). Вектор можно наращивать по мере необходимости. Предположим, был создан вектор для 10 элементов. После того как в вектор поместили 10 объектов, он оказался целиком заполненным. Если затем к вектору добавить еще один объект, он автоматически увеличит свою вместимость так, что сможет разместить одиннадцатый объект. Вот как выглядит определение класса vector: template <class T, class А = allocator<T>> class vector { // члены класса }; Первый аргумент (class T) означает тип элементов в векторе. Второй аргумент (class А) — это класс распределения, который берет на себя функции диспетчера памяти, ответственного за распределение и освобождение памяти для элементов контейнеров. Принципы построения и выполнения классов распределения затрагивают более сложные темы, которые выходят за рамки этой книги. По умолчанию элементы создаются с помощью оператора new() и освобождаются с помощью оператора delete(), т.е. для создания нового элемента вызывается стандартный конструктор класса Т. Это служит еще одним аргументом в пользу явного определения стандартного конструктора для ваших собственных классов. Если этого не сделать, то нельзя будет использовать стандартный векторный контейнер для хранения объектов пользовательского класса. Определить векторы для содержания целых и вещественных чисел можно следующим образом: vector<int> vInts; // вектор для хранения целых элементов vector<float> vFloats; // вектор для хранения вещественных элементов Обычно пользователь имеет представление о том, сколько элементов будет содержаться в векторе. Предположим, на курс прикладной математики в институте набирается не более 50 студентов. Прежде чем создавать вектор для массива студентов, следует побеспокоиться о том, чтобы он был достаточно большим и мог содержать 50 элементов. Стандартный класс vector предоставляет конструктор, который принимает число элементов в качестве параметра. Так что можно определить вектор для 50 студентов следующим образом: vector<Student> MathClass(50); Компилятор автоматически выделит достаточный объем памяти для хранения записей о 50 студентах. Каждый элемент вектора создается с использованием стандартного конструктора Student::Student(). Количество элементов в векторе можно узнать с помощью функции-члена size(). В данном примере функция-член vStudent.size() возвратит значение 50. Другая функция-член, capacity(), сообщает, сколько в точности элементов может принять вектор, прежде чем потребуется увеличение его размера. Но об этом речь впереди. Вектор называется пустым, если он не содержит ни одного элемента, т.е. если его размер равен нулю. Чтобы определить, не является ли вектор пустым, в классе вектора предусмотрена функция-член empty(), которая принимает значение, равное истине, если вектор пустой. Чтобы записать студента Гарри на курс прикладной математики, т.е. (говоря языком программирования) чтобы назначить объект Harry класса Student вектору MathClass, можно использовать оператор индексирования ([]): MathClass[5] = Harry; Индексы начинаются с нуля. Для назначения объекта Harry шестым элементом вектора MathClass здесь используется перегруженный оператор присваивания класса Student. Аналогично, чтобы определить возраст объекта Harry, можно получить доступ к соответствующей записи, используя следующее выражение: MathClass[5].GetAge(); Как упоминалось выше, при добавлении в вектор большего числа элементов, чем было указано при создании вектора, дополнительное место для нового элемента будет добавлено автоматически. Предположим, курс прикладной математики стал таким популярным, что количество принятых студентов превысило число 50. Возможно, за 51- го студента кто-то замолвил словечко, и декану не осталось ничего другого, как увеличить число студентов на курсе. Так вот, если на курс (в вектор MathClass) захочет записаться 51-я студентка Салли (объект Sally), компилятор спокойно расширит пределы вектора, чтобы "впустить" новое молодое дарование. Добавлять элемент в вектор можно различными способами. Один из них — с помощью функции-члена push_back(): MathClass.push_back(Sally); Эта функция-член добавляет новый объект Sally класса Student в конец вектора MathClass. И теперь в векторе MathClass содержится уже 51 элемент, причем к объекту Sally можно обратиться по индексу MathClass[50]. Чтобы функция push_back() была работоспособной, в классе Student нужно определить конструктор-копировщик. В противном случае эта функция не сможет создать копию объекта Sally. В векторе из библиотеки STL не задается максимальное число элементов, так как это решение лучше переложить на плечи создателей компиляторов. Векторный класс предоставляет функцию-член max_size(), которая способна сообщить это магическое число, определенное в вашем компиляторе. В листинге 19.8 демонстрируется использование векторного класса. Вы увидите, что для упрощения обработки строк в этом листинге используется стандартный класс string. Для получения более подробной информации о классе string обратитесь к документации, прилагаемой к вашему компилятору. Листинг 13.8. Создание вектора и обеспечение доступа к его элементам 1: #include <iostream> 2: #include <string> 3: #include <vector> 4: using namespace std; 5: 6: class Student 7: { 8: public: 9: Student(); 10: Student(const string& name, const int аде); 11: Student(const Student& rhs); 12: ~Student(); 13: 14: void SetName(const string& name); 15: string GetName() const; 16: void SetAge(const int age); 17: int GetAge() const; 18: 19: Student& operator=(const Student& rhs); 20: 21: private: 22: string itsName; 23: int itsAge; 24: }; 25: 26: Student::Student() 27: : itsName("New Student"), itsAge(16) 28: { } 29: 30: Student::Student(const string& name, const int agе) 31: : itsName(name), itsAge(age) 32: { } 33: 34: Student::Student(const Student& rhs) 35: : itsName(rhs.GetName()), itsAge(rhs.GetAge()) 36: { } 37: 38: Student::~Student() 39: { } 40: 41: void Student::SetName(const string& name) 42: { 43: itsName = name; 44: } 45: 46: string Student::GetName() const 47: { 48: return itsName; 49: } 50: 51: void Student::SetAge(const int age) 52: { 53: itsAge = age; 54: } 55: 56: int Studsnt::GitAge() const 57: { 58: return itsAge; 59: } 60: 61: Student& Student::operator=(const Student& rhs) 62: { 63: itsName = rhs,GetName(); 64: itsAge = rhs.GetAge(); 65: return *this; 66: } 67: 68: stream& operator<<(ostream& os, const Student& rhs) 69: { 70: os << rhs.GetName() << " is " << rhs.GetAge() << " years old"; 71: return os; 72: } 73: 74: template<class T> 75: void ShowVector(const vector<T>& v); // Отображает свойства вектора 76: 77: typedef vector<Student> SchoolClass; 78: 79: int main() 80: { 81: Student Harry; 82: Student Sally("Sally", 15); 83: Student Bill("Bill", 17); 84: Student Peter("Peter", 16); 85: 86: SchoolClass EmptyClass; 87: cout << "EmptyClass:\n"; 88: ShowVector(EmptyClass); 89: 90: SchoolClass GrowingClass(3); 91: cout << "GrowingClass(3):\n"; 92: ShowVector(GrowingClass); 93: 94: GrowingClass[0] = Harry; 95: GrowingClass[1] = Sally; 96: GrowingClass[2] = Bill; 97: cout << "GrowingClass(3) after assigning students:\n"; 98: ShowVector(GrowingClass); 99: 100: GrowingClass.push_back(Peter); 101: cout << "GrowingClass() after added 4th student:\n"; 102: ShowVector(GrowingClass); 103: 104: GrowingClass[0].SetName("Harry"); 105: GrowingClass[0].SetAge(18); 106: cout << "GrowingClass() after Set\n:"; 107: ShowVector(GrowingClass); 108: 109: return 0; 110: } 111: 112: // 113: // Отображает свойства вектора 114: // 115: template<class T> 116: void ShowVector(const vector<T>& v) 117: { 118: cout << "max_size() = " << v,max_size(); 119: cout << "\tsize() = " << v,size(); 120: cout << "\tcapaeity() = " << v,capacity(); 121: cout << "\t" << (v.empty()? "empty": "not empty"); 122: cout << "\n"; 123: 124: for (int i = 0; i < v.size(); ++i) 125: cout << v[i] << "\n"; 126: 127: cout << endl; 128: } 129: Результат: EmptyClass: max_size() = 214748364 size() capacity() = 0 empty GrowingClass(3): max_size() = 214748364 size() capacity() = 3 not empty New Student is 16 years old New Student is 16 years old New Student is 16 years old GrowingClass(3) after assigning students: max_size() = 214748364 size() = 3 capacity() = 3 not empty New Student is 16 years old Sally is 15 years old Bill is 17 years old GrowingClass() after added 4th student: max_size() = 214748364 size() = 4 capacity() = 6 not empty New Student is 16 years old Sally is 15 years old Bill is 17 years old Peter is 16 years old GrowingClass() after Set: max_size() = 214748364 size() = 4 capacity() = 6 not empty Harry is 18 years old Sally is 15 years old Bill is 17 years old Peter is 16 years old Анализ: Определение класса Student занимает строки 6—24, а выполнение его функций-членов показано в строках 26—66. Структура этого класса проста и дружественна по отношению к классу vector. По рассмотренным ранее причинам были определены стандартный конструктор, конструктор-копировщик и перегруженный оператор присваивания. Обратите внимание, что переменная-член itsName определена как экземпляр базового строкового класса C++ string. Как видите, со строками в C++ намного проще работать, подобное было в языке С (с типом char>>). Функция шаблона ShowVector() объявлена в строках 74—75 и определена в строках 115-128. Она используется для вызова функций-членов вектора, отображающих его свойства: max_size(), size(), capacity() и empty(). Насколько можно судить по результатам работы этой программы, максимальное число объектов класса Student, которое может принять этот вектор, в Visual C++ составляет 214 748 364. Для других типов элементов это число может быть другим. Например, вектор целых чисел может вместить до 1 073 741 823 элементов. Если же вы используете другие компиляторы, то максимальное число элементов у вас может отличаться от приведенных здесь значений. В строках 124 и 125 выполняется цикл, опрашивающий все элементы вектора и отображающий их значения, используя оператор вывода (<<), который перегружен в строках 68—72. В строках 81—84 создаются четыре объекта класса Student. В строке 86 с помощью стандартного конструктора векторного класса определяется пустой вектор с именем EmptyClass. Когда вектор создается таким способом, то компилятор для него совсем не выделяет места в памяти. Как видно по результатам работы функции ShowVector(EmptyClass), как размер, так и вместимость этого вектора равны нулю. Строка 90 содержит определение вектора для включения трех объектов класса Student. Размер и вместимость этого вектора, как и ожидалось, равны трем. В строках 94—96 с помощью оператора индексирования ([]) элементы вектора GrowingClass заполняются объектами класса Student. В строке 100 к вектору добавляется четвертый студент (Peter). Это увеличивает размер вектора до четырех элементов. Интересно, что его вместимость теперь установлена равной шести. Это означает, что компилятор автоматически выделил достаточно пространства, которого хватит даже для шести объектов класса Student. Поскольку векторам должен быть выделен непрерывный блок памяти, для их расширения требуется выполнить целый ряд операций. Сначала выделяется новый блок памяти, достаточно большой для всех четырех объектов класса Student. Затем в только что выделенную память копируются эти три элемента, а четвертый добавляется после третьего элемента. И наконец, исходный блок памяти возвращается в область динамического обмена. При большом количестве элементов в векторе процесс перераспределения и освобождения памяти может оказаться весьма длительным. Поэтому в целях сокращения вероятности выполнения таких дорогих (по времени) операций компилятор использует стратегию оптимизации. В данном примере, если сразу добавить к вектору еще один или два объекта, отпадает необходимость в дополнительных операциях, связанных с освобождением и перераспределением памяти. В строках 104 и 105 вновь используется оператор индексирования ([]), чтобы изменить переменные-члены первого объекта в векторе GrowingClass. Рекомендуется:Определяйте стандартный конструктор для класса, если его объекты будут содержаться в векторе. Определяйте конструктор-копировщик для такого класса. Определяйте для такого класса перегруженный оператор присваивания. Класс-контейнер вектора имеет и другие функции-члены. Функция front() возвращает ссылку на первый элемент в списке, а функция back() — на последний. Функция at() работает подобно оператору индексирования ([]). Она более безопасна, поскольку проверяет, попадает ли переданный ей индекс в диапазон доступных элементов. Если адрес оказывается вне диапазона, эта функция генерирует исключение out_of_range. (Исключительные ситуации рассматриваются на следующем занятии.) Функция insert() вставляет один или несколько узлов (элементов) в текущую позицию вектора. Функция Pop_back() удаляет из вектора последний элемент. Наконец, функция remove() удаляет из вектора один или несколько элементов. СписокСписок — это контейнер, разработанный для обеспечения оптимального выполнения частых вставок и удалений элементов. Класс-контейнер библиотеки STL list определен в файле заголовка <list> в пространстве имен std. Класс list выполнен как двунаправленный связанный список, в котором каждый узел содержит указатели как на предыдущий, так и на последующий узел списка. Класс list имеет все функции-члены, предоставляемые векторным классом. Как вы помните, список можно пройти, следуя по связям между узлами, реализованным с помощью указателей. Стандартный класс-контейнер list с той же целью использует алгоритм, называемый итератором. Итератор — это обобщение указателя. Чтобы отыскать узел, на который указывает итератор, его нужно разыменовывать. Использование итераторов для доступа к узлам списка демонстрируется в листинге 19.9. Листинг 19.9. Навигация по списку с ппмощью итератора 1: #include <iostream> 2: #include <list> 3: using namespace std; 4: 5: typedef list<int> IntegerList; 6: 7: int main() 8: { 9: IntegerList intList; 10: 11: for (int i = 1; i <= 10; ++i) 12: intList.push_back(i * 2); 13: 14: for (IntegerList::const_iterator ci = intList.begin(); 15: ci!= intList.end(); ++ci) 16: cout << *ci << " "; 17: 18: return 0; 19: } Результат: 2 4 6 8 10 12 14 16 18 20 Анализ: В строке 9 объект intList определен как список целых чисел. В строках 11 и 12 с помощью функции push_back() в список добавляются первые 10 положительных четных чисел. В строках 14-16 мы обращаемся к каждому узлу в списке, используя константный итератор. Константность указывает, что мы не собираемся изменять узлы с помощью этого итератора. Если бы мы хотели изменить узел, на который указывает итератор, пришлось бы использовать переменный итератор: intList::iterator Функция-член begin() возвращает итератор на первый узел списка. Оператор инкремента (++) можно использовать для перехода к итератору следующего узла. Функция-член end(), что может показаться странным, возвращает итератор на узел, расположенный за последним узлом списка. Часто метод end() используют для определения допустимых границ списка. Разыменование итератора (для возвращения связанного с ним узла) происходит аналогично разыменованию указателя, как показано в строке 16. Хотя понятие итератора было введено только при рассмотрении класса list, итераторы можно использовать и с векторными классами. В дополнение к функциям-членам, с которыми вы познакомились в векторном классе, базовый класс списка тоже представляет функции push_front() и pop_front(), которые работают точно так же, как и функции push_back() и pop_back(). Но вместо добавления и удаления элементов в конце списка, они добавляют и удаляют элементы в его начале. Контейнер двухсторонней очередиДвухсторонняя очередь подобна двунаправленному вектору — она наследует эффективность класса-контейнера vector по операциям последовательного чтения и записи. Но, кроме того, класс контейнер deque обеспечивает оптимизированное добавление и удаление узлов с обоих концов очереди. Эти операции реализованы аналогично классу-контейнеру list, где процесс выделения памяти запускается только для новых элементов. Эта особенность класса двухсторонней очереди устраняет потребность перераспределения целого контейнера в новую область памяти, как это приходится делать в векторном классе. Поэтому двухсторонние очереди идеально подходят для приложений, в которых вставки и удаления происходят с двух концов массива и для которых имеет важное значение последовательный доступ к элементам. Примером такого приложения может служить имитатор сборки поезда, в котором вагоны могут присоединяться к поезду с обоих концов. СтекиОдной из самых распространенных в программировании структур данных является стек. Однако стек не используется как независимый контейнерный класс, скорее, его можно назвать оболочкой контейнера. Шаблонный класс stack определен в файле заголовка <stack> в пространстве имен std. Стек — это непрерывный выделенный блок памяти, который может расширяться или сжиматься в хвостовой части, т.е. к элементам стека можно обращаться или удалять только с одного конца. Вы уже видели подобные характеристики в последовательных контейнерах, особенно в классах vector и deque. Фактически для реализации стека можно использовать любой последовательный контейнер, который поддерживает функции back(), push_back() и pop_back(). Большинство других методов контейнеров для работы стека не используются, поэтому они и не предоставляются классом stack. Базовый шаблонный класс stack библиотеки STL шаблона разработан для поддержания объектов любого типа. Единственное ограничение состоит в том, что все элементы должны иметь один и тот же тип. Данные в стеке организованы по принципу "последним вошел — первым вышел". Ее можно сравнить с переполненным лифтом: первый человек, вошедший в лифт, припирается к стене, а последний втиснувшийся стоит прямо у двери. Когда лифт поднимается на указанный кем-то из пассажиров этаж, тот, кто зашел последним, должен выйти первым, Если кто-нибудь (из стоящих посередине пассажиров) захочет выйти из лифта раньше других, то все, кто находится между ним и дверью, должны выйти из лифта, выпустив его, а затем вернуться обратно. Открытый конец стека называется вершиной стека, а действия, выполняемые с элементами стека, — операциями помещения (push) и выталкивания (pop) из стека. Для класса stack эти общепринятые термины остаются в силе. Примечание:Класс stack из библиотеки STL не соответствует стекам памяти, используемым компиляторами и операционными системами, которые могут содержать объекты различных типов, хотя они работают сходным образом. ОчередьОчередь — это еще одна распространенная в программировании структура данных. В этом случае элементы добавляются к очереди с одного конца, а вынимаются с другого. Приведем классическую аналогию. Вспомним стек. Его можно сравнить со стопкой тарелок на столе. При добавлении в стек тарелка ставится сверху всей стопки (помещение в стек), и взять тарелку из стопки (стека) можно тоже только сверху (выталкивание из стека), т.е. берется тарелка, которая была положена в стопку самой последней. Очередь же можно сравнить с любой очередью людей, например при входе в театр. Вы занимаете очередь сзади, а покидаете ее спереди. Конечно, каждому из нас приходилось стоять предпоследним в какой-нибудь очереди (например, в магазине), когда вдруг начинает работать еще одна касса, к которой подбегает стоявший за вами, что скорее напоминает стек, чем очередь. Но в компьютерах такого не случается. Подобно классу stack, класс queue реализован как класс оболочки контейнера. Контейнер должен поддерживать такие функции, как front(), back(), push_back() и pop_front(). Ассоциативные контейнерыТогда как последовательные контейнеры предназначены для последовательного и произвольного доступа к элементам с помощью индексов или итераторов, ассоциативные контейнеры разработаны для быстрого произвольного доступа к элементам с помощью ключей. Стандартная библиотека C++ предоставляет четыре ассоциативных контейнера: карту, мульти карту, множество и мультимножество. КартаВектор можно сравнить с расширенной версией массива. Он имеет все характеристики массива и ряд дополнительных возможностей. К сожалению, вектор также страдает от одного из существенных недостатков массивов: он не предоставляет возможности для произвольного доступа к элементам с помощью ключа, а лишь использует для этого индекс или итератор. Ассоциативные контейнеры как раз обеспечивают быстрый произвольный доступ, основанный на ключевых значениях. В листинге 19.10 для создания списка студентов, который мы рассматривали в листинге 19.8, используется карта. Листинг 19.10. Класс-контейнер map 1: #include <iostream> 2: #include <string> 3: #include <map> 4: using namespace std; 5: 6: class Student 7: { 8: public: 9: Student(); 10: Student(const string& name, const int age); 11: Student(const Student& rhs); 12: ~Student(); 13: 14: void SetName(const string& namе); 15: string GetName() const; 16: void SetAge(const int age); 17: int GetAge() const; 18: 19: Student& operator=(const Student& rhs); 20: 21: private: 22: string itsName; 23: int itsAge; 24: }; 25: 26: Student::Student() 27: : itsName("New Student"), itsAge(16) 28: { } 29: 30: Student::Student(const string& name, const int 31: : itsName(name), itsAge(age) 32: { } 33: 34: Student::Student(const Student& rhs) 35: : itsName(rhs.GetName()), itsAge(rhs.GetAge()) 36: { } 37: 38: Student::~Student() 39: { } 40: 41: void Student::SetName(const string& name) 42: { 43: itsName = name; 44: } 45: 46: string Student::GetName() const 47: { 48: return itsName; 49: } 50: 51: void Student::SetAge(const int age) 52: { 53: itsAge = age; 54: } 55: 56: int Student::GetAge() const 57: { 58: return itsAge; 59: } 60: 61: Student& Student::operator=(const Student& rhs) 62: { 63: itsName = rhs,GetName(); 64: itsAge = rhs.GetAge(); 65: return *this; 66: } 67: 68: ostream& operator<<(ostream& os, const Student& rhs) 69: { 70: os << rhs.GetName() << " is " << rhs.GetAge() << " years old"; 71: return os; 72: } 73: 74: template<class T, class A> 75: void ShowMap(const map<T, A>& v); // отображает свойства карты 76: 77: typedef map<string, Student> SchoolClass; 78: 79: int main() 80: { 81: Student Harry("Harry", 18); 82: Student Sally("Sally", 15); 83: Student Bill("Bill", 17); 84: Student Peter("Peter", 16); 85: 86: SchoolClassMathClass; 87: MathClass[Harry.GetName() ] = Harry; 88: MathClass[Sally.GetName()] = Sally; 89: MathClass[Bill.GetName() ] = Bill; 90: MathClass[Peter.GetName()] = Peter; 91: 92: cout << "MathClass;\n"; 93: ShowMap(MathClass); 94: 95: cout << "We know that " << MathClass["Bill"].GetName() 96: << " is " << MathClass["Bill"].GetAge() << "years old\n"; 97: 98: return 0; 99: } 100: 101: // 102: // Отображает свойства карты 103: // 104: template<class T, class A> 105: void ShowMap(const map<T, А>& v) 106: { 107: for (map<T, A>::const_iterator ci = v.begin(); 108: ci != v.end(); ++ci) 109: cout << ci->first << ": " << ci->second << "\n"; 110: 111: cout << endl; 112: } Результат: MathClass: Bill: Bill is 17 years old Harry: Harry is 18 years old Peter: Peter is 16 years old Saily: Sally is 15 years old We know that Bill is 17 years old Анализ: В строке 3 в программу добавляется файл заголовка <map>, поскольку будет использоваться стандартный класс-контейнер map. Для отображения элементов карты определяется шаблонная функция ShowMap. В строке 77 класс SchoolClass определяется как карта элементов, каждый из которых состоит из пары (ключ, значение). Первая составляющая пары — это значение ключа. В нашем классе SchoolClass имена студентов используются в качестве ключевых значений, которые имеют тип string. Ключевое значение элемента в контейнере карты должно быть уникальным, т.е. никакие два элемента не могут иметь одно и то же ключевое значение. Вторая составляющая пары — фактический объект, в данном примере это объект класса Student. Парный тип данных реализован в библиотеке STL как структура (тип данных struct), состоящая из двух членов, а именно: first и second. Эти члены можно использовать для получения доступа к ключу и значению узла. Пропустим пока функцию main() и рассмотрим функцию StwtMap, которая открывает доступ к объектам карты с помощью константного итератора. Выражение ci->first (строка 109) указывает на ключ (имя студента), а выражение ci->second — на объект класса Student. В строках 81-84 создаются четыре объекта класса Student. Класс MathClass определяется как экземпляр класса SchoolClass (строка 86), а в строках 87-90 уже имеющиеся четыре студента добавляются в класс MathClass: map_object[key_value] = object_value; Для добавления в карту пары ключ—значение можно было бы также использовать функции push_back() или insert() (за более подробной информацией обратитесь к документации, прилагаемой к вашему компилятору). После добавления к карте всех объектов класса Student можно обращаться к любому из них, используя их ключевые значения. В строках 95 и 96 для считывания записи, относящейся к студенту Биллу (объекту Bill), используется выражение MathClass["Bill"]. Другие ассоциативные контейнерыКласс-контейнер мультикарты — это класс карты, не ограниченный уникальностью ключей. Это значит, что одно и то же ключевое значение могут иметь не один, а несколько элементов. Класс-контейнер множества также подобен классу карты. Единственное отличие в том, что его элементы представляют собой не пары ключ-значение, а только ключи. Наконец, класс-контейнер мультимножества — это класс множества, который позволяет иметь несколько ключевых значений. Классы алгоритмовКонтейнер — это удобное место для хранения последовательности элементов. Все стандартные контейнеры содержат методы управления контейнерами и их элементами. Однако манипулирование собственными данными в программах с помощью этих методов может потребовать от программиста написания обширного программного кода, что чревато появлением ошибок. Но поскольку большинство операций, выполняемых над данными, рутинны и повторяются от программы к программе, то подборка универсальных алгоритмов может существенно облегчить написание программ обработки данных контейнера. Стандартная библиотека предоставляет около 60 стандартных алгоритмов, которые выполняют большинство базовых и часто используемых операций, характерных для контейнеров. Стандартные алгоритмы определены в файле <algorithm> в пространстве имен std. Чтобы понять, как работают стандартные алгоритмы, необходимо познакомиться с понятием объектов функций. Объект функции — это экземпляр класса, в котором определен перегруженный оператор вызова функции(). В результате этот класс может вызываться как функция. Использование объекта функции показано в листинге 19.11. Листинг 19.11. объект функции 1: #include <iostream> 2: using namespace std; 3: 4: template<class T> 5: class Print { 6: public: 7: void operator()(const T& t) 8: { 9: cout << t << " "; 10: } 11: }; 12: 13: int main() 14: { 15: Print<int> DoPrint; 16: for (int i = 0; i < 5; ++i) 17: DoPrint(i); 18: return 0; 19: } Результат: 0 1 2 3 4 Анализ: В строках 4—11 определяется шаблонный класс Print. Перегруженный в строках 7—10 оператор вызова функции () принимает объект и перенаправляет его в стандартный поток вывода. В строке 15 определяется объект DoPrint как экземпляр класса Print. После этого, чтобы вывести на печать любые целочисленные значения, объект DoPrint можно использовать подобно обычной функции, как показано в строке 17. Операции, не изменяющие последовательностьОперации, не изменяющие последовательность данных в структуре, реализуются с помощью таких функций, как for_each() и find(), search(), count() и т.д. В листинге 19.12 показан пример использования объекта функции и алгоритм for_each, предназначенный для печати элементов вектора. Листинг 18.12. Использование алгоритма for_each() 1: #include <iostream> 2: #include <vector> 3: #include <algorithm> 4: using namespace std; 5: 6: template<class T> 7: class Print 8: { 9: public: 10: void operator()(const T& t) 11: { 12: cout << t << " "; 13: } 14: }; 15: 16: int main() 17: { 18: Print<int> DoPrint; 19: vector<int> vInt(5); 20: 21: for (int i = 0; i < 5; ++i) 22: vInt[i] = i * 3; 23: 24: cout << "for_each()\n"; 25: for_each(vInt.begin(), vInt.end(), DoPrint); 26: cout << "\n"; 27: 28: return 0; 29: } Результат: for_each() 0 3 6 9 12 Анализ: Обратите внимание, что все стандартные алгоритмы C++ определены в файле заголовка <algorithm>, поэтому следует включить его в нашу программу. Большая часть программы не должна вызывать никаких трудностей. В строке 25 вызывается функция for_each(), чтобы опросить каждый элемент в векторе vInt. Для каждого элемента она вызывает объект функции DoPrint и передает этот элемент оператору DoPrint.operator(), что приводит к выводу на экран значения данного элемента. Алгоритмы изменения последовательностиПод изменением последовательности понимают изменение порядка элементов в структуре данных. Изменять последовательность способны операции, связанные с заполнением или переупорядочением коллекций. Алгоритм заполнения показан в листинге 19.13. Листинг 19.13. Алгоритм изменения последовательности 1: #include <iostream> 2: #include <vector> 3: #include <algorithm> 4: using namespace std; 5: 6: template<class T> 7: class Print 8: { 9: public: 10: void operator()(const T& t) 11: { 12: cout << t << " "; 13: } 14: }; 15: 16: int main() 17: { 18: Print<int> DoPrint; 19: vector<int> vInt(10); 20: 21: fill(vInt.begin(), vInt.begin()+5, 1); 22: fill(vInt.begin() + 5, vInt.end(), 2); 23: 24: for_each(vInt.begin(), vInt.end(), DoPrint); 25: cout << "\n\n"; 26: 27: return 0; 28: } Результат: 1 1 1 1 1 2 2 2 2 2 Анализ: Единственная новая деталь в этом листинге содержится в строках 21 и 22, где используется алгоритм fill(). Алгоритм заполнения предназначен для заполнения элементов последовательности заданным значением. В строке 21 целое значение 1 присваивается первым пяти элементам в векторе vInt. А последним пяти элементам вектора vInt присваивается целое число 2 (в строке 22). РезюмеСегодня вы узнали, как создавать и использовать шаблоны — встроенное средство языка C++, используемое для создания параметризованных типов, т.е. типов, которые изменяют свое выполнение в зависимости от параметров, переданных при создании класса. Таким образом, шаблоны - это возможность многократного использования программного кода, причем безопасным и эффективным способом, В определении шаблона устанавливается параметризованный тип, Каждый экземпляр шаблона — это реальный объект, который можно использовать подобно любому другому объекту: в качестве параметра функции, возвращаемого значения и т.д. Классы шаблонов могут объявлять три типа функций-друзей: не относящихся к шаблону, шаблонных и специализированных по типу. В шаблоне можно объявлять статические члены. Тогда каждый экземпляр шаблона будет иметь собственный набор статических данных. Если нужно специализировать выполнение функции шаблона в зависимости от типа, то ее можно замещать для разных типов. Вопросы и ответыЧем использование шаблонов лучше использования макросов? Шаблоны обеспечивают более безопасное использование разных типов и встроены в язык. Какова разница между параметризованным типом функции шаблона и параметрами обычной функции? Обычная функция (не шаблонная) принимает параметры, с которыми может выполнять заданные действия. Функция шаблона позволяет с помощью параметра шаблона устанавливать тип передаваемого параметра функции. Так, в функцию можно передать массив объектов, тип которых будет уникален для разных экземпляров шаблона. Когда следует использовать шаблоны, а когда наследование? Используйте шаблоны в том случае, когда все или почти все выполнение класса остается неизменным, а изменяется только тип данных, используемых в классе. Когда использовать дружественные шаблонные классы и функции? Когда каждый экземпляр, независимо от типа, должен быть другом по отношению к этому классу или функции. Когда использовать дружественные шаблонные классы или функции, специализированные по типу? Когда между двумя классами нужно установить отношения по типу один-к-одному. Например, массив array<lnt> должен соответствовать итератору iterator<int>, но не iterator<Animal>. Каковы два типа стандартных контейнеров? Последовательные и ассоциативные контейнеры. Последовательные контейнеры обеспечивают оптимизированный последовательный и произвольный доступ к своим элементам. Ассоциативные контейнеры обеспечивают оптимизированный доступ к элементам на основе ключевых значений. Какими атрибутами должен обладать класс, чтобы его можно было использовать со стандартными контейнерами? В классе должны быть явно определены стандартный конструктор, конструктор- копировщик и перегруженный оператор присваивания. КоллоквиумВ этом разделе предлагаются вопросы для самоконтроля и укрепления полученных знаний, а также ряд упражнений, которые помогут закрепить ваши практические навыки. Попытайтесь самостоятельно ответить на вопросы теста и выполнить задания, а потом сверьте полученные результаты с ответами в приложении Г. Не приступайте к изучению материала следующей главы, если для вас остались неясными хотя бы некоторые из предложенных ниже вопросов. Контрольные вопросы1. Какова разница между шаблоном и макросом? 2. В чем состоит отличие параметра шаблона от параметра функции? 3. Чем отличается обычный дружественный шаблонный класс от дружественного шаблонного класса, специализированного по типу? 4. Можно ли обеспечить особое выполнение для определенного экземпляра шаблона? 5. Сколько статических переменных-членов будет создано, если в определение класса шаблона поместить один статический член? 6. Что представляют собой итераторы? 7. Что такое объект функции? Упражнения1. Создайте шаблон на основе данного класса List: class List { public: List():head(0),tail(0),theCount(0) { } virtual ~List(); void insert( int value ); void append( int value ); int is_present( int value ) const; int is_empty() const { return head == 0; } int count() const { return theCount; } private: class ListCell { public: ListCell(int value, ListCell *cell = ):val(value),next(cell){ } int val; ListCell *next; }; ListCell *head; ListCell *tail; int theCount; }; 2. Напишите выполнение обычной (не шаблонной) версии класса List. 3. Напишите шаблонный вариант выполнения. 4. Объявите три списка объектов: типа Strings, типа Cat и типа int. 5. Жучки: что неправильно в приведенном ниже программном коде? (Предположите, что определяется шаблон класса List, а Cat — это класс, определенный на одном из предыдущих занятий.) List<Cat> Cat_List; Cat Felix; CatList.append( Felix ); cout << "Felix is " << ( Cat_List.is_present( Felix ) ) ? "" : "not " << "present\n"; 6. ПОДСКАЗКА (поскольку задание не из самых легких): подумайте, чем тип Cat отличается от типа int? 7. Объявите дружественный оператор operator== для класса List. 8. Напишите выполнение дружественного оператора operator== для класса List. 9. Грешит ли оператор operator== той же проблемой, которая существует в упражнении 5? 10. Напишите выполнение функции шаблона, осуществляющей операцию обмена данными, в результате чего две переменные должны обменяться содержимым. 11. Напишите выполнение класса SchoolClass, показанного в листинге 19.8, как списка. Для добавления в список четырех студентов используйте функцию push_back(). Затем пройдитесь по полученному списку и увеличьте возраст каждого студента на один год. 12. Измените код из упражнения 10 таким образом, чтобы для отображения данных о каждом студенте использовался объект функции. День 20-й. Отслеживание исключительных ситуаций и ошибокПрограммный код, представленный в этой книге, был создан в иллюстративных целях. Мы не упоминали о возможных ошибках, чтобы не отвлекать вас от основных моментов программирования, представленных в том или ином фрагменте программы. Реальные же программы должны обязательно предусматривать возможные аварийные ситуации. Сегодня вы узнаете: • Что представляют собой исключительные ситуации • Как перехватываются и обрабатываются исключения • Что такое наследование исключений • Как использовать исключения в общей структуре отслеживания и устранения ошибок • Что представляет собой отладка программы Ошибки, погрешности, ляпусы и "гнилой" кодК сожалению, все программисты допускают ошибки. Чем больше программа, тем выше вероятность возникновения в ней ошибок, многие из которых до поры до времени остаются незамеченными и попадают в конечный программный продукт, уже выпущенный на рынок. С этой печальной истиной трудно смириться, поэтому создание надежных, свободных от ошибок программ должно быть задачей номер один для каждого программиста, серьезно относящегося к своему делу. Одна из наиболее острых проблем в индустрии создания программ — это нестабильный программный код, нафаршированный ошибками. Обычно самые большие расходы во многих работах, связанных с программированием, приходятся на тестирование программ и исправление ошибок. Тот, кто решит проблему создания добротных, надежных и безотказных программ за короткий срок и при низких затратах, произведет революцию во всей индустрии программных продуктов. Все ошибки в программах можно разделить на несколько групп. Первый тип ошибок вызван недостаточно проработанной логикой алгоритма выполнения программы. Второй тип — синтаксические ошибки, т.е. использование неправильной идиомы, функции или структуры. Эти два типа ошибок самые распространенные, поэтому именно на них сосредоточено внимание программистов. Теория и практика неопровержимо доказали, что чем позже в процессе разработки обнаруживается проблема, тем дороже стоит ее устранение. Оказывается, что проблемы или ошибки в программах дешевле всего обойдутся компании в том случае, если своевременно принять меры по предупреждению их появления. Не слишком дорого обойдутся и те ошибки, которые распознаются компилятором. Стандарты языка C++ заставляют разработчиков создавать такие компиляторы, которые способны обнаруживать как можно больше ошибок на этапе компиляции программы. Ошибки, которые прошли этап компиляции, но были выявлены при первом же тестировании и обнаруживались регулярно, также легко устранимы, чего не скажешь о "минах замедленного действия", проявляющих себя внезапно в самый неподходящий момент. Еще большей проблемой, чем логические или синтаксические ошибки, является недостаточная устойчивость программ, т.е. программа сносно работает в том случае, если пользователь вводит данные, которые предусматривались, но дает сбой, если по ошибке, например, вместо числа будет введена буква. Другие программы внезапно зависают из-за переполнении памяти, или при извлечении из дисковода гибкого диска, или при потере линии модемом. Чтобы повысить устойчивость программ, программисты стремятся предупредить все варианты непредвиденных ситуаций. Устойчивой считают программу, которая может справляться во время работы с любыми неожиданностями: от получения нестандартных данных, введенных пользователем, до переполнения памяти компьютера. Важно различать ошибки, которые возникают вследствие некорректного синтаксиса программного кода, логические ошибки, которые возникают потому, что программист неправильно истолковал проблему или неправильно решил ее, и исключительные ситуации, которые возникают из-за необычных, но предсказуемых проблем, например связанных с конфликтами ресурсов (имеется в виду недостача памяти или дискового пространства). Исключительные ситуацииДля выявления синтаксических ошибок программисты используют встроенные средства компилятора и добавляют в программы различные ловушки ошибок, которые подробнее обсуждаются на следующем занятии. Для обнаружения логических ошибок проводится критический анализ проектных решений и всестороннее тестирование программного продукта. Однако ни в одной программе нельзя устранить возможность возникновения исключительных ситуаций. Единственное, что может сделать программист, это подготовить программу к их возникновению. Например, невозможно средствами программирования предупредить переполнение памяти компьютера во время выполнения программы, но от программиста зависит, как поведет себя программа в этой ситуации. Можно выбрать следующие варианты ответа программы: • привести программу к аварийному останову; • информировать пользователя о случившемся и корректно выйти из программы; • информировать пользователя и позволить ему сделать попытку восстановить рабочее состояние программы и продолжить работу; • выбрать обходной путь и продолжить работу программы, не беспокоя пользователя. Последний вариант, т.е. выбор обходного пути, безусловно, предпочтительнее аварийного останова программы. Хотя этот вариант не является необходимым или даже желательным в каждой программе, все-таки стоит написать такой код, который бы самостоятельно, автоматически, без лишнего шума справлялся со всеми исключительными ситуациями и продолжал работу. Язык C++ предоставляет безопасные интегрированные методы отслеживания всех возможных исключительных ситуаций, возникающих во время выполнения программы. Несколько слов о "гнилом" кодеТо, что программный продукт может портиться со временем, прямо как яблоко на вашем столе, — вполне доказанный факт. Это явление возникает не по вине злых бактерий или грибков и не из-за пыли на компьютере, а потому, что практически любой код содержит скрытые внутренние ошибки, к которым добавляется нарастающее несоответствие старой программы новому компьютерному обеспечению и программному окружению. Идеально написанная и хорошо отлаженная программа очень быстро может превратиться в безделицу, больше не привлекающую внимания пользователя. Чтобы иметь возможность быстро исправлять возникающие ошибки и модернизировать программу в соответствии с требованиями текущего дня, необходимо так писать программный код, чтобы разобраться в нем по прошествию некоторого времени могли не только вы, но и любой другой программист. Примечание:"Гнилой" код — это шутливый термин, придуманный программистами для объяснения того, как хорошо отлаженные программы вдруг становятся ненадежными и неэффективными. Об этом явлении не стоит забывать, ведь программы часто бывают чрезвычайно сложными, из-за чего многие ошибки, погрешности и ляпсусы могут долгое время оставаться в тени, пока не проявят себя во всей красе. Для защиты от подобной "плесени" нужно писать код таким образом, чтобы самим было несложно поддерживать его работоспособность. Это означает, что ваш код должен быть подробно прокомментирован, даже если вы и не предполагаете, что кто-то другой, кроме вас, может заглянуть в него. Когда пройдет месяцев шесть после того, как вы передадите свой код заказчику, вы сами будете смотреть на свою программу глазами постороннего человека и удивляться тому, как можно было написать такой непонятный и извилистый код, надеясь при этом на успешную работу. ИсключенияВ C++ исключение — это объект, который передается из области кода, где возникла проблема, в ту часть кода, где эта проблема обрабатывается. Тип исключения определяет, какая область кода будет обрабатывать проблему и как содержимое переданного объекта, если он существует, может использоваться для обратной связи с пользователем. Основная идея использования исключений довольно проста. • Фактическое распределение ресурсов (например, распределение памяти или захват файла) обычно осуществляется в программе на низком уровне. • Выход из исключительной ситуации, возникшей при сбое операции из-за нехватки памяти или захвата файла другим приложением обычно реализуется на высоком уровне программирования в коде, описывающем взаимодействие программы с пользователем. • Исключения обеспечивают переход от кода распределения ресурсов к коду обработки исключительной ситуации. Желательно, чтобы код обработки исключительной ситуации не только отслеживал ее появление, но и мог обеспечить элегантный выход из исключительной ситуации, например отмену выделения памяти в случае ее нехватки. Как используются исключенияСоздаются блоки try для помещения в них фрагментов кода, которые могут вызвать проблему, например: try { SomeDangerousFunction(); } Исключения, возникшие в блоках try, обрабатываются в блоках catch, например: try { SomeDangerousFunction(); } catch(OutOfMemory) { // предпринимаем некоторые действия } catch(FileNotFound) { // предпринимаем другие действия } Ниже приведены основные принципы использовании исключений. 1. Идентифицируйте те области программы, где начинается выполнение операции, которая могла бы вызвать исключительную ситуацию, и поместите их в блоки try. 2. Создайте блоки catch для перехвата исключений, если таковые возникнут, очистки выделенной памяти и информирования пользователя соответствующим образом. В листинге 20.1 иллюстрируется использование блоков try и catch. Исключения — это объекты, которые используются для передачи информации о проблеме. Блок try — это заключенный в фигурные скобки блок, содержащий фрагменты программы, способные вызвать исключительные ситуации. Блок catch — это блок, который следует за блоком try и в котором выполняется обработка исключений. При возникновении исключительной ситуации управление передается блоку catch, который следует сразу за текущим блоком try. Примечание:Некоторые очень старые компиляторы не поддерживают обработку исключений. Однако обработка исключений является частью стандарта ANSI C++. Все современные версии компиляторов полностью поддерживают эту возможность. Если у вас устаревший компилятор, вы не сможете скомпилировать и выполнить листинги, приведенные на этом занятии. Однако все же стоит прочитать представленный материал до конца, а затем вернуться к нему после обновления своего компилятора. Листинг 20.1. Возникновение исключительной ситуации 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // конструкторы 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // операторы 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // методы доступа 19: int GetitsSize() const { return itsSize; } 20: 21: // функция-друг 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: class xBoundary { } ; // определяем класс исключений 25: private: 26: int *pType; 27: int itsSize; 28: }; 29: 30: 31: Array::Array(intsize): 32: itsSize(size) 33: { 34: рТуре = new int[size]; 35: for (int i = 0; i<size; i++) 36: pType[i] = 0; 37: } 38: 39: 40: Array& Array::operator=(const Array &rhs) 41: { 42: if (this == &rhs) 43: return *thts; 44: delete [] pType; 45: itsSize = rhs.GetitsSiza(); 46: pType = new int[itsSize]; 47: for (int i = 0; i<itsSize; i++) 48: pType[i] = rhs[i]; 49: return *this; 50: } 51: 52: Array::Array(const Array &rhs) 53: { 54: itsSize = rhs.GetitsSize(); 55: pType = new int[itsSize]; 56: for (int i = 0; i<itsSize; i++) 57: pType[i] = rhs[i]; 58: } 59: 60: 61: int& Array::operator[](int offSet) 62: { 63: int size = GetitsSize(); 64: if (offSet >= 0 && offSet < GetitsSize()) 65: return pType[offSet]; 66: throw xBoundary(); 67: return pType[0]; // требование компилятора 68: } 69: 70: 71: const int& Array::operator[](int offSet) const 72: { 73: int mysize = GetitsSize(); 74: if (offSet >= 0 && offSet < GetitsSize()) 75: return pType[offSet]; 76: throw xBoundary(); 77: return pType[0]; // требование компилятора 78: } 79: 80: ostream& operator<< (ostream& output, const Array& theArray) 81: { 82: for (int i = 0; i<theArray,GetitsSize(); i++) 83: output << "[" << i << "] " << theArray[i] << endl; 84: return output; 85: } 86: 87: int main() 88: { 89: Array intArray(20); 90: try 91: { 92: for (int ] << 0; j< 100; j++) 93: { 94: intArray[j] = j; 95: cout << "intArray[" << j << "] okay..." << endl; 96: } 97: } 98: catch (Array::xBoundary) 99: { 100: cout << "Unable to process your input!\n"; 101: } 102: cout << "Done.\n"; 103: return 0; 104: } Результат: intArray[0] okay... intArray[1] okay... intArray[2] okay... intArray[3] okay... intArray[4] okay... intArray[5] okay... intArray[6] okay... intArray[7] okay... intArray[8] okay... intArray[9] okay... intArray[10] okay... intArray[11] okay... intArray[12] okay... intArray[13] okay... intArray[14] okay... intArray[15] okay... intArray[16] okay... intArray[17] okay... intArray[18] okay... intArray[19] okay... Unable to process your input! Done. Анализ: В листинге 20.1 представлен несколько усеченный класс Array, основанный на шаблоне, разработанном на занятии 19. В строке 24 объявляется новый класс xBoundary внутри объявления внешнего класса Array. В этом новом классе ни по каким внешним признакам нельзя узнать класс обработки исключительных ситуаций. Он чрезвычайно прост и не содержит никаких данных и методов. Тем не менее это вполне работоспособный класс. На самом деле было бы неправильно говорить, что он не содержит никаких методов, потому что компилятор автоматически назначает ему стандартный конструктор, деструктор, конструктор-копировщик и оператор присваивания (=), поэтому у него фактически есть четыре метода, но нет данных. Обратите внимание на то, что его объявление внутри класса Array служит только для объединения двух классов. Как описано в главе 15, класс Array не имеет никакого особого доступа к классу xBoundary, да и класс xBoundary не наделен преимущественным доступом к членам класса Array. В строках 61—68 и 71—78 операторы индексирования ([]) замещены таким образом, чтобы предварительно анализировать введенный индекс смещения и, если оно окажется вне допустимого диапазона, обратиться к классу xBoundary для создания исключения. Назначение круглых скобок состоит в том, чтобы отделить обращение к конструктору класса xBoundary от использования константы перечисления. Обратите внимание, что некоторые компиляторы компании Microsoft требуют, чтобы определение функции в любом случае заканчивалось строкой с оператором return, согласующейся по типу с прототипом функции (в данном случае возвращение ссылки на целочисленное значение), несмотря на то что в случае возникновения исключительной ситуации в строке 66 выполнение программы никогда не достигнет строки 67. Этот пример говорит о том, что логические ошибки не чужды даже компании Microsoft! В строке 90 ключевым словом try начинается блок отслеживания исключительных ситуаций, который оканчивается в строке 97. Внутри этого блока в массив, объявленный в строке 89, добавляется 101 целое число. В строке 98 объявлен блок catch для перехвата исключений класса xBoundary. В управляющей программе в строках 87—104 создается блок try, в котором инициализируется каждый член массива. Когда переменная j (строка 92) увеличится до 20, осуществляется доступ к члену, соответствующему смещению 20. Это приводит к невыполнению условия проверки в строке 64, в результате чего замещенный оператор индексирования operator[] генерирует исключение класса xBoundary (строка 66). Управление программой передается к блоку catch в строке 98, и исключение перехватывается или обрабатывается оператором catch в той же строке, которая печатает сообщение об ошибках. Программа доходит до конца блока catch в строке 100. Блок отслеживания исключительных ситуаций Этот блок представляет собой набор выражений, начинающийся ключевым словом try, 3a которым следует открывающая фигурная скобка; завершается блок закрываю- щей фигурной скобкой. Пример: try { Function(); } Блок обработки исклтчительиых ситуаций Этот блок представпяет собой набор строк, каждая из них начинается ключевым словом catch, за которым следует тип исключения, заданный в круглых скобках. Затем идет открывающая фигурная скобка. Завершается блок-catch закрывающей фигурной скобкой. Пример: try { Function(); } catch (OutOfMemory) { // выполняем дествие } Использование блоков try и catchЧасто не так уж просто решить, куда поместить блоки try, поскольку не всегда очевидно, какие действия могут вызвать исключительную ситуацию. Следующий вопрос состоит в том, где перехватывать исключение. Может быть, вы захотите генерировать исключения, связанные с памятью, там, где память распределяется, но в то же время перехватывать исключения стоит только в высокоуровневой части программы, связанной с интерфейсом пользователя. При попытке определить местоположение блока try выясните, где в программе происходит распределение памяти или других ресурсов. При ошибках, связанных с выходом значений за допустимые пределы, вводом некорректных данных и пр., нужно использовать другие подходы. Перехват исключенийПерехват исключений происходит следующим образом. Когда генерируется исключение, исследуется стек вызовов. Он представляет собой список обращений к функциям, создаваемый по мере того, как одна часть программы вызывает другую функцию. Стек вызовов отслеживает путь выполнения программы. Если функция main() вызывает функцию Animal::GetFavoriteFood(), а функция GetFavoriteFood() — функцию Animal::LookupPreferences(), которая, в свою очередь, вызывает функцию fstream::operator>>(), то все эти вызовы заносятся в стек вызовов. Рекурсивная функция может оказаться в стеке вызовов много раз. Исключение передается в стек вызовов для каждого вложенного блока. По мере прохождения стека вызываются деструкторы для локальных объектов, в результате чего эти объекты разрушаются. За каждым блоком try следует один или несколько блоков catch. Если сгенерированное исключение соответствует одному из исключений операторов catch, то выполняется код блока этого оператора. Если же исключению не соответствует ни один из операторов catch, прохождение стека продолжается. Если исключение пройдет весь путь к началу программы (функции main()) и все еще не будет перехвачено, вызывается встроенный обработчик, который завершит программу. Прохождение исключения по стеку можно сравнить с поездкой по улице с односторонним движением. По мере прохождения стека его объекты разрушаются. Назад дороги нет. Если исключение перехвачено и обработано, программа продолжит работу после блока catch, который перехватил это исключение. Таким образом, в листинге20.1 выполнение программы продолжится со строки 101 — первой строки после блока try catch, перехватившего исключение xBoundary. Помните, что при возникновении исключительной ситуации выполнение программы продолжается после блока catch, а не после того места, где она возникла. Использование нескольких операторов catchВ некоторых случаях выполнение одного выражения потенциально может быть причиной возникновения нескольких исключительных ситуаций. В этом случае нужно использовать несколько операторов catch, следующих друг за другом, подобно конструкции с оператором switch. При этом эквивалентом оператора default будет выражение catch(.,,), которое следует понимать как "перехватить все". Отслеживание нескольких возможных исключений показано в листинге 20.2. Листинг 20.2. Множественные исключения 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // конструкторы 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // операторы 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // методы доступа 19: int GetitsSize() const { return itsSize; } 20: 21: //функция-друг 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // определение классов исключений 25: class xBoundary { } ; 26: class xTooBig { } ; 27: class xTooSmall { } ; 28: class xZero { } ; 29: class xNegative { } ; 30: private: 31: int *pType; 32: int itsSize; 33: }; 34: 35: int& Array::operator[](int offSet) 36: { 37: int size = GetitsSize(); 38: if (offSet >= 0J,& offSet < GetitsSize()) 39: return pType[offSet]; 40: throw xBoundary(); 41: return pType[0]; // требование компилятора 42: } 43: 44: 45: const int& Array::operator[](int offSet) const 46: { 47: int mysize = GetitsSize(); 48: if (offSet >= 0 && offSet < GetitsSize()) 49: return pType[offSet] 50: throw xBoundary(); 51: 52: return pType[0]; // требование компилятора 53: } 54: 55: 56: Array::Array(int size): 57: itsSize(size) 58: { 59: if (size == 0) 60: throw xZero(); 61: if (size < 10) 62: throw xTooSmall(); 63: if (size > 30000) 64: throw xTooBig(); 65: if (size < 1) 66: throw xNegative(); 67: 68: pType = new int[size]; 69: for (int i = 0; i<size: i++) 70: pType[i] = 0; 71: } 72: 73: 74: 75: int main() 76: { 77: 78: try 79: { 80: Array intArray(0); 81: for (int j = 0; j< 100; j++) 82: { 83: intArray[j] = ]; 84: cout << "intArray[" << j << "] okay...\n"; 85: } 86: } 87: catch (Array::xBoundary) 88: { 89: cout << "Unable to process your input!\n"; 90: } 91: catch (Array::xTooBig) 92: { 93: cout << "This array is too big...\n"; 94: } 95: catch (Array::xTooSmall) 96: { 97: cout << "This array is too small...\n"; 98: } 99: catch (Array::xZero) 100: { 101: cout << "You asked for an array"; 102: cout << " of zero objects!\n"; 103: } 104: catch (... ) 105: { 106: cout << "Something went wrong!\n"; 107: } 108: cout << "Done.\n"; 109: return 0; 110: } Результат: You asked for an array of zero objects! Done Анализ: В строках 26—29 создается четыре новых класса: xTooBig, xTooSmall, xZero и xNegative. В строках 56—71 проверяется размер массива, переданный конструктору. Если он слишком велик или мал, а также отрицательный или нулевой, генерируется исключение. За блоком try следует несколько операторов catch для каждой исключительной ситуации, кроме исключения, связанного с передачей отрицательного размера. Данное исключение перехватывается оператором catch(. ..) в строке 104. Опробуйте эту программу с рядом значений для размера массива. Затем попытайтесь ввести значение -5. Вы могли бы ожидать, что будет вызвано исключение xNegative, но этому помешает порядок проверок, заданный в конструкторе: проверка size < 10 выполняется до проверки size < 1. Чтобы исправить этот недостаток, поменяйте строки 61 и 62 со строками 65 и 66 и перекомпилируйте программу. Наследование исключенийИсключения — это классы, а раз так, то от них можно производить другие классы. Предположим, что нам нужно создать класс xSize и произвести от него классы xZero, xTooSmall, xTooBig и xNegative. В результате для одних функций можно установить перехват ошибки xSize, а для других — перехват типов ошибок, произведенных от xSize. Реализация этой идеи показана в листинге 20.3. Листинг 20.3. Наследование исключений 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // конструкторы 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // операторы 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // методы доступа 19: int GetitsSize() const { return itsSize; } 20: 21: // функция-друг 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // определения классов исключений 25: class xBoundary { }; 26: class xSize { }; 27: class xTooBig : public xSize { }; 28: class xTooSmall : public xSize { }; 29: class xZero : public xTooSmall { }; 30: class xNegative : public xSize { }; 31: private: 32: int *pType; 33: int itsSize; 34: }; 35: 36: 37: Array::Array(int size): 38: itsSize(size) 39: { 40: if (size — 0) 41: throw xZero(); 42: if (size > 30000) 43: throw xTooBig(); 44: if (size <1) 45: throw xNegative(); 46: if (size < 10) 47: throw xTooSmall(); 48: 49: pType = new int[size]; 50: for (int i = 0; i<size; i++) 51: pType[i] = 0; 52: } 53: 54: int& Array::operator[](int offSet) 55: { 56: int size = GetitsSize(); 57: if (offSet >= 0 && offSet < GetitsSize()) 58: return pType[offSet]; 59: throw xBoundary(); 60: return pType[0]; // требование компилятора 61: } 62: 63: 64: const int&Array::operator[](int offSet) const 65: { 66: int mysize = GetitsSize(); 67: if (offSet >= 0 && offSet < GetitsSize()) 68: return pType[offSet]; 69: throw xBoundary(); 70: 71: return pType[0]; // требование компилятора 72: } 73: 74: int main() 75: { 76: 77: try 78: { 79: Array intArray(0); 80: for (int j = 0; j< 100; j++) 81: { 82: intArray[j ] = j; 83: cout << "intArray[" << j << "] okay...\n"; 84: } 85: } 86: catch (Array::xBoundary) 87: { 88: cout << "Unable to process your input!\n"; 89: } 90: catch (Array::xTooBig) 91: { 92: cout << "This array is too big...\n"; 93: } 94: 95: catch (Array::xTooSmall) 96: { 97: cout << "This array is too small...\n"; 98: } 99: catch (Array::xZero) 100: { 101: cout << "You asked for an array"; 102: cout << " of zero objects!\n"; 103: } 104: 105: 106: catch (.. .) 107: { 108: cout << "Something went wrong!\n"; 109: } 110: cout << "Done.\n"; 111: return 0; 112: } Результат: This array is too small... Done. Анализ: Здесь существенно изменены строки 27—30, где устанавливается иерархия классов. Классы xTooBig, xTooSmall и xNegative произведены от класса xSize, а класс xZero — от класса xTooSmall. Класс Array создается с нулевым размером, но что это значит? Казалось бы, неправильное исключение будет тут же перехвачено! Однако тщательно исследуйте блок catch, и вы поймете, что, прежде чем искать исключение типа xZero, в нем ищется исключение типа xTooSmall. А поскольку возник объект класса xZero, который также является объектом класса xTooSmall, то он перехватывается обработчиком исключения xTooSmall. Будучи уже обработанным, это исключение не передается другим обработчикам, так что обработчик исключений типа xZero никогда не вызывается. Решение этой проблемы лежит в тщательном упорядочении обработчиков таким образом, чтобы самые специфические из них стояли в начале, а более общие следовали за ними. В данном примере для решения проблемы достаточно поменять местами два обработчика — xZero и xTooSmall. Данные в классах исключений и присвоение имен объектам исключенийЧасто для того, чтобы программа могла отреагировать должным образом на ошибку, полезно знать несколько больше, чем просто тип возникшего исключения. Классы исключений — это такие же классы, как и любые другие. Вы абсолютно свободно можете добавлять любые данные в эти классы, инициализировать их с помощью конструктора и считывать их значения в любое время, как показано в листинге 20.4. Листинг 20.4. возвращение данных из объекта исключения 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // конструкторы 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // операторы 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // методы доступа 19: int GetitsSize() const { return itsSize; } 20: 21: // функция-друг 22: friend ostream& operator<< (ostream&, const Array&); 23: 24: // определение классов исключений 25: class xBoundary { }; 26: class xSize 27: { 28: public: 29: xSize(int size):itsSize(size) { } 30: ~xSize(){ } 31: int GetSize() { return itsSize; } 32: private: 33: int itsSize; 34: }; 35: 36: class xTooBig : public xSize 37: { 38: public: 39: xTooBig(int size):xSize(size){ } 40: }; 41: 42: class xTooSmall : public xSize 43: { 44: public: 45: xTooSmall(int size):xSize(size){ } 46: }; 47: 48: class xZero : public xTooSmall 49: { 50: public: 51: xZero(int size):xTooSmall(size){ } 52: }; 53: 54: class xNegative : public xSize 55: { 56: public: 57: xNegative(int size):xSize(size){ } 58: }; 59: 60: private: 61: int *pType; 62: int itsSize; 63: }; 64: 65: 66: Array::Array(int size): 67: itsSize(size) 68: { 69: if (size == 0) 70: throw xZero(size); 71: if (size > 30000) 72: throw xTooBig(size); 73: if (size <1) 74: throw xNegative(size); 75: if (size < 10) 76: throw xTooSnall(size); 77: 78: pType = new int[size]; 79: for (int i = 0; i<size; i++) 80: pType[i] = 0; 81: } 82: 83: 84: int& Array::operator[] (int offSet) 85: { 86: int size = GetitsSize(); 87: if (offSet >= 0 && offSet < GetitsSize()) 88: return pType[offSet]; 89: throw xBoundary(); 90: return pType[0]; 91: } 92: 93: const int&Array::operator[] (int offSet) const 94: { 95: int size = GetitsSize(); 96: if (offSet >= 0 && offSet < GetitsSize()) 97: return pType[offSet]; 98: throw xBoundary(); 99: return pType[0]; 100: } 101: 102: int main() 103: { 104: 105: try 106: { 107: Array intArray(9); 108: for (int j = 0; j< 100; j++) 109: { 110: intArray[j] = j; 111: cout << "intArray[" << j << "] okay..." << endl; 112: } 113: } 114: catch (Array::xBoundary) 115: { 116: cout << "Unable to process your input!\n"; 117: } 118: catch(Array::xZero theException) 119: { 120: cout << "You asked for an Array of zero objectsl " << endl; 121: cout << "Received " << theExesptiQn,GatSize() << endl; 122: } 123: catch (Array:;xTooBig theException) 124: { 125: cout << "This Array is too big,,, " << endl; 126: cout << "Received " << theException,GetSize() << endl; 127: } 128: catch (Array;:xTooSmall theException) 129: { 130: cout << "This Array is too small... " << endl; 131: cout << "Received " << theException.GetSize() << endl; 132: } 133: catch (...) 134: { 135: cout << "Something went wrong, but I've no idea what!\n"; 136: } 137: cout << "Done.\n"; 138: return 0; 139: } Результат: This array is too small... Received 9 Done. Анализ: Объявление класса xSize было изменено таким образом, чтобы включить в него переменную-член itsSize (строкаЗЗ) и функцию-член GetSize() (строка 31). Кроме того, был добавлен конструктор, который принимает целое число и инициализирует переменную-член, как показано в строке 29. Производные классы объявляют конструктор, который лишь инициализирует базовый класс. При этом никакие другие функции объявлены не были (частично из экономии места в листинге). Операторы catch в строках 114-136 изменены таким образом, чтобы создавать именованный объект исключения (thoException), который используется в теле блока catch для доступа к данным, сохраняемым в переменной-члене itsSize. Примечание:При работе с исключениями следует помнить об их сути: если уж оно возникло, значит, что-то не в порядке с распределением ресурсов, и обработку этого исключения нужно записать таким образом, чтобы вновь не создать ту же проблему. Следовательно, если вы создаете исключение OutOfMemory, то не стоит а конструкторе этого класса пытаться выделить память для какого-либо объекта. Весьма утомительно писать вручную все эти конструкции с операторами oatch, каждый из которых должен выводить свое сообщение. Тем более, что при увеличении объема программы стремительно возрастает вероятность возникновения в ней ошибок. Лучше переложить эту работу на объект исключения, который сам должен определять тип исключения и выбирать соответствующее сообщение. В листинге 20.5 для решения этой проблемы использован подход, который в большей степени отвечает принципам объектно-ориентированного программирования. В классах исключений применяются виртуальные функции, обеспечивающие полиморфизм объекта исключения. Листинг 20.5. Передача аргументов как ссылок u использование виртуальных функций в классах исключений 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: 5: class Array 6: { 7: public: 8: // конструкторы 9: Array(int itsSize = DefaultSize); 10: Array(const Array &rhs); 11: ~Array() { delete [] pType;} 12: 13: // операторы 14: Array& operator=(const Array&); 15: int& operator[](int offSet); 16: const int& operator[](int offSet) const; 17: 18: // методы доступа 19: int GetitsSize() const { return itsSize; } 20: 21: // функция-друг 22: friend ostream& operator<< 23: (ostream&, const Array&); 24: 25: // определение классов исключений 26: class xBoundary { }; 27: class xSize 28: { 29: public: 30: xSize(int size):itsSize(size) { } 31: ~xSize(){ } 32: virtual int GetSize() { return itsSize; } 33: virtual void PrintError() 34: { 35: cout << "Size error. Received: "; 36: cout << itsSize << endl; 37: } 38: protected: 39: int itsSize; 40: }; 41: 42: class xTooBig : public xSize 43: { 44: public: 45: xTooBig(int size):xSize(size){ } 46: virtual void PrintError() 47: { 48: cout << "Too big. Received: "; 49: cout << xSize::itsSize << endl; 50: } 51: }; 52: 53: class xTooSmall : public xSize 54: { 55: public: 56: xTooSmall(int size):xSize(size){ } 57: virtual void PrintError() 58: { 59: cout << "Too small. Received: "; 60: cout << xSize::itsSize << endl; 61: } 62: }; 63: 64: class xZero : public xTooSmall 65: { 66: public: 67: xZero(int size):xTooSmall(size){ } 68: virtual void PrintError() 69: { 70: cout << "Zero!. Received: " ; 71: cout << xSize::itsSize << endl; 72: } 73: }; 74: 75: class xNegative : public xSize 76: { 77: public: 78: xNegative(int size):xSize(size){ } 79: virtual void PrintError() 80: { 81: cout << "Negative! Received: "; 82: cout << xSize::itsSize << endl; 83: } 84: }; 85: 86: private: 87: int *pType; 88: int itsSize; 89: }; 90: 91: Array::Array(int size): 92: itsSize(size) 93: { 94: if (size == 0) 95: throw xZero(size); 96: if (size > 30000) 97: throw xTooBig(size); 98: if (size <1) 99: throw xNegative(size); 100: if (size < 10) 101: throw xTooSmall(size); 102: 103: pType = new int[size]; 104: for (int i = 0: i<size; i++) 105: pType[i] = 0; 106: } 107: 108: int& Array::operator[] (int offSet) 109: { 110: int size = GetitsSize(); 111: if (offSet >= 0 && offSet < GetitsSize()) 112: return pType[offSet]; 113: throw xBoundary(); 114: return pType[0]; 115: } 116: 117: const int& Array::operator[] (int offSet) const 118: { 119: int size = GetitsSize(); 120: if (offSet >= 0 && offSet < GetitsSize()) 121: return pType[offSet]; 122: throw xBoundary(); 123: return pType[0]; 124: } 125: 126: int main() 127: { 128: 129: try 130: { 131: Array intArray(9); 132: for (int j = 0: j< 100; j++) 133: { 134: intArray[j] - j; 135: cout << "intArray[" << j << "] okay...\n"; 136: } 137: } 138: catch (Array::xBoundary) 139: { 140: cout << "Unable to process your input!\n"; 141: } 142: catch (Array;:xSize& theExoeption) 143: { 144: theException.PrintError(); 145: } 146: catch (...) 147: { 148: cout << "Something went wrong!\n"; 149: } 150: cout << "Done.\n"; 151: return 0; 152: } Результат: Too small! Received: 9 Done. Анализ: В листинге 20.5 показано объявление виртуального метода PrintError() в классе xSize, который выводит сообщения об ошибках и истинный размер класса. Этот метод замешается в каждом производном классе исключения. В строке 142 объявляется объект исключения, который является ссылкой. При вызове функции PrintError() со ссылкой на объект благодаря полиморфизму вызывается нужная версия функции PrintError(). В результате программный код становится яснее, проще для понимания, а следовательно, и для дальнейшей поддержки. Исключения и шаблоныПри создании исключений, предназначенных для работы с шаблонами, есть два варианта решений. Можно создавать исключение прямо в шаблоне, и тогда они будут доступны для каждого экземпляра шаблона, а можно использовать классы исключений, созданные вне объявления шаблона. Оба этих подхода показаны в листинге 20.6. Листинг 20.6. Использование исключений с шаблонами 1: #include <iostream.h> 2: 3: const int DefaultSize = 10; 4: class xBoundary { } ; 5: 6: template <class T> 7: class Array 8: { 9: public: 10: // конструкторы 11: Array(int itsSize = DefaultSize); 12: Array(const Array &rhs); 13: ~Array() { delete [] pType;} 14: 15: // операторы 16: Array& operator=(const Array<T>&); 17: T& operator[](int offSet); 18: const T& operator[](int offSet) const; 19: 20: // методы доступа 21: int GetitsSize() const { return itsSize; } 22: 23: // функция-друг 24: friend ostream& operator<< (ostream&, const Array<T>&); 25: 26: // определение классов исключений 27: 28: class xSize { }; 29: 30: private: 31: int *pType; 32: int itsSize; 33: }; 34: 35: template <class T> 36: Array<T>::Array(int size): 37: itsSize(size) 38: { 39: if (size <10 || size > 30000) 40: throw xSize(); 41: рТуре = new T[size]; 42: for (int i = 0; i<size; i++) 43: pType[i] = 0; 44: } 45: 46: template <class T> 47: Array<T>& Array<T>::operator=(const Array<T> &rhs) 48: { 49: if (this == &rhs) 50: return *this; 51: delete [] рТуре; 52: itsSize = rhs.GetitsSize(); 53: рТуре = new T[itsSize]; 54: for (int i = 0; i<itsSize; i++) 55: pType[i] = rhs[i]; 56: } 57: template <class T> 58: Array<T>::Array(const Array<T> &rhs) 59: { 60: itsSize = rhs.GetitsSize(); 61: рТуре = new T[itsSize]; 62: for (int i = 0; i<itsSize; i++) 63: pType[i] = rhs[i]; 64: } 65: 66: template <class T> 67: T& Array<T>::operator[](int offSet) 68: { 69: int size = GetitsSize(); 70: if (offSet >= 0 && offSet < GetitsSize()) 71: return pType[offSet]; 72: throw xBoundary(): 73: return pType[0]; 74: } 75: 76: template <class T> 77: const T& Array<T>::operator[](int offSet) const 78: { 79: int mysize = GetitsSize(); 80: if (offSet >= 0 && offSet < GetitsSize()) 81: return pType[offSet]; 82: throw xBoundary(); 83: } 84: 85: template <class T> 86: ostream& operator<< (ostream& output, const Array<T>& theArray) 87: { 88: for (int i = 0; i<theArray,GetitsSize(); i++) 89: output << "[" << i << "] " << theArray[i] << endl; 90: return output; 91: } 92: 93: 94: int main() 95: { 96: 97: try 98: { 99: Array<int> intArray(9); 100: for (int j = 0; j< 100; j++) 101: { 102: intArray[j] = j; 103: cout << "intArray[" << j << "] okay..." << endl; 104: } 105: } 106: catch (xBoundary) 107: { 108: cout << "Unable to process your input!\n"; 109: } 110: catch (Array<int>::xSize) 111: { 112: cout << "Bad Size!\n"; 113: } 114: 115: cout << "Done.\n"; 116: return 0; 117: } Результат: You asked for an array of zero objects! Done Анализ: Первое исключение, xBoundary, объявлено вне определения шаблона в строке 4; второе исключение, xSize, — внутри определения шаблона в строке 28. Исключение xBoundary не связано с классом шаблона, но его можно использовать так же, как и любой другой класс. Исключение xSize связано с шаблоном и должно вызываться для экземпляра класса Array. Обратите внимание на разницу в синтаксисе двух операторов catch. Строка 106 содержит выражение catch (xBoundary), а строка 110 — выражение catch (Array<int>::xSize). Второй вариант связан с обращением к исключению экземпляра целочисленного массива. Исключения без ошибокКогда программисты C++ после работы собираются за чаркой виртуального пива в баре киберпространства, в их задушевных беседах часто затрагивается вопрос, можно ли использовать исключения не только для отслеживания ошибок, но и для выполнения рутинных процедур. Есть мнение, что использование исключений следует ограничить только отслеживанием предсказуемых исключительных ситуаций, для чего, собственно, исключения и создавались. В то же время другие считают, что исключения предоставляют эффективный способ возврата сквозь несколько уровней вызовов функций, не подвергаясь при этом опасности утечки памяти. Чаще всего приводится следующий пример. Пользователь формирует запрос на некоторую операцию в среде GU1 (графический интерфейс пользователя). Часть кода, которая перехватывает этот запрос, должна вызвать функцию-член менеджера диалоговых окон, которая, в свою очередь, вызывает код, обрабатывающий этот запрос. Этот код вызывает другой код, который решает, какое диалоговое окно использовать, и, в свою очередь, вызывает код, чтобы отобразить на экране это диалоговое окно. И теперь уже этот код наконец-то вызывает другой код, который обрабатывает данные, вводимые пользователем. Если пользователь щелкнет на кнопке Cancel (Отменить), код должен возвратиться к самому первому вызывающему методу, где обрабатывался первоначальный запрос. Один подход к решению этой проблемы состоит в том, чтобы поместить блок try сразу за тем блоком программы, где формируется исходный запрос, и перехватывать объект исключения CancelDialog, который генерируется обработчиком сообщений для кнопки Cancel. Это безопасно и эффективно, хотя щелчок на кнопке Cancel по сути своей не относится к исключительной ситуации. Чтобы решить, насколько правомочно такое использование исключений, попытайтесь ответить на следующие вопросы: станет ли в результате программа проще или, наоборот, труднее для понимания; действительно ли уменьшится риск возникновения ошибок и утечки памяти; труднее или проще теперь станет поддержка такой программы? Безусловно, объективно ответить на эти вопросы сложно: многое зависит от привычек и субъективных взглядов программиста, из-за чего, кстати, и возникают споры вокруг этих вопросов. Ошибки и отладка программыПочти все современные среды разработки содержат один или несколько встроенных эффективных отладчиков. Основная идея использования отладчика такова: отладчик загружает и выполняет исходный код программы в режиме, удобном для отслеживания выполнения отдельных строк программы и выявления ошибок. Все компиляторы позволяют компилировать программы с использованием символов или без них. Компилирование с символами указывает компилятору на необходимость установки взаимосвязей между исходным кодом файлов источников и сгенерированной программой, благодаря чему отладчик может указать на строку исходного кода, которая соответствует следующему действию в вашей программе. Полноэкранные символьные отладчики превосходно справляются с этой сложной работой. После загрузки отладчик считывает весь исходный код программы и отображает его в окне. Отладчик позволяет проходить в пошаговом режиме через все строки программы в порядке их выполнения. При работе с большинством отладчиков можно переключаться между исходным кодом и выводом на экран, чтобы видеть результаты выполнения каждой команды. Полезной также является возможность определения текущего значения любой переменной, в том числе переменных-членов классов и значений в ячейках области динамического обмена, на которые ссылаются указатели программы, а также просмотр сложных структур данных. Отладчики предоставляют ряд утилит, позволяющих устанавливать в коде программы точки останова, выводить контрольные значения переменных, исследовать особенности распределения памяти и просматривать код ассемблера. Точка остановаТочки останова — это команды, предназначенные для отладчика и означающие, что программа должна остановиться перед выполнением указанной строки. Это средство позволяет экономить время при отладке, выполняя программу в обычном режиме до того места, где установлена точка останова. После остановки выполнения программы можно проанализировать текущие значения переменных или продолжить работу программы в пошаговом режиме. Анализ значений переменныхМожно указать отладчику на отображение значения конкретной переменной или на останов программы, когда заданная переменная будет читаться или записываться. Отладчик даже позволяет изменить значение переменной в процессе выполнения программы. Исследование памятиВремя от времени важно просматривать реальные значения, содержащиеся в памяти. Современные отладчики могут отображать эти значения в понятном для пользователя виде, т.е. строки отображаются как символы, а числовые значения — как десятичные цифры, а не в двоичном коде. Современные отладчики C++ могут даже показывать целые классы с текущими значениями всех переменных-членов, включая указатель this. Код ассемблераХотя чтения исходного кода иногда бывает достаточно для обнаружения ошибки, тем не менее можно указать отладчику на отображение реального кода ассемблера, сгенерированного для каждой строки исходного кода. Вы можете просмотреть значения регистраторов памяти и флагов и при желании настолько углубиться в дебри машинного кода, насколько нужно. Научитесь пользоваться своим отладчиком. Это может оказаться самым мощным оружием в вашей священной войне с ошибками. Ошибки выполнения программы считаются наиболее трудными для поиска и устранения, и мощный отладчик в состоянии помочь вам в этом. РезюмеСегодня вы узнали, как создавать и использовать исключения, т.е. объекты, которые могут быть созданы в тех местах программы, где исполняемый код не может обработать ошибку или другую исключительную ситуацию, возникшую во время выполнения программы. Другие части программы, расположенные выше в стеке вызовов, выполняют блоки catch, которые перехватывают исключение и отвечают на возникшую исключительную ситуацию соответствующим образом. Исключения — это нормальные созданные пользователем объекты, которые можно передавать в функции как значения или как ссылки. Они могут содержать данные и методы, а блок catch может использовать эти данные, чтобы определить, как справиться с возникшими проблемами. Можно создать конструкции из нескольких блоков catch, но следует учитывать, что, как только исключение будет перехвачено отдельным оператором catch, оно не будет передаваться последующим блокам catch. Очень важно правильно упорядочить блоки catch, чтобы специфические блоки стояли выше более общих блоков. На этом занятии также рассматривались некоторые основные принципы работы символьных отладчиков, включая использование таких средств, как точки останова, анализ значений переменных и т.д. Эти средства позволяют выполнить останов программы в той части, которая вызывает появление ошибки, и просмотреть значения переменных в ходе программы. Вопросы и ответыЗачем тратить время на программирование исключений? Не лучше ли устранять ошибки по мере их возникновения? Часто одна и та же ошибка может возникать при выполнении разных функций программы. Использование исключений позволяет собрать коды отслеживания ошибок в одном месте программы. Кроме того, далеко не всегда возможно вписать код устранения ошибки в том месте программы, где эта ошибка возникает. Зачем создавать исключения как объекты? Не проще ли записать код устранения ошибки? Объекты более гибки и универсальны в использовании, чем обычные программные блоки. С объектами можно передать больше информации и снабдить конструктор и деструктор класса исключения функциями устранения возникшей ошибки. Почему бы не использовать исключения не только для отслеживания исключительных ситуаций, но и для выполнения рутинных процессов? Разве не удобно использовать исключения для быстрого и безопасного возвращения по стеку вызовов к исходному состоянию программы? Безусловно, и многие программисты на C++ используют исключения именно в этих целях. Но следует помнить, что прохождение исключения по стеку вызовов может оказаться не таким уж безопасным. Так, если объект был создан в области динамического обмена, а потом удален в стеке вызовов, это может привести к утечке памяти. Впрочем, при тщательном анализе программы и использовании современного компилятора эту проблему можно предупредить. Кроме того, многие программисты считают, что использование исключений не по прямому назначению делает программу слишком запутанной и нелогичной. Всегда ли следует перехватывать исключения сразу за блоком try, генерирующим это исключение? Нет, в стеке вызовов перехват исключения может осуществляться в любом месте, после чего стек вызовов будет пройден то того места, где происходит обработка исключения. Зачем использовать утилиту отладки, если те же функции можно осуществлять прямо во время компиляции с помощью объекта cout и условного выражения #ifdef debug? В действительности утилита отладки предоставляет значительно больше средств и возможностей, таких как пошаговое выполнение программы, установка точек останова и анализ текущих значений переменных. При этом вам не приходится перегружать свой код многочисленными командами препроцессора и выражениями, которые никак не связаны с основным назначением программы. КоллоквиумВ этом разделе предлагаются вопросы для самоконтроля и укрепления полученных знаний, а также ряд упражнений, которые помогут закрепить ваши практические навыки. Попытайтесь самостоятельно ответить на вопросы теста и выполнить задания, а потом сверьте полученные результаты с ответами в приложении Г. Не приступайте к изучению материала следующей главы, если для вас остались неясными хотя бы некоторые из предложенных ниже вопросов. Контрольные вопросы1. Что такое исключение? 2. Для чего нужен блок try? 3. Для чего используется оператор catch? 4. Какую информацию может содержать исключение? 5. Когда создается объект исключения? 6. Следует ли передавать исключения как значения или как ссылки? 7. Будет ли оператор catch перехватывать производные исключения, если он настроен на базовый класс исключения? 8. Если используются два оператора catch, один из которых настроен на базовое сообщение, а второй — на производное, то в каком порядке их следует расположить? 9. Что означает оператор catch(...)? 10. Что такое точка останова? Упражнения1. Запишите блок try и оператор catch для отслеживания и обработки простого исключения. 2. Добавьте в исключение, полученное в упражнении 1, переменную-член и метод доступа и используйте их в блоке оператора catch. 3. Унаследуйте новое исключение от исключения, полученного в упражнении 2. Измените блок оператора catch таким образом, чтобы в нем происходила обработка как производного, так и базового исключений. 4. Измените код упражнения 3, чтобы получить трехуровневый вызов функции. 5. Жучки: что не правильно в следующем коде? #include "string" //класс строк сlass xOutOfMemory { public: xOutOfMemory(){ theMsg = new сhar[20]; strcpy(theMsg, "trror in momory");} ~xOutOfMemory(){ delete [] theMsg; cout << "Memory restored, " << endl; } char * Message() { return theMsg; } private: char >> theMsg; }; main() { try { char * var = new char; if ( var == 0 ) { xOutOfMemory * px = new xOutOfMemory; throw px; } } catch( xOutOfMemory * theException ) { cout << theException->Message() <<endl; delete theException; } return 0; } 6. Данный пример содержит потенциальную ошибку, подобную возникающей при попытке выделить память для показа сообщения об ошибке в случае обнаружения нехватки свободной памяти. Вы можете протестировать эту программу, изменив строку if (var == 0) на if (1), которая вызовет создание исключения. День 21-й. Что дальшеПримите наши поздравления! Вы почти завершили изучение полного трехнедельного интенсивного курса введения в C++. К этому моменту у вас должно быть ясное понимание языка C++, но в современном программировании всегда найдутся еще не изученные области. В этой главе будут рассмотрены некоторые опущенные выше подробности, а затем намечен курс для дальнейшего освоения C++. Большая часть кода файлов источника представлена командами на языке C++. Компилятор превращает этот код в программу на машинном языке. Однако перед запуском компилятора запускается препроцессор, благодаря чему можно воспользоваться возможностями условной компиляции. Итак, сегодня вы узнаете: • Что представляет собой условная компиляция и как с ней обращаться • Как записывать макросы препроцессора • Как использовать препроцессор для обнаружения ошибок • Как управлять значениями отдельных битов и использовать их в качестве флагов • Какие шаги следует предпринять для дальнейшего эффективного изучения C++ Процессор и компиляторПри каждом запуске компилятора сначала запускается препроцессор, который ищет команды препроцессора, начинающиеся с символа фунта (#). При выполнении любой из этих команд в текст исходного кода вносятся некоторые изменения, в результате чего создается новый файл исходного кода. Этот новый файл является временным, и вы обычно его не видите, но можете дать команду компилятору сохранить его для последующего просмотра и использования. Компилятор читает не исходный файл источника, а результат работы препроцессора и компилирует его в исполняемый файл программы. Вам уже приходилось встречаться с директивой препроцессора #include: она предписывает найти файл, имя которого следует за ней, и вставить текст этого файла по месту вызова. Этот эффект подобен следующему: вы полностью вводите данный файл прямо в свою исходную программу, причем к тому времени, когда компилятор получит исходный код, файл будет уже на месте. Просмотр промежуточного файлаПочти каждый компилятор имеет ключ, который можно устанавливать или в интегрированной среде разработки, или в командной строке. С помощью этого ключа можно сообщить компилятору о том, что вы хотите сохранить промежуточный файл. Если вас действительно интересует содержимое этого файла, обратитесь к руководству по использованию компилятора, чтобы узнать, какие ключи можно для него устанавливать. Использование директивы #defineКоманда #define определяет строку подстановки. Строка #define BIG 512 означает, что вы предписываете препроцессору заменять лексему BIG строкой 512 в любом месте программы. Эта запись не является командой языка C++. Строка 512 вставляются в исходную программу везде, где встречается лексема BIG. Лексема — это строка символов, которую можно применить там, где может использоваться любая строка, константа или какой-нибудь другой набор символов. Таким образом, при записи строк #define BIG 512 int myArray[BIG]; промежуточный файл, создаваемый препроцессором, будет иметь такой вид: int myArray[512]; Обратите внимание, что в коде исчезла команда #define. Из промежуточного файла все директивы препроцессора удаляются, поэтому они отсутствуют в конечном варианте кода источника. Использование директивы #define для создания константОдин вариант использования директивы #define - это создание констант. Однако этим не стоит злоупотреблять, поскольку директива #define просто выполняет замену строки и не осуществляет никакого контроля за соответствием типов. Как пояснялось на занятии, посвященном константам, гораздо безопаснее вместо директивы #define использовать ключевое слово const. Использование директивы #define для тестированияВторой способ использования директивы #define состоит в простом объявлении того, что данная лексема определена в программе. Например, можно записать следующее: #define BIG В программе можно проверить, была ли определена лексема BIG, и предпринять соответствующие меры. Для подобной проверки используются такие команды препроцессора, как #ifdef (если определена) и #ifndef (если не определена). За обеими командами должна следовать команда #endif, которую необходимо установить до завершения блока (до следующей закрывающей фигурной скобки). Директива #ifdef принимает значение, равное истине, если тестируемая лексема уже была определена. Поэтому можем записать следующее: #ifdef DEBUG cout << "Строка DEBUG определена"; #endif Когда препроцессор читает директиву #ifdef, он проверяет построенную им самим таблицу, чтобы узнать, была ли уже определена в программе лексема DEBUG. Если да, то #ifdef возвращает значение true, и все, что находится до следующей директивы #else или #endif, записывается в промежуточный файл для компиляции. Если эта директива возвращает значение false, то ни одна строка кода, находящаяся между директивами #ifdef DEBUG и #endif, не будет записана в промежуточный файл, т.е. вы получите такой вариант промежуточного файла, как будто этих строк никогда и не было в исходном коде. Обратите внимание, что директива #ifndef является логической противоположностью директивы #ifdef. Директива #ifndef возвращает true в том случае, если до этой точки в программе заданная лексема не была определена. Комманда препроцессора #elseКак вы правильно предположили, директиву #else можно вставить между #ifdef (или #ifndef) и завершающей директивой #endif. Использование этих директив показано в листинге 21.1. Листинг 21.1. Использование директивы #define 1: #define DemoVersion 2: #define NT_VERSION 5 3: #include <iostream.h> 4: 5: 6: int main() 7: { 8: 9: cout << "Checking on the definitions of DemoVersion, NT_VERSION _and WINDOWS_VERSION...\n"; 10: 11: #ifdef DemoVersion 12: cout << "DemoVersion defined.\n"; 13: #else 14: cout << "DemoVersion not defined.\n"; 15: #endif 16: 17: #ifndef NT_VERSION 18: cout << "NT_VERSION not defined!\n"; 19: #else 20: cout << "NT_VERSION defined as: " << NT_VERSION << endl; 21: #endif 22: 23: #ifdef WINDOWS_VERSION 24: cout << "WINDOWS_VERSION definod!\n"; 25: #else 26: cout << "WINDOWS_VERSION was nol: do1inod.\n"; 27: #endif 28: 29: cout << "Done.\n"; 30: return 0; 31: } Результат: hecking on the definitions of DemoVersion, NT_VERSION_and WINDOWS_VERSION... DemoVersion defined. NT_VERSION defined as: 5 WINDOWS_VERSION was not defined. Done. Анализ: В строках 1 и 2 определяются лексемы DemoVersion и NT_VERSION, причем лексеме NT_VERSION назначается литерал 5. В строке 11 проверяется определение лексемы DemoVersion, а поскольку она определена (хотя и без значения), то результат тестирования принимает истинное значение и строка 12 выводит соответствующее сообщение. В строке 17 определенность лексемы NT_VERSION проверяется с помощью директивы #ifndef. Поскольку данная лексема определена, возвращается значение false и выполнение программы продолжается со строки 20. Именно здесь слово NT_VERSION заменяется символом 5, т.е. компилятор воспринимает эту строку кода в следующем виде: cout << " NT_VERSION defined as: " << 5 << endl: Обратите внимание, что первое слово в сообщении NT_VERSION не замещается строкой 5, поскольку является частью текстовой строки, заключенной в кавычки. Но лексема NT_VERSION между операторами вывода замешается; таким образом, компилятор видит вместо нее символ 5, точно так же, как если бы вы ввели этот символ в выражение вывода. Наконец, в строке 23 программа проверяет определенность лексемы WIND0WS_VERSI0N. Поскольку эта лексема в программе не определена, возвращается значение false и строкой 26 выводится соответствующее сообщение. Включение файлов и предупреждение ошибок включенияВы обязательно будете создавать проекты, состоящие из нескольких различных файлов. Традиционно в проектах приложения каждый класс имеет собственный файл заголовка с объявлением класса (обычно такие файлы имеют расширение .hpp) и файл источника с кодом выполнения методов класса (обычно с расширением .cpp). Функцию main() программы помещают в свой собственный файл .cpp, а все файлы .cpp компилируются в файлы .obj, которые затем компоновщик связывает в единую программу. Поскольку программы обычно используют методы из многих классов, основной файл программы будет содержать включения многих файлов заголовков. Кроме того, файлы заголовков часто включают в себя другие файлы заголовков. Например, файл заголовка с объявлением производного класса должен включить файл заголовка базового класса. Представьте себе, что класс Animal объявляется в файле ANIMAL.hpp. Чтобы объявить класс Dog (который производится от класса Animal), следует в файл DOG.HPP включить файл ANIMAL.hpp, в противном случае класс Dog нельзя будет произвести от класса Animal. Файл заголовка Cat также включает файл ANIMAL.hpp по той же причине. Если существует метод, который использует оба класса — Cat и Dog, то вы столкнетесь с опасностью двойного включения файла ANIMAL.hpp. Это сгенерирует ошибку в процессе компиляции, поскольку компилятор не позволит дважды объявить класс Animal, даже несмотря на идентичность объявлений. Эту проблему можно решить с помощью директив препроцессора. Код файла заголовка ANIMAL необходимо заключить между следующими директивами: #ifndef ANIMAL_HPP #define ANIMAL_HPP ... // далее следует код файла заголовка #endif Эта запись означает: если лексема ANIMAL_HPP еще не определена в программе, продолжайте выполнение кода, следующая строка которого определяет эту лексему. Между директивой #define и директивой завершения блока условной компиляции #endif включается содержимое файла заголовка. Когда ваша программа включает этот файл в первый раз, препроцессор читает первую строку и результат проверки, конечно же, оказывается истинным, т.е. до этого момента лексема еще не была определена как ANIMAL_HPP. Следующая директива препроцессора #define определяет эту лексему, после чего включается код файла. Если программа включает файл ANIMAL,HPP во второй раз, препроцессор читает первую строку, которая возвращает значение FALSE, поскольку строка ANIMAL.hpp уже была определена. Поэтому управление программой переходит к следующей директиве — #else (в данном случае таковая отсутствует) или #endif (которая находится в конце файла). Следовательно, в этот раз пропускается все содержимое файла и класс дважды не объявляется. Совершенно не важно реальное имя лексемы (в данном случае ANIMAL_HPP), хотя общепринято использовать имя файла, записанное прописными буквами, а точка (.), отделяющая имя от расширения, заменяется при этом символом подчеркивания. Однако это не закон, а общепринятое соглашение, которое следует рассматривать лишь как рекомендацию. Примечание:Никогда не повредит использовать средства защиты от многократного включения. Нередко они способны сэкономить часы работы, потраченные на поиск ошибок и отладку программы. МакросыДирективу #define можно также использовать дгш создания макросов. Макрос — это лексема, созданная с помощью директивы #define. Он принимает параметры подобно обычной функции. Препроцессор заменяет строку подстановки любым заданным параметром. Например, макрокоманду TWICE можно определить следующим образом: #define TWICE(x) ( (x) * 2 ) А затем в программе можно записать следующую строку: TWICE(4) Целая строка TWICE(4) будет удалена, а вместо нее будет стоять значение 8! Когда препроцессор считывает параметр 4, он выполняет следующую подстановку: ((4) * 2), это выражение затем вычисляется как 4 * 2 и в результате получается число 8. Макрос может иметь больше одного параметра, причем каждый параметр в тексте замены может использоваться неоднократно. Вот как можно определить два часто используемых макроса — МАХ и MIN: #define MAX(x,y) ( (x) > (у) ? (x) : (у) ) #define MIN(x,y) ( (x) < (у) ? (x) : (у) ) Обратите внимание, что в определении макроса открывающая круглая скобка для списка параметров должна немедленно следовать за именем макроса, т.е. между ними не должно быть никаких пробелов. Препроцессор, в отличие от компилятора, не прощает присутствия ненужных пробелов. Если записать #define MAX (x,y) ( (x) > (у) ? (x) : (у) ) и попытаться использовать макрос МАХ int x = 5, у = 7, z; z = MAX(x,y); то промежуточный код будет иметь следующий вид: int x = 5, у = 7, z; z = (x,y) ( (x) > (у) ? (x) : (у) )(x,y) В этом случае сделана простая текстовая замена, а не вызов макроса, т.е. лексема МАХ была заменена выражением (x,y) ( (x) > (у) ? (x) : (у) ),за которым сохранилась строка (x, у). Однако после удаления пробела между словом МАХ и списком параметров (x,y) промежуточный код выглядит уже по-другому: int x = 5, у = 7, z; z =7; Зачем нужны все эти круглые скобкиВам может показаться странным, что в макросах используется так много круглых скобок. На самом деле препроцессор совсем не требует, чтобы вокруг параметров в строке подстановки ставились круглые скобки, но эти скобки помогают избежать нежелательных побочных эффектов при передаче макросу сложных значений. Например, если определить МАХ как #define MAX(x,y) x > у ? x : у и передать значения 5 и 7, то макрос МАХ будет нормально работать. Но если передать более сложные выражения, можно получить неожиданные результаты, как показано в листинге 21.2. Листинг 21.2. Использование в макросе круглых скобок 1: // Листинг 21.2. Использование в макросе круглых скобок 2: #include <iostream.h> 3: 4: #define CUBE(a) ( (а) * (а) << (а) ) 5: #define THREE(a) а * а * а 6: 7: int main() 8: { 9: long x = 5; 10: long у = CUBE(x); 11: long z = THREE(x); 12: 13: cout << "у: " << у << endl; 14: cout << "z: " << z << endl; 15: 16: long а = 5, b = 7; 17: у = CUBE(a+b); 18: z = THREE(a+b); 19: 20: cout << "у: " << у << endl; 21: cout << "z: " << z << endl; 22: return 0; 23: } Результат: у: 125 z: 125 у: 1728 z: 82 Анализ: В строке 4 определяется макрос CUBE с параметром x, который заключается в круглые скобки при каждом его использовании в выражении. В строке 5 определяется макрос THREE, параметр которого используется без круглых скобок. При первом использовании этих макросов параметру передается значение 5, и оба макроса прекрасно справляются со своей работой. Макрос CUBE(5) преобразуется в выражение ( (5) * (5) * (5) ), которое при вычислении дает значение 125, а макрос THREE(5) преобразуется в выражение 5 * 5 * 5, которое также возвращает значение 125. При повторном обращении к этим макросам в строках 16—18 параметру передается выражение 5 + 7. В этом случае макрос CUBE(5+7) преобразуется в следующее выражение: ( (5+7) * (5+7) * (5+7) ) Оно соответствует выражению ( (12) * (12) * (12) ) При вычислении этого выражения получаем значение 1728. Однако макрос THREE(5+7) преобразуется в выражение иного вида: 5 + 7 * 5 + 7 * 5 + 7 А поскольку операция умножения имеет более высокий приоритет по сравнению с операцией сложения, то предыдущее выражение эквивалентно следующему: 5 + (7 * 5) + (7 * 5) + 7 После вычисления произведений в круглых скобках получаем выражение 5 + (35) + (35) + 7 После суммирования оно возвращает значение 82. Макросы в сравнении с функциями шаблоновПри работе с макросами и языке C++ можно столкнуться с четырьмя проблемами. Первая состоит в возможных неудобствах при увеличении самого выражения макроса, поскольку любой макрос должен быть определен в одной строке. Безусловно, эту строку можно продлить с помощью символа обратной косой черты (\), но большие макросы сложны для понимания и с ними трудно работать. Вторая проблема состоит в том, что макросы выполняются путем подстановки их выражений в код программы при каждом вызове. Это означает, что если макрос используется 12 раз, то столько же раз н вашу программу будет вставлено соответствующее выражение (вместо одного раза, как при обращении к обычной функции). Хотя, с другой стороны, подставляемые выражения обычно работают быстрее, чем вызовы функций, поскольку не тратится время па само обращение к функции. Тот факт, что макросы выполняются путем подстановки выражений в код программы, приводит к третьей проблеме, которая проявляется в том, что макросы отсутствуют в исходном коде программы, используемом компилятором для ее тестирования. Это может существенно затруднить отладку программы. Однако наиболее существенна последняя проблема: в макросах не поддерживается контроль за соответствием типов данных. Хотя возможность использования в макросе абсолютно любого параметра кажется удобной, этот факт полностью подрывает строгий контроль типов в C++ и является проклятием для программистов на C++. Конечно, существует корректный способ решить и эту проблему — нужно воспользоваться услугами шаблонов, как было показано на занятии 19. Подставляемые функцииЧасто вместо макросов удобно объявить подставляемую функцию. Например, в листинге 21.3 создается функция CUBE, которая выполняет ту же работу, что и макрос CUBE в листинге 21.2, но в данном случае это делается способом, обеспечивающим контроль за соответствием типов. Листинг 21.3. Использование подставляемой функции вместо макроса 1: #include <iostream.h> 2: 3: inline unsigned long Square(unsigncd long а) { return а * а; } 4: inline unsigned long Cubo(unsigned long а) 5: { return а * а * а; } 6: int main() 7: { 8: unsigned long x=1 ; 9: for (;;) 10: { 11: cout << "Enter а number (0 to quit): "; 12: cin >> x; 13: if (x == 0) 14: break; 15: cout << "You entered: " << x; 16: cout << ". Square(" << x << "): "; 17: cout << Square(x); 18: cout<< ". Cube(" << x << "): "; 19: cout << Cube(x) << "." << endl; 20: } 21: return 0; 22: } Результат: Enter а number (0 to quit) 1 You ent.erod: 1. Square(1) 1. Cube(1): 1. Enter а number (0 t.o quit) 2 You entered: 2. Square(2) 4. Cube(2): 8 Enter a number (0 t.o quit.) 3 You enlered: 3. Square(3) 9. Cube(3): 27. Enter a number (0 to quit) 4 You entered: 4. Squate(4) 16 Cube(4) 64. Enter a number (0 to quit) 5 You entered: 5, Squate(5) 25 Cubo(5) 125 Enter a number (0 to qu.it) 6 You entered: 6. Squaro(6) 36 Cube(6) 216 Enter a number (0 to quit) 0 Анализ: В строках 3 и 4 определяются две подставляемые функции: Square() и Cube(). Поскольку обе функции объявлены подставляемыми с помошью ключевого слова inlino, они, как и макросы, будут вставлены в код программы по месту каждого вызова, и никаких временных затрат при выполнении программы, связанных с обращениями к функциям, не возникнет. Напомним, что подставляемые функции помещаются во время компиляции в программу всюду, где делается обращение к функции (например, в строке 17). А поскольку реального вызова функции никогда не происходит, отсутствуют и временные затраты, связанные с помещением в стек адреса возврата и параметров функции. В строке 17 вызывается функция Square, а в строке 19 — функция Cube. И вновь-таки, поскольку эти функции подставляемые, реально строка их вызова после компиляции будут выглядеть следующим образом: 16: cout << ". Square(" << x << "): " << x * x << ". Cube (" << x << "): " << x * x * x << "." << endl; Операции со строкамиПрепроцессор предоставляет два специальных оператора для управления строками в макросах. Оператор взятия в кавычки (#) берет в кавычки любую строку, которая следует за ним. Оператор конкатенации (##) объединяет две строки в одну. Оператор взятия в кавычкиЭтот оператор берет в кавычки любые следующие за ним символы вплоть до очередно символа пробела. Следовательно, если написать #define WRITESTRING(x) cout << #x и выполнить следующий вызов макроса: WRITESTRING(This is а string); то препроцессор превратит его в такую строку кода: cout << "This is а string"; Обратите внимание, что строка This is а string заключается в кавычки, что и требуется для объекта cout. КонкатенацияОператор конкатенации позволяет связывать несколько строк в одну. Новая строка на самом деле представляет собой лексему, которую можно использовать как имя класса, имя переменной, смещение в массиве или другом объекте, где может содержаться ряд символов. Предположим на мгновение, что у вас есть пять функций с такими именами, как fOnePrint, fTwoPrint, fThreePrint, fFourPrint и fFivePrint. Теперь можно сделать следующее объявление: #define fPRINT(x) f ## x ## Print Затем использовать макрос fPRINT(x) с параметром Two, чтобы сгенерировать строку fTwoPrint, и с параметром Three, чтобы сгенерировать строку fThreePrint. В конце второй недели обучения был разработан класс PartsList. Этот список мог обрабатывать объекты только типа List. Предположим, что этот список зарекомендовал себя хорошей работой и вам захотелось так же хорошо создавать списки животных, автомобилей, компьютеров и т.д. Один метод решения этой задачи мог бы состоять в создании списков AnimalList, CarList, ComputerList и прочих путем вырезки и вставки кода в нужное место. Однако такой вариант решения быстро превратит вашу жизнь в кошмар, поскольку каждое изменение, вносимое в один список, нужно будет вносить во все другие. Но, к счастью, существует альтернативное решение — использование макросов и оператора конкатенации. Например, можно определить следующий макрос: #define Listof(Type) class Type##List { public: Type##List(){ } private: int itsLength; }; Суть этого примера состоит в том, чтобы включить в одно определение все необходимые методы и данные. Когда нужно будет создать список животных (AnimalList), достаточно записать Listof(Animal) и приведенная выше запись превратится в объявление класса AnimalList. В процессе применения этого подхода не обходится без некоторых проблем, подробно рассмотренных на занятии 19. Встроенные макросыМногие компиляторы используют ряд встроенных макросов, таких как DATE, __TIME__, __LINE__ и __FILE__ . Каждое из этих имен окружено двумя символами подчеркивания, чтобы снизить вероятность того, что они войдут в противоречие с именами, использованными в вашей программе. Когда препроцессор встречает один из этих макросов, он делает соответствующую подстановку. Вместо лексемы __DATE__ ставится текущая дата. Вместо __TIME__ — текущее время. Лексемы __LINE__ и __FILE__ заменяются номером строки исходного кода и именем файла соответственно. Следует отметить, что эти замены выполняются еще до компиляции. Учтите, что при выполнении программы вместо лексемы DATE будет стоять не текущая дата, а дата компиляции программы. Встроенные макросы часто используют при отладке. Макрос assert()Во многих компиляторах предусмотрен макрос assert, который возвращает значение TRUE, если его параметр принимает значение TRUE, и выполняет установленные действия, если его параметр принимает значение FALSE. Многие компиляторы в этом случае прерывают выполнение программы, другие же генерируют исключительную ситуацию (см. занятие 20). Одна из важных особенностей макроса assert() состоит в том, что препроцессор вообще не замещает его никаким кодом, если не определена лексема DEBUG. Это свойство — большое подспорье в период разработки и при передаче заказчику конечного продукта. Быстродействие программы не страдает и размер исполняемой версии не увеличивается в результате использования этого макроса. Чтобы не зависеть от конкретной версии компилятора, т.е. от его реакции на макрос assert(), можно написать собственный вариант этого макроса. В листинге 21.4 содержится простой макрос assert() и показано его использование. Листинг 21.4. Простой макрос assert() 1: // Листинг 21.4. Макрос ASSERT 2: #define DEBUG 3: #include <iostream.h> 4: 5: #ifndef DEBUG 6: #define ASSERT(x) 7: #else 8: #define ASSERT(x) 9: if (! (x)) 10: { 11: cout << "ERROR!! Assert " << #x << " failed\n"; \ 12: cout << " on line " << __LINE__ << "\n"; \ 13: cout << " in file " << FILE << "\n"; \ 14: } 15: #endif 16: 17: 18: int main() 19: { 20: int x = 5; 21: cout << "Первый макрос assert: \n"; 22: ASSERT(x==5); 23: cout << "\nВторой макрос assert: \n"; 24: ASSERT(x != 5); 25: cout << "\nВыполненоД n"; 26: return 0: 27: } Результат: First assert: Second assert: ERROR!! Assert x !=5 failed on line 24 in file test1704.cpp Done. Анализ: В строке 2 определяется лексема DEBUG. Обычно это делается из командной строки (или в интегрированной среде разработки) во время компиляции, что позволяет управлять этим процессом. В строках 8-14 определяется макрос assert(). Как правило, это делается в файле заголовка ASSERT.hpp, который следует включить во все файлы источников. В строке 5 проверяется определение лексемы DEBUG. Если она не определена, макрос assert() определяется таким образом, чтобы вообще не создавался никакой код. Если же лексема DEBUG определена, то выполняются строки кода 8-14. Сам макрос assert() представляет собой цельное выражение, разбитое на семь строк исходного кода. В строке 9 проверяется значение, переданное как параметр. Если передано значение FALSE, выводится сообщение об ошибках (строки 11 — 13). Если передано значение TRUE, никакие действия не выполняются. Оладка программы с помощью assert()Многие ошибки допускаются программистами, поскольку они верят в то, что функция возвратит определенное значение, а указатель будет ссылаться на объект, так как это логически очевидно, и забывают о том, что компилятор не подчиняется человеческой логике, а слепо следует командам и инструкциям, даже если они противоречат всякой логике. Программа может работать самым непонятным образом из-за того, что вы забыли инициализировать указатель при объявлении, и поэтому он ссылается на случайные данные, сохранившиеся в связанных с ним ячейках памяти. Макрос assert() поможет в поиске ошибок такого типа при условии, что вы научитесь правильно использовать этот макрос в своих программах. Каждый раз, когда в программе указатель передается как параметр или в виде возврата функции, имеет смысл проверить, действительно ли этот указатель ссылается на реальное значение. В любом месте программы, если ее выполнение зависит от значения некоторой переменной, с помощью макроса assert() вы сможете убедиться в том, что на это значение можно полагаться. При этом от частого использования макроса assert() вы не несете никаких убытков, поскольку он автоматически удаляется из программы, если не будет определена лексема DEBUG. Более того, присутствие макроса assert() также обеспечивает хорошее внутреннее документирование программы, поскольку наделяет в коде важные моменты, на которые следует обратить внимание в случае модернизации программы. Макрос assert() вместо исключенийНа прошлом занятии вы узнали, как с помощью исключений можно отслеживать и обрабатывать аварийные ситуации. Важно заметить, что макрос assert() не предназначен для обработки таких исключительных ситуаций, как ввод ошибочных данных, нехватка памяти, невозможность открыть файл и т.д, которые возникают во время выполнения программы. Макрос assert() создан для отслеживания логических и синтаксических ошибок программирования. Следовательно, если макрос assert() срабатывает, это сигнализирует об ошибке непосредственно в коде программы. Важно понимать, что при передаче программы заказчикам макросы assert() в коде будут удалены. Поэтому если с ошибками выполнения программы удавалось справляться только благодаря макросу assert(), то у заказчика эта программа просто не будет работать. Распространенной ошибкой является использование макроса assert() для тестирования возвращаемого значения при выполнении операции выделения памяти: Animal *pCat = new Cat: Assert(pCat); // неправильное использование макроса pCat->SomeFunction(); Это пример классической ошибки при отладке программы. В данном случае программист пытается с помощью макроса assert() предупредить возникновение исключительной ситуации нехватки свободной памяти. Обычно программист тестирует программу на компьютере с достаточным объемом памяти, поэтому макрос assert()B этом месте программы никогда не сработает. У заказчика может быть устаревшая версия компьютера, поэтому, когда программа доходит до этой точки, обращение к оператору new терпит крах и программа возвращает NULL (пустой указатель). Однако макроса assert() больше нет в коде, и некому сообщить пользователю о том, что указатель ссылается на NULL. Поэтому, как только дойдет очередь до выражения pCat->SomeFunction(), программа дает сбой. Возвращение значения NULL при выделения памяти — это не ошибка программирования, а исключительная ситуация. Чтобы программа смогла с честью выйти из этой ситуации, необходимо использовать исключение. Помните, что макрос assert() полностью удаляется из программы, если лексема DEBUG не определена. (Исключения были подробно описаны на занятии 20.) Побочные эффектыНередко случается так, что ошибка проявляется только после удаления экземпляров макроса assert(). Почти всегда это происходит из-за того, что программа попадает в зависимость от побочных эффектов, вызванных выполнением макроса assert() или другими частями кода, используемыми только для отладки. Например, если записать ASSERT (x = 5) при том, что имелась в виду проверка x == 5, вы тем самым создадите чрезвычайно противную ошибку. Предположим, что как раз до выполнения макроса assert() вызывалась функция, которая установила переменную x равной 0. Используя данный макрос, вы полагали, что выполняете проверку равенства переменной x значению 5. На самом же деле вы устанавливаете значение x равным 5. Тем не менее эта ложная проверка возвращает значение TRUE, поскольку выражение x = 5 не только устанавливает переменную x равной 5, но одновременно и возвращает значение 5, а так как 5 не равно нулю, то это значение расценивается как истинное. Во время отладки программы макрос assert() не выполняет проверку равенства переменной x значению 5, а присваивает ей это значение, поэтому программа работает прекрасно. Вы готовы передать ее заказчику и отключаете отладку. Теперь макрос assert() удаляется из кода и переменная x не устанавливается равной 5. Но поскольку в результате ошибки в функции переменная x устанавливается равной 0, программа дает сбой. Рассерженный заказчик возвращает программу, вы восстанавливаете средства отладки, но не тут-то было! Ошибка исчезла. Такие вещи довольно забавно наблюдать со стороны, но не переживать самим, поэтому остерегайтесь побочных эффектов при использовании средств отладки. Если вы видите, что ошибка появляется только при отключении средств отладки, внимательно просмотрите команды отладки с учетом проявления возможных побочных эффектов. Инварианты классаДля многих классов существует ряд условий, которые всегда должны выполняться при завершении работы с функцией-членом класса. Эти обязательные условия выполнения класса называются инвариантами класса. Например, обязательными могут быть следующие условия: объект CIRCLE никогда не должен иметь нулевой радиус или объект ANIMAL всегда должен иметь возраст больше нуля и меньше 100. Может быть весьма полезным объявление метода Invariants(), который возвращает значение TRUE только в том случае, если каждое из этих условий является истинным. Затем можно вставить макрос ASSERT(Invariants()) в начале и в конце каждого метода класса. В качестве исключения следует помнить, что метод Invariants() не возвращает TRUE до вызова конструктора и после выполнения деструктора. Использование метода Invariants() для обычного класса показано в листинге 21.5. Листинг 21.5. Использование метода lnvariаnts () 1: #define DEBUG 2: #define SHOW_INVARIANTS 3: #include <iostream.h> 4: #include <string.h> 5: 6: #ifndef DEBUG 7: #define ASSERT(x) 8: #else 9: #define ASSERT(x) 10: if (! (x)) 11: { 12: cout << "ERROR!! Assert " << #x << " failed\n"; 13: cout << " on line " << __LINE__ << "\n"; 14: cout << " in file " << FILE << "\n"; 15: } 16: #endif 17: 18: 19: const int FALSE = 0; 20: const int TRUE = 1; 21: typedef int bool; 22: 23: 24: class String 25: { 26: public: 27: // конструкторы 28: String(); 29: String(const char *const); 30: String(const String &); 31: ~String(); 32: 33: char & operator[](int offset); 34: char operator[](int offset) const; 35: 36: String & operator= (const String &); 37: int GetLen()const { return itsLen; } 38: const char * GetString() const { return itsString; } 39: bool Invariants() const; 40: 41: private: 42: String (int); // закрытый конструктор 43: char * itsString; 44: // беззнаковая целочисленная переменная itsLen; 45: int itsLen 46: }; 47: 48: // стандартный конструктор создает строку нулевой длины 49: String::String() 50: { 51: itsString = new char[1]; 52: itsString[0] = '\0'; 53: itsLen=0; 54: ASSERT(Invariants()); 55: } 56: 57: // закрытый (вспомогательный) конструктор, используется 58: // методами класса только для создания новой строки 59: // требуемого размера, При этом вставляется концевой нулевой символ.\ 60: String::String(int len) 61: { 62: itsString = new char[len+1]; 63: for (int i = 0; i<=len; i++) 64: itsString[i] = '\0'; 65: itsLen=len; 66: ASSERT(Invariants()); 67: } 68: 69: // Преобразует массив символов к типу String 70: String::String(const char * const cString) 71: { 72: itsLen = strlen(cString); 73: itsString = new char[itsLen+1]; 74: for (int i = 0; i<itsLen; i++) 75: itsString[i] = cString[i]; 76: itsString[itsLen] ='\0'; 77: ASSERT(Invariants()); 78: } 79: 80: // конструктор-копировщик 81: String::String (const String & rhs) 82: { 83: itsLen=rhs.GetLen(); 84: itsString = new char[itsLen+1]; 85: for (int i = 0; i<itsLen;i++) 86: itsString[i] = rhs[i]; 87: itsString[itsLen] = '\0'; 88: ASSERT(Invariants()); 89: } 90: 91: // деструктор, освобождает выделенную память 92: String::~String () 93: { 94: ASSERT(Invariants()); 95: delete [] itsString; 96: itsLen = 0; 97: } 96: 99: // оператор выполняет сравнение, освобождает занятую 100: // память, а затем копирует строку и ее размер 101: String& String::operator=(const String & rhs) 102: { 103: ASSERT(Invariants()); 104: if (this == &rhs) 105: return *this; 106: delete [] itsString; 107: itsLen=rhs,GetLen(); 108: itsString = new char[itsLen+1]; 109: for (int i = 0; i<itsLen;i++) 110: itsString[i] = rhs[i]; 111: itsString[itsLen] = '\0'; 112: ASSERT(Invariants()); 113: return *this; 114: } 115: 116: // неконстантный оператор индексирования 117: char & String::operator[](int offset) 118: { 119: ASSERT(Invariants()); 120: if (offset > itsLen) 121: { 122: ASSERT(Invariants()); 123: return itsString[itsLen-1]; 124: } 125: else 126: { 127: ASSERT(Invariants()); 128: return itsString[offset]; 129: } 130: } 131: // константный оператор индексирования 132: char String::operator[](int offset) const 133: { 134: ASSERT(Invariants()); 135: char retVal; 136: if (offset > itsLen) 137: retVal = itsString[itsLen-1]; 138: else 139: retVal = itsString[offset]; 140: ASSERT(Invariants()); 141: return retVal; 142: } 143: bool String::Invariants() const 144: { 145: #ifdef SHOW_INVARIANTS 146: cout << "Invariants Tested"; 147: #endif 148: return ( (itsLen && itsString) || 149: (!itsLen && !itsString) ); 150: } 151: class Animal 152: { 153: public: 154: Animal():itsAge(1),itsName("John Q. Animal") 155: { ASSERT(Invariants());} 156: Animal(int, const String&); 157: ~Animal(){ } 158: int GetAge() { ASSERT(Invariants()); return itsAge;} 159: void SetAge(int Age) 160: { 161: ASSERT(Invariants()); 162: itsAge = Age; 163: ASSERT(Invariants()); 164: } 165: String& GetName() 166: { 167: ASSERT(Invariants()); 168: return itsName; 169: } 170: void SetName(const String& name) 171: { 172: ASSERT(Invariants()); 173: itsName = name; 174: ASSERT(Invariants()); 175: } 176: bool Invariants(); 177: private: 178: int itsAge; 179: String itsName; 180: }; 181: 182: Animal::Animal(int age, const String& name): 183: itsAge(age), 184: itsName(name) 185: { 186: ASSERT(Invariants()); 187: } 188: 189: bool Animal::Invariants() 190: { 191: #ifdef SHOW_INVARIANTS 192: cout << "Invariants Tested"; 193: #endif 194: return (itsAge > 0 && itsName.GetLen()); 195: } 196: 197: int main() 198: { 199: Animal sparky(5, "Sparky"); 200: cout << "\n" << sparky.GetName().GetString() << " is "; 201: cout << sparky.GetAge() << " years old. "; 202: sparky.SetAge(8): 203: cout << "\n" << sparky.GetName(). GetString() << " is "; 204: cout << sparky.GetAge() << " years old. "; 205: return 0; 206: } Результат: String OK String OK String OK String OK String OK String OK String OK String OK String OK Animal OK String OK Animal OK Sparky is Animal OK 5 years old. Animal OK Animal OK Animal OK Sparky is Animal OK 8 years old. String OK Анализ: В строках 9—15 определяется макрос assert(). Если лексема DEBUG определена и макрос assert() возвратит в результате операции сравнения значение FALSE, будет выведено сообщение об ошибке. В строке 39 объявляется функция-член Invariants() класса String, а ее определение занимает строки 143—150. Конструктор объявляется в строках 49—55, а в строке 54, после того как объект полностью построен, вызывается функция-член Invariants(), чтобы подтвердить правомочность этой конструкции. Этот алгоритм повторен для других конструкторов, а для деструктора функция- член Invariants() вызывается только перед тем, как удалить объект. Остальные методы класса вызывают функцию Invariants() перед выполнением любого действия, а затем еще раз перед возвратом из функции. В этом проявляется отличие функций- членов от конструкторов и деструкторов: функции-члены всегда работают с реальными объектами и должны оставить их таковыми по завершению выполнения функции. В строке 176 класс Animal объявляет собственный метод Invariants(), выполняемый в строках 189—195. Обратите внимание на строки 155, 158, 161 и 163: подставляемые функции также могут вызывать метод Invariants(). Печать промежуточных значенийНе исключено, что в дополнение к возможности с помощью макроса assert() убедиться в истинности некоторого тестируемого выражения вы захотите вывести на экран текущие значения указателей, переменных и строк. Это может быть полезно для проверки ваших предположений насчет некоторых аспектов работы программы, а также при поиске ошибок в циклах. Реализация этой идеи показана в листинге 21.6. Листинг 21.6. Вывод значений в режиме отладки 1: // Листинг 21.6. Вывод значений в режиме отладки 2: #include <iostream.h> 3: #define DEBUG 4: 5: #ifndef DEBUG 6: #define PRINT(x) 7: #else 8: #define PRINT(x) \ 9: cout << #x << ":\t" << x << endl; 10: #endif 11: 12: enum bool { FALSE, TRUE } ; 13: 14: int main() 15: { 16: int x = 5; 17: long у = 738981; 18: PRINT(x); 19: for (int i = 0; i < x; i++) 20: { 21: PRINT(i); 22: } 23: 24: PRINT (у); 25: PRINT("Hi,"); 26: int *px = &x; 27: PRINT(px); 28: PRINT (*px); 29: return 0; 30: } Результат: x: 5 i: 0 i: 1 i: 2 i: 3 i: 4 у: 73898 "Hi.": Hi. px: 0x2100 *px: 5 Анализ: Макрос PRINT(x) (строки 5—10) реализует вывод текущего значения переданного параметра. Обратите внимание, что сначала объекту cout передается сам параметр, взятый в кавычки, т.е., если вы передадите параметр x, объект cout примет "x". Затем объект cout принимает заключенную в кавычки строку ":\t", которая обеспечивает печать двоеточия и табуляции. После этого объект cout принимает значение параметра (x), а объект endl выполняет переход на новую строку и очищает буфер. Обратите внимание, что у вас вместо значения 0x2100 может быть выведено другое число. Уровни отладкиВ больших и сложных проектах вам, возможно, понадобится больше рычагов управления для отлаживания программы, чем просто подключение и отключение режима отладки (путем определения лексемы DEBUG). Вы можете определять уровни отладки и выполнять тестирование для этих уровней, принимая решение о том, какие макрокоманды использовать, а какие - удалить. Чтобы определить уровень отладки, достаточно после выражения #define DEBUG указать номер. Хотя число уровней может быть любым, обычная система должна иметь четыре уровня: HIGH (высокий), MEDIUM (средний), LOW (низкий) и NONE (никакой). В листинге 21.7 показано, как это можно сделать, на примере классов String и Animal из листинга 21.5. Листинг 21.7. Уровни отладки 1: enum LEVEL { NONE, LOW, MEDIUM, HIGH } ; 2: const int FALSE = 0; 3: const int TRUE = 1; 4: typedef int bool; 5: 6: #define DEBUGLEVEL HIGH 7: 8: #include <iostream.h> 9: #include <string.h> 10: 11: #if DEBUGLEVEL < LOW // должен быть средний или высокий 12: #define ASSERT(x) 13: #else 14: #define ASSERT(x) 15: if (!(x)) 16: { 17: cout << "ERROR!! Assert " << #x << " failed\n"; 18: cout << " on line " << __LINE__ << "\n"; 19: cout << " in file " << FILE << "\n"; 20: } 21: #endif 22: 23: #if DEBUGLEVEL < MEDIUM 24: #define EVAL(x) 25: #else 26: #define EVAL(x) 27: cout << #x << ":\t" << x << andl; 28: #endif 29: 30: #if DEBUGLEVEL < HIGH 31: #define PRINT(x) 32: #else 33: #define PRINT(x) 34: cout << x << endl; 35: #endif 36: 37: 38: class String 39: { 40: public: 41: // конструкторы 42: String(); 43: String(const char *const); 44: String(const String &); 45: ~String(); 46: 47: char & operator[](int offset); 48: char operator[](int offset) const; 49: 50: String & operator= (const String &); 51: int GetLen()const { return itsLen; } 52: const char >> GetString() const 53: { return itsString; } 54: bool Invariants() const; 55: 56: private: 57: String (int); // закрытый конструктор 58: char * itsString; 59: unsigned short itsLen; 60: }; 61: 62: // стандартный конструктор создает строку нулевой длины 63: String::String() 64: { 65: itsString = new char[1]; 66: itsString[0] = '\0'; 67: itsLen=0; 68: ASSERT(Invariants()); 69: } 70: 71: // закрытый (вспомогательный) конструктор, используемый 72: // методами класса только для создания новой строки 73: // требуемого размера. Заполняется символом Null. 74: String::String(int len) 75: { 76: itsString = new char[len+1]; 77: for (int i = 0; i<=len; i++) 78: itsString[i] = '\0'; 79: itsLen=len; 80: ASSERT(Invariants()); 81: } 82: 83: // Преобразует массив символов к типу String 84: String::String(const char * const cString) 85: { 86: itsLen = strlen(cString); 87: itsString = new char[itsLen+1]; 88: for (int i = 0; i<itsLen; i++) 89: itsString[i] = cString[i]; 90: itsString[itsLen]='\0'; 91: ASSERT(Invariants()); 92: } 93: 94: // конструктор-копировщик 95: String::String (const String & rhs) 96: { 97: itsLen=rhs.GetLen(); 98: itsString = new char[itsLen+1]; 99: for (int i = 0; i<itsLen;i++) 100: itsString[i] = rhs[i]; 101: itsString[itsLen] = '\0'; 102: ASSERT(Invariants()); 103: } 104: 105: // деструктор освобождает выделенную память 106: String::^String () 107: { 108: ASSERT(Invariants()); 109: delete [] itsString; 110: itsLen = 0; 111: } 112: 113: // оператор выполняет сравнение, освобождает занятую память 114: // затем копирует строку и ее размер 115: String& String::operator=(const String & rhs) 116: { 117: ASSERT(Invariants()); 118: if (this == &rhs) 119: return *this; 120: delete [] itsString; 121: itsLen=rhs.GetLen(); 122: itsString = new char[itsLen+1]; 123: for (int i = 0; i<itsLen;i++) 124: itsString[i] = rhs[i]; 125: itsString[itsLen] = '\0'; 126: ASSERT(Invariants()); 127: return *this; 128: } 129: 130: // неконстантный оператор индексирования 131: char & String:;operator[](int offset) 132: { 133: ASSERT(Invariants()); 134: if (offset > itsLen) 135: { 136: ASSERT(Invariants()); 137: return itsString[itsLen-1]; 138: } 139: else 140: { 141: ASSERT(Invariants()); 142: return itsString[offset]; 143: } 144: } 145: // константный оператор индексирования 146: char String::operator[](int offset) const 147: { 148: ASSERT(Invariants()); 149: char retVal; 150: if (offset > itsLen) 151: retVal = itsString[itsLen-1]; 152: else 153: retVal = itsString[offset]; 154: ASSERT(Invariants()); 155: return retVal; 156: } 157: 158: bool String::Invariants() const 159: { 160: PRINT("(String Invariants Checked)"); 161: return ( (bool) (itsLen && itsString) || 162: (!itsLen && !itsString) ); 163: } 164: 165: class Animal 166: { 167: public: 168: Anxmal():itsAge(1),itsName("John Q, Animal") 169: { ASSERT(Invariants());} 170: 171: Animal(int, const String&); 172: ~Animal(){ } 173: 174: int GetAge() 175: { 176: ASSERT(Invariants()); 177: return itsAga; 178: } 179: 180: void SetAge(int Age) 181: { 182: ASSERT(Invariants()); 183: itsAge = Age; 184: ASSERT(Inva riants()); 185: } 186: String& GetName() 187: { 188: ASSERT(Invariants()); 189: return itsName; 190: } 191: 192: void SetName(const String& name) 193: { 194: ASSERT(Invariants()); 195: itsName = name; 196: ASSERT(Invariants()); 197: } 198: 199: bool Invariants(); 200: private: 201: int itsAge; 202: String itsName; 203: } 204: 205: Animal::Animal(int age, const String& name): 206: itsAge(age), 207: itsName(name) 208: { 209: ASSERT(Invariants()); 210: } 211: 212: bool Animal::Invariants() 213: { 214: PRINT("(Animal Invariants Checked)"); 215: return (itsAge > 0 && itsName.GetLen()); 216: } 217: 218: int main() 219: { 220: const int AGE = 5; 221: EVAL(AGE); 222: Animal sparky(AGE,"Sparky"); 223: cout << "\n" << sparky.GetName().GetStrin(); 224: cout << " is "; 225: cout << sparky.GetAge() << " years old."; 226: sparky.SetAge(8); 227: cout << "\n" << sparky.GetName().GetString(); 228: cout << " is "; 229: cout << sparky.GetAge() << " years old."; 230: return 0; 231: } Результат: AGE: 5 (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) (String Invariants Checked) Sparky is (Animal Invariants Checked) 5 years old. (Animal Invariants Checked) (Animal Invariants Checked) (Animal Invariants Checked) Sparky is (Animal Invariants Checked) 8 years old. (String Invariants Checked) (String Invariants Checked) // run again with DEBUG = MEDIUM AGE: 5 Sparky is 5 years old. Sparky is 8 years old. Анализ: В строках 11—21 макрос assert() определяется таким образом, чтобы вообще не создавался никакой код, если уровень отладки DEBUGLEVEL меньше, чем LOW (т.е. DEBUGLEVEL установлен равным значению NONE). Если же отладка разрешена, то и макрос assert() будет работать (строки 14—21). В строке 24 макрос EVAL отключается, если уровень отладки DEBUGLEVEL меньше, чем MEDIUM; иными словами, если уровень отладки DEBUGLEVEL установлен равным значению NONE или LOW, макрос EVAL не работает. Наконец, в строках 30—35, макрофункция PRINT объявляется "бездействующей", если уровень отладки DEBUGLEVEL меньше, чем HIGH. Макрофункция PRINT используется только в том случае, если уровень отладки DEBUGLEVEL установлен равным значению HIGH, т.е. этот макрос можно удалить, установив уровень отладки DEBUGLEVEL равным значению MEDIUM, и при этом поддерживать использование макросов EVAL и assert(). Макрос PRINT используется внутри методов Invariants() для печати информативного сообщения. Макрос EVAL используется в строке 221, чтобы отобразить текущее значение целочисленной константы AGE. Рекомендуется:Используйте ПРОПИСНЫЕ буквы для имен макросов. Это широко распространенное соглашение, поэтому его несоблюдение может ввести в заблуждение других программистов. Заключайте все аргументы макросов в круглые скобки. Не рекомендуется:Не изменяйте и не присваивайте значения переменных в макросах отладки, поскольку это чревато появлением побочных эффектов. Операции с битами данныхИногда, чтобы отслеживать состояние объектов, бывает удобно устанавливать для них флаги. (Например, с помощью флагов можно проверить, был ли объект инициализирован, вызывался ли для него определенный метод и пр., а также связать вывод предупреждающих сообщений с флагом объекта AlarmState.) Для флагов можно использовать переменные типа Boolean, но если у вас много признаков и для вас важно экономить ресурсы компьютера, удобнее для установки флагов использовать отдельные биты значения в двоичном формате. Каждый байт имеет восемь битов, поэтому четырехбайтовая переменная типа long может представлять 32 отдельных флага. Если значение бита равно 1, то говорят, что флаг установлен, а если 0 — то сброшен. Другими словами, чтобы установить флаг, нужно определенному биту переменной присвоить значение 1, а чтобы сбросить флаг — значение 0. Устанавливать и сбрасывать флаги можно, изменяя значения переменной типа long, но такой подход нерационален и может ввести в заблуждение. Примечание:В приложении В содержится ценная дополнительная информация об операциях над двоичными и шестнадцатеричными числами. В языке C++ предусмотрены побитовые операторы для работы с битами данных. Они схожи, но в то же время отличаются от логических операторов, поэтому многие начинающие программисты их путают. Побитовые операторы представлены в табл. 21.1. Таблица 21.1. Побитовые операции  Оператор И (AND)Для обозначения оператора побитового И (&) используется одиночный амперсант, а оператор логического И обозначается двумя амперсантами. При выполнении операции побитового И с двумя битами результат равен 1, если оба бита равны 1, и 0, если хотя бы один бит (или оба сразу) равен 0. Оператор ИЛИ (OR)Вторым побитовым оператором является ИЛИ (|). И опять-таки для его обозначения используется одиночный символ вертикальной черты, в отличие от логического ИЛИ, обозначаемого двумя символами вертикальной черты. При выполнении операции побитового ИЛИ с двумя битами результат равен 1, если хотя бы один бит (или оба сразу) равен 1. Оператор исключающего ИЛИ (XOR)Третий побитовый оператор — исключающее ИЛИ (^). При выполнении операции исключающего ИЛИ с двумя битами результат равен 1, если эти два разряда различны. Оператор дополнения до единицыОператор дополнения до единицы (~) сбрасывает каждый установленный бит и устанавливает каждый сброшенный бит в числе. Если текущее значение равно 1010 0011, то дополнение его до единицы будет иметь вид 0101 1100. Установка битовЕсли вы хотите установить или сбросить конкретный флаг, следует использовать опа- рацию маскирования. Если в программе для установки флагов используется 4-байтовая переменная и нужно установить флаг, связанный с восьмым битом этой переменной, следует выполнить операцию побитового ИЛИ для этой переменной и числа 128. Почему 128? Потому что 128 - это 1000 0000 в двоичной системе счисления, таким образом, можно сказать, что число 128 определяет значение восьмого разряда. Независимо от текущего значения этого разряда в 4-байтовой переменной (установлен он или сброшен), при выполнении операции ИЛИ с числом 128 этот бит будет установлен, а все остальные биты сохранят прежние значения. Предположим, что текущее значение этой 4-байтовой переменной в двоичном формате равно 1010 0110 0010 0110. Применение к ней операции ИЛИ с числом 128 выглядит следующим образом: 9 8765 4321 1010 0110 0010 0110 // 8-й бит сброшен | 0000 0000 1000 0000 // 128 _ _ _ _ _ _ _ _ _ _ _ 1010 0110 1010 0110 // 8-й бит установлен Хочется обратить ваше внимание на некоторые вещи. Во-первых, как правило, биты считаются справа налево. Во-вторых, значение 128 содержит все нули, за исключением восьмого бита, т.е. того разряда, который вы хотите установить. В-третьих, в исходном числе 1010 0110 0010 0110 операцией ИЛИ изменяется только восьмой бит. Если бы он в этом значении был установлен еще до выполнения операции ИЛИ, то значение вообще не изменилось бы. Сброс битовЕсли нужно сбросить восьмой бит, можно использовать побитовую операцию И с дополнением числа 128 до единицы. Дополнение числа 128 до - это называется такое число, которое получается, если взять в двоичном представлении число 128 (1000 0000), а затем установить в нем каждый сброшенный и сбросить каждый установленный бит (0111 1111). При выполнении побитовой операции И с этими числами исходное число не изменяется, за исключением восьмого разряда, который сбрасывается в нуль. 1010 0110 1010 0110 // 8-й бит установлен & 1111 1111 0111 1111 // ~128 (дополнение до единицы числа 128) _ _ _ _ _ _ _ _ _ _ _ 1010 0110 0010 0110 // 8-й бит сброшен Чтобы до конца понять этот метод решения, сделайте самостоятельно все математические операции. Каждый раз, когда оба бита равны 1, запишите результат равным 1. Если какой-нибудь бит равен 0, запишите в ответе 0. Сравните ответ с исходным числом. Оно должно остаться без изменений, за исключением восьмого бита, который в результате этой операции побитового И будет сброшен. Инверсия битовНаконец, если вы хотите инвертировать восьмой бит независимо от его предыдущего состояния, используйте операцию исключающего ИЛИ для этого числа и числа 128. Итак: 1010 0110 1010 0110 // число ^ 0000 0000 1000 0000 // 128 _ _ _ _ _ _ _ _ _ _ _ 1010 0110 0010 0110 // 8-й бит инвертирован ^ 0000 0000 1000 0000 // 128 _ _ _ _ _ _ _ _ _ _ _ 1010 0110 1010 0110 // 8-й бит инвертирован снова Рекомендуется:Используйте маски и оператор ИЛИ для установки битов. Используйте маски и оператор И для сбросабитов. Используйте маски и оператор исключающего или для инвертирования битов. Битовые поляПри некоторых обстоятельствах, когда на счету каждый байт, экономия шести или восьми байтов в классе может иметь существенные последствия. Если в классе или структуре вместо набора логических переменных (типа Boolean) или переменных, которые могут иметь только очень небольшое число возможных значений, использовать битовые поля, можно сэкономить некоторый объем памяти. Среди стандартных типов данных C++ меньше всего памяти требуют переменные типа char: длина переменной составляет всего один байт. Часто для создания битовых полей используются переменные типа int, для которых требуется два или чаше четыре байта. В битовом поле, основанном на переменной типа char, можно хранить восемь двоичных значений, а в переменной типа long - 32 таких значения. Так как же работают битовые поля? Им присваиваются имена и организуется доступ точно таким же способом, как к любому члену класса. Они всегда объявляются с использованием беззнакового типа int. После имени битового поля ставится двоеточие и число. Число указывает компилятору, сколько битов будет использовано для установки одного значения. Так, если записать число 1, то с помощью одного бита можно будет присваивать только значения 0 или 1. Если записать число 2, то с помощью двух битов можно будет представлять четыре значения: 0, 1, 2 или 3. Поле из трех битов может представлять восемь значений и т.д. Обзор двоичных чисел приведен в приложении В. Использование битовых полей иллюстрируется в листинге 21.8. Листинг 21.8. Использование битовых полей 1: #include <iostream.h> 2: #include <string.h> 3: 4: enum STATUS { FullTime, PartTime }; 5: enum GRADLEVEL { UnderGrad, Grad }; 6: enum HOUSING { Dorm, OffCampus }; 7: enum FOODPLAN { OneMeal, AllMeals, WeekEnds, NoMeals }; 8: 9: class student 10: { 11: public: 12: student(): 13: myStatus(FullTime), 14: myGradLevel(UnderGrad), 15: myHousing(Dorm), 16: myFoodPlan(NoMeals) 17: { } 18: ~student() { } 19: STATUS GetStatus(); 20: void SetStatus(STATUS); 21: unsigned GetPlan() { return myFoodPlan; } 22: 23: private: 24: unsigned myStatus: 1; 25: unsigned myGradLevel: 1; 26: unsigned myHousing: 1; 27: unsigned myFoodPlan: 2; 28: }; 29: 30: STATUS student::GetStatus() 31: { 32: if (myStatus) 33: return FullTime; 34: else 35: return PartTime; 36: } 37: void student::SetStatus(STATUS theStatus) 38: { 39: myStatus = theStatus; 40: } 41: 42: 43: int main() 44: { 45: student Jim; 46: 47: if (Jim.GetStatus()== PartTime) 48: cout << "Jim is part time" << endl; 49: else 50: cout << "Jim is full time" << endl; 51: 52: Jim.SetStatus(PartTime); 53: 54: if (Jim.GetStatus()) 55: cout << "Jim is part time" << endl; 56: else 57: cout << "Jim is full time" << endl; 58: 59: cout << "Jim is on the " ; 60: 61: char Plan[80]; 62: switch (Jim.GetPlan()) 63: { 64: case OneMeal: strcpy(Plan, "One meal"); break; 65: case AllMeals: strcpy(Plan, "All meals"); break; 66: case WeekEnds: strcpy(Plan, "Weekend meals"); break; 67: case NoMeals: strcpy(Plan, "No Meals");break; 68: default : cout << "Something bad went wrong!\n"; break; 69: } 70: cout << Plan << " food plan. " << endl; 71: return 0; 72: } Результат: Jim is part time Jim is full time Jim is on the No Meals food plan. Анализ: Строки 4—7 содержат определение нескольких перечислений. Они используются для определения значения битовых полей внутри класса student. В строках 9—28 объявляется класс student. Несмотря на тривиальность, он интересен тем, что все его данные упакованы в пяти битах. Первый бит определяет, является ли данный студент представителем очной (full time) или заочной (part time) формы обучения. Второй — получил ли этот студент степень бакалавра (UnderGrad). Третий — проживает ли студент в общежитии. И последние два бита определяют, какой из четырех возможных вариантов питания в студенческой столовой выбран студентом. Методы класса не отличаются ничем особенным от методов любого другого класса, т.е. на них никоим образом не повлиял тот факт, что они написаны для битовых полей, а не для обычных целочисленных значений или перечислений. Функция-член GetStatus() считывает значение бита и возвращает константу перечисления, но это не обязательное решение. С таким же успехом можно было бы написать вариант, непосредственно возвращающий значение битового поля. Компилятор сам сможет преобразовать битовое значение в константу. Чтобы убедиться в этом, замените выполнение функции GetStatus() следующим кодом: STATUS student::GetStatus() { return myStatus; } При этом в работе программы не произойдет никаких изменений. Вариант, приведенный в листинге, — это дань ясности при чтении кода, а на результат работы компилятора это изменение никак не повлияет. Обратите внимание на то, что строка 47 должна проверить статус студента (full time или part time), а затем вывести соответствующее сообщение. Попробуем выполнить то же самое по-другому: cout << "Jim is " << Jim.GetStatus() << endl; В результате выполнения этого выражения будет выведено следующее сообщение: Jim is 0 Компилятор не сможет перевести константу перечисления PartTime в соответствующую строку текста. В строке 62 программы определяется вариант питания студента и для каждого возможного значения соответствующее сообщение помещается в буфер, а затем выводится в строке 70. Опять-таки заметим, что конструкцию с оператором switch можно было бы написать следующим образом: case 0: strcpy(Plan,"One meal"); break; case 1: strcpy(Plan,"All meals"); break; case 2: strcpy(Plan,"Weekend meals"); break; case 3: strcpy(Plan,"NoMeals"); break; Самое важное в использовании битовых полей то, что клиент класса не должен беспокоиться насчет способа хранения данных. Поскольку битовые поля относятся к скрытым данным, вы можете свободно изменить их впоследствии, при этом никаких изменений интерфейса не потребуется. Стиль программированияКак уже упоминалось в этой книге, в программе важно придерживаться одного принятого стиля, хотя в целом не имеет значения, какому именно стилю вы отдаете предпочтение. Соблюдение определенного стиля существенно облегчает чтение и анализ программы. Следующие рекомендации совершенно ни к чему вас не обязывают. Они основаны на ряд принципов, которых я придерживаюсь при работе над проектами и которые нахожу полезными. Вы можете выработать собственные правила, но приведенные ниже помогут выделить основные моменты, на которые следует обратить внимание. Хотя в жизни чрезмерная пунктуальность нас раздражает, тем не менее строгое соблюдение стиля при написании программы поможет вам и вашим коллегам эффективнее использовать и модернизировать однажды написанный код. Постарайтесь выработать собственный стиль программирования и затем относитесь к нему так, как к уголовному кодексу, нарушение которого карается законом. ОтступыОтступ табуляции должен составлять четыре пробела. Убедитесь в том, что ваш редактор преобразует каждую табуляцию в четыре пробела. Фигурные скобкиСпособ выравнивания фигурных скобок вызывает, возможно, самые бурные споры между программистами C++ и С. Я лично придерживаюсь следующих правил: • пара фигурных скобок должна быть выровнена по вертикали; • фигурные скобки первого уровня в определении или объявлении должны быть выровнены по левому полю. Все строки блока объявления или определения записываются с отступом. Все вложенные пары фигурных скобок должны быть выровнены по одной линии со строкой программы, за которой начинается этот блок; • строки блока никогда не должны находиться на одной линии с фигурными скобками, обрамляющими этот блок, например: if (condition==true) { j = k; SomeFunction(); } m++; Длинные строкиУдерживайте ширину строк в таких пределах, чтобы они помещались на экране. Код, который "убегает" вправо, можно легко пропустить, а горизонтальная прокрутка всегда раздражает. При разбиении строки для следующих строк делайте отступы. Старайтесь разбивать строку, следуя логике и здравому смыслу. Оставляйте оператор в конце предыдущей строки (а не в начале следующей), чтобы было понятно, что данная строка является продолжением предыдущей. В языке C++ функции часто оказываются более короткими, чем в С, но по- прежнему остается в силе старый добрый совет: старайтесь сохранять свои функции достаточно короткими, чтобы всю функцию можно было увидеть на экране. Конструкции с оператором switchВ конструкциях с оператором switch используйте отступы таким образом, чтобы четко выделить различные варианты: switch(переменная) { case Значение_1: Oперация_1(); break; case Значение_2: Операция_2(); break; default; assert("Ошибочное действие"); break; } Текст программыЧтобы создавать программы, которые будут простыми для чтения, воспользуйтесь следующими советами. Если код просто читать, его нетрудно будет и поддерживать. • Используйте пробелы, чтобы сделать текст программы более разборчивым. • Не используйте пробелы внутри ссылок на объекты и массивы (., ->, [ ]). • Унарные операторы логически связаны со своими операндами, поэтому не ставьте между ними пробелов. К унарным операторам относятся следующие: !, ^, ++, --, -, * (для указателей), & (преобразования типа), sizeof. • Бинарные операторы должны иметь пробелы с обеих сторон: +, =, *, /, %, >>, <<, <, >, ==, !=, &, I, &&, ||, ?:, -=, += И Т.Д. • Не используйте отсутствие пробелов для обозначения приоритета (4+ 3*2). • Ставьте пробелы после запятых и точек с запятой, но не перед ними. • Круглые скобки не должны отделяться пробелами от заключенных в них параметров. • Ключевые слова, такие как if, следует отделять пробелами: if (а == b). • Текст комментария следует отделять пробелом от символов //. • Размещайте спецификаторы указателей и ссылок рядом с именем типа, а не с именем переменной, т.е. char* foo; int& theInt; а не: char *foo; int &theInt; • Не объявляйте больше одной переменной в одной строке. Имена идентификаторовНиже перечислены рекомендации для работы с идентификаторами. • Имена идентификаторов должны быть такими, чтобы по ним было легко понять назначение идентификатора. • Избегайте непонятных сокращений. • Не жалейте времени и энергии для подбора кратких, но метких имен. • Нет смысла использовать венгерскую систему имен (устанавливать связь между типом переменной и первой буквой ее имени). В языке C++ строго соблюдается контроль за соответствием типов, и нет никакой необходимости придумывать дополнительные средства контроля. Для типов, определяемых пользователем (классов), венгерская система имен вообще теряет смысл. Исключением может быть разве что использование префикса (p) для указателей и (r) для ссылок, а также префиксов its или my для переменных-членов класса. • Короткие имена (i, p, x и т.д.) должны использоваться только там, где их краткость делает код более читабельным, а использование настолько очевидно, что в более описательных именах нет необходимости. • Длина имени переменной должна быть пропорциональна ее области видимости. • Во избежание путаницы и конфликтов имен убедитесь в том, что все идентификаторы пишутся по-разному. • Имена функций (или методов) обычно представляют собой глаголы или отглагольные существительные: Search(), Reset(), FindParagraph(), ShowCursor(). В качестве имен переменных обычно используются абстрактные существительные, иногда с дополнительным существительным: count, state, windSpeed, windowHeight. Логические переменные должны называться в соответствии с их назначением: windowIconized, fileIsOpen. Правописание и использование прописных букв в именахПри создании собственного стиля важное значение имеет проверка правописания и использование в именах прописных букв. Считаю, что вам не стоит пренебрегать приведенными ниже советами. • Используйте прописные буквы и символ подчеркивания, чтобы отделить слова в имени идентификатора, например SOURCE_FILE_TEMPLATE. Однако имена, полностью состоящие из прописных букв, в C++ довольно редки. Они используются разве что для констант и шаблонов. • В именах других идентификаторов сочетаются строчные и прописные буквы с символами подчеркивания. Имена функций, методов, классов, типов и структур должны начинаться с прописных букв. Переменные-члены или локальные переменные обычно начинаются со строчных букв. • Константы перечислений должны начаться несколькими строчными буквами, представляющими аббревиатуру имени перечисления, например: enum TextStyle { tsPlain, tsBold, tsItalic, tsUnderscore, }; КомментарииКомментарии значительно облегчают понимание программы. Иногда работа над программой прерывается на несколько дней или даже месяцев. За это время можно забыть, что делается в той или иной части программы либо зачем был написан определенный фрагмент кода. Проблемы могут также возникать в том случае, если ваш код анализирует кто-то другой (а не вы сами). Комментарии, используемые в соответствии с согласованным и хорошо продуманным стилем, оправдывают затраченные на них усилия. Предлагаю несколько советов, которые стоит помнить при использовании комментариев. • Везде, где возможно, используйте для комментариев стиль C++, т.е. символы //, а не пары символов /* */. • Комментарии более высокого уровня гораздо важнее, чем описание отдельного метода. Поясняйте смысл происходящего, а не дублируйте словами выполняемые операции, как в этом примере: n++; // n инкрементируется на единицу Этот комментарий не стоит времени, затраченного на его ввод. Уделите внимание семантике функций и блоков кода. Опишите, что делает функция. Укажите побочные эффекты, типы параметров и возвращаемые значения. Опишите все допущения, которые были сделаны (или не сделаны), например "предположим, что n неотрицателен", или "функция возвращает -1, если x имеет недопустимое значение". В случае ветвления программы указывайте, при каких условиях будет выполняться эта часть кода. • Используйте законченные предложения с соответствующей пунктуацией и прописными буквами в начале предложений. Потом вы скажете себе за это спасибо. Избегайте условных обозначений и сокращений, понятных только вам. То, что сейчас кажется очевидным, через несколько месяцев может показаться абсолютно непонятным. • Используйте пустые строки для отделения логических блоков программы. Объединяйте строки программы в логические группы. Организация доступа к данным и методамОрганизация доступа к данным и методам также должна подчиняться определенным правилам. Ниже приведен ряд советов, касаюшихся того, как нагляднее описать в программе различия в доступе к ее разным членам. • Всегда используйте спецификаторы public:, private: и protected:. Не следует полагаться на установки доступа, делаемые по умолчанию. • Сначала объявите открытые (public) члены, затем защищенные (protected:), а за ними закрытые (private:). Объявляйте переменные-члены после методов. • Сначала объявите конструктор (конструкторы), а затем — деструктор. Сгруппируйте вместе перезагружаемые методы и методы доступа. • Методы и переменные-члены внутри каждой группы желательно расположить по именам в алфавитном порядке. Следует также упорядочить по алфавиту включения файлов с помощью директивы #include. • Несмотря на то что с замещенными функциями использование ключевого слова virtual необязательно, лучше им не пренебрегать. Оно напомнит вам, что данная функция является виртуальной, и обеспечит преемственность объявлений. Определения классовСтарайтесь сохранять порядок определения методов таким же, как и в объявлении. Это ускорит поиск нужного метода. При определении функции размещайте тип возвращаемого значения и все другие спецификаторы на предыдущей строке, чтобы имя класса и функции располагалось в начале строки. Это значительно облегчит поиск функций. Включение файловСтарайтесь избегать этого в файлах заголовков, кроме случая включения файла заголовка базового класса, от которого производится данный класс. Использование директив #include также необходимо в тех случаях, когда в объявляемом классе используются объекты другого класса. Для классов, на которые просто делаются ссылки, достаточно будет передать ссылку или указатель. Если же все-таки необходимо включить некоторый файл в программу, сделайте это в файле заголовка, даже если вы полагаете, что этот файл будет включен и в файле источника. Примечание:Во всех файлах заголовков следует использовать систему защиты от повторного объявления, с которой вы познакомились выше при рассмотрении макросов. Макрос assert()Используйте макрос assert() без всяких ограничений. Он не только помогает находить ошибки, но и облегчает чтение программы. Этот макрос также помогает сконцентрировать мысли автора на том, что является допустимым, а что — нет. Ключевое слово constИспользуйте ключевое слово const везде, где считаете нужным: для параметров, переменных и методов. Часто существует потребность в использовании как константных, так и неконстантных версий некоторых методов. Будьте очень осторожны при явном приведении типа с константного к неконстантному и наоборот (хотя иногда такой подход оказывается единственным способом решения проблемы). Убедитесь в целесообразности этих действий и добавьте подробный комментарий. Сделаем еще один шаг впередДолгие три недели вы отдали усердной работе над освоением средств программирования языка C++ и теперь вполне можете считать себя компетентным программистом C++. Но на этом ни в коем случае нельзя ставить точку. Несмотря на то что, прочитав эту книгу, вы узнали много полезных вещей, гораздо больший объем вам еще предстоит узнать, причем сначала имеет смысл познакомиться с источниками ценной информации, благодаря которой из новичка вы превратитесь в опытного программиста C++. В следующих разделах рекомендуется ряд конкретных источников информации, причем эти рекомендации отражают лишь мой персональный опыт и мое личное мнение. В последнее время ежегодно издается множество книг, посвященных программированию на C++, поэтому, прежде чем делать покупку, постарайтесь проконсультироваться со специалистами в этой области. Где получить справочную информацию и советыПервое, что вам стоит сделать, — отыскать в Internet одну из конференций по C++. Эти группы поддерживают непосредственный контакт с сотнями и даже тысячами программистов C++, которые смогут ответить на ваши вопросы, предложить советы и подсказать решения для ваших идей. Я принимаю участие в группах новостей Internet, посвященных C++ (comp.lang.c++ и comp.lang.c++.moderated), и рекомендую их в качестве превосходных источников информации и поддержки. Кроме того, стоит поискать локальные группы пользователей. Во многих городах есть так называемые группы по интересам (в том числе и группы C++), в которых можно встретить других программистов и обменяться идеями. ЖурналыЗакрепить свои навыки можно, подписавшись на хороший журнал, посвященный программированию на языке C++. По моему мнению, самым лучшим журналом по этой тематике является C++ Report издательства SIGS Publications. Каждый выпуск этого журнала содержит полезные статьи, поэтому их стоит сохранять — ведь то, что не волнует вас сегодня, станет чрезвычайно важным уже завтра. (Предостережение: я написал об этом журнале в первом и втором издании книги, но теперь я веду в нем ежемесячную рубрику, и потому налицо конфликт интересов. Тем не менее я по- прежнему считаю, что этот журнал — потрясающее издание.) Журнал C++ Report можно приобрести в издательстве SIGS Publications по адресу: P.O. Box 2031, Langhorne, РА 19047-9700. Выскажите свое мнение о книгеЕсли у вас есть комментарии, предложения или замечания относительно этой или других книг, я бы с интересом их выслушал. Пишите мне по адресу: jliberty@libertyassociates.com или посетите мой Web-узел: www.libertyassociates.com. Я с нетерпением буду ждать ваши отзывы. Рекомендуется:Обратитесь к другим книгам по C++. Нет такой книги, в которой все темыбыли бы рассмотрены одинаково полно и которая могла бы научить всему, что нужно знать профессиональному программисту C++. Подпишитесь на хороший журнал по C++ и подключитесь к хорошей группе шовостейпользователейC++. Не рекомендуется:Не ограничивайтесь при освоении C++ только чтением чужих программ. Лучший способ изучения языка — самому писать программы. РезюмеСегодня вы узнали много подробностей о работе с препроцессором. При каждом запуске компилятора сначала запускается препроцессор, который расшифровывает и выполняет такие директивы, как #define и #ifdef. Препроцессор осуществляет текстовую подстановку, хотя использование макросов может несколько усложнить чтение программы. С помощью таких директив, как #ifdef, #else и #ifndef, можно выполнять условную компиляцию, которая позволяет компилировать один набор команд при одних условиях, и другой — при других условиях. Благодаря этому можно писать программы сразу для нескольких платформ и успешно выполнять их отладку. Макросы обеспечивают сложную текстовую подстановку на основе параметров, передаваемых им во время компиляции программы. Чтобы гарантировать правильное выполнение подстановки, каждый параметр макроса нужно заключить в круглые скобки. В C++ макросы, в частности и препроцессор, вообще несут на себе меньшую нагрузку, чем это было в языке С. В C++ предусмотрен ряд таких средств программирования, как ключевое слово const и шаблоны, которые предлагают лучшие альтернативы использованию препроцессора. Кроме того, вы узнали, как устанавливать и возвращать значения отдельных битов и как выделять ограниченное число битов для переменных-членов класса. Наконец, вы получили информацию о стиле написания программы на языке C++, а также о том, с помощью каких первоисточников лучше продолжить изучение C++. Вопросы и ответыЕсли C++ предлагает лучшие решения, чем препроцессор, почему же эти средства все еще доступны? Во-первых, язык C++ совместим с языком С, поэтому все существенные компоненты языка С должны поддерживаться в C++. Во-вторых, некоторые возможности препроцессора все еще используются в C++, например защита от повторного включения файла. Зачем использовать макросы там, где можно использовать обычные функции? Макросы вставляются компилятором прямо в код программы, что ускоряет их выполнение. Кроме того, с помощью макросов можно динамически менять типы в объявлениях, хотя использовать для этого шаблоны предпочтительнее. В каких случаях лучше использовать макрос, чем подставляемую функцию? Часто это не имеет большого значения, поэтому используйте тот вариант, который кажется вам проще. Однако макросы предоставляют такие дополнительные возможности, как замена символов, взятие в кавычки и конкатенация. Ни одна из этих возможностей не реализуется с помощью подставляемой функции. Какая альтернатива использованию препроцессора для печати промежуточных значений в процессе отладки? Лучше всего использовать оператор watch внутри отладчика. За информацией о его использовании обращайтесь к документации, прилагаемой к вашему компилятору или отладчику. Когда лучше использовать макрос assert(), а когда — исключение? Если ошибка в выполнении программы может возникнуть из-за внешних причин, таких как некорректный ввод данных пользователем или несовершенство компьютерной системы, используйте исключения. Если же сбой программы возникает вследствие синтаксических или логических ошибок в коде программы, используйте макрос assert(). Когда лучше использовать битовые поля вместо обычных переменных? Когда критическим фактором становится размер объектов. При работе с ограниченным объемом памяти или с программным обеспечением устройств связи вы почувствуете, что экономия на каждом байте существенна для успеха вашей программы. Почему споры о стилях столь эмоциональны? Программисты очень привязываются к выработанному ими стилю. Допустим, вы привыкли использовать отступы следующим образом: if (НекотороеУсловие){ // выражения } // закрывающая фигурная скобка Согласитесь, что вам будет трудно отказаться от этой привычки — ведь новые стили кажутся поначалу неправильными и вводящими в заблуждение. Если вы устали от моих советов, попробуйте подключиться к популярной группе новостей и узнайте, какой стиль выравнивания работает лучше всего, какой редактор предпочтительнее для C++ или какую программу лучше всего использовать в качестве текстового процессора. Затем усаживайтесь поудобнее и приготовьтесь прочитать тысяч десять противоречащих друг другу сообщений. Пришло время прощаться? Да! Вы изучили C++, хотя... нет. Еще десять лет назад один человек мог изучить все, что было известно в мире о микро ЭВМ, или, по крайней мере, чувствовать себя вполне уверенно в этом вопросе. Сегодня это исключено даже теоретически. Одному человеку невозможно разобраться во всем, и даже за то время, пока вы попытаетесь это сделать, ситуация в индустрии программирования изменится, а значит, вы опять отстанете от нее. Тем не менее обязательно продолжайте читать, постоянно обращайтесь к различным источникам — журналам и группам новостей, которые будут держать вас в курсе самых последних новшеств в этой области. КоллоквиумКонтрольные вопросы1. Для чего нужны средства защиты от повторного включения? 2. Как указать компилятору, что необходимо напечатать содержимое промежуточного файла, полученного в результате работы препроцессора? 3. Какова разница между директивами #define debug 0 и #undef debug? 4. Что делает оператор дополнения до единицы? 5. Чем отличается оператор побитового ИЛИ от оператора исключающего побитового ИЛИ? 6. Какова разница между операторами & и &&? 7. В чем разница между операторами | и || ? Упражнения1. Создайте защиту от повторного включения файла заголовка STRING, н. 2. Напишите макрос assert(), который • будет печатать сообщение об ошибке, а также имя файла и номер строки, если уровень отладки равен 2; • будет печатать сообщение (без имени файла и номера строки), если уровень отладки равен 1; • не будет ничего делать, если уровень отладки равен 0. 3. Напишите макрос DPrint, который проверяет, определена ли лексема DEBUG, и, если да, выводит значение, передаваемое как параметр. 4. Напишите программу, которая складывает два числа без использования операции сложения (+). Подсказка: используйте побитовые операторы! Подведение итоговВ приведенной ниже программе используются многие "продвинутые" методы, с которыми вы познакомились на протяжении трех недель усердных занятий. Программа содержит связанный список, основанный на шаблоне; кроме того, в ней проводится обработка исключительных ситуаций. Тщательно разберитесь в этой программе, и, если полностью ее поймете, значит, вы — программист C++. Предупреждение:Если ваш компилятор не поддерживает шаблоны или блоки try и catch, вы не сможете скомпилировать эту программу. Листинг 3.1. Программа, основанная на материалах недели 3 1: // ************************************ 2: // 3: // Название: Обзор недели 3 4: // 5: // Файл: Week3 6: // 7: // Описание: Программа с использованием связанного списка 8: // на основе шаблона с обработкой исключительных ситуаций 9: // 10: // Классы: PART - хранит номера запчастей и потенциально другую 11: // информацию о запчастях. Зто будет 12: // пример класса для хранения списка. 13: // Обратите внимание на использование 14: // оператора << для печати информации о запчасти 15: // на основе его типа и времени выполнения, 16: // 17: // Node - действует как узел в классе List 18: // 19: // List - список, основанный на шаблоне, который 20: // обеспечивает работу связанного списка 21: // 22: // 23: // Автор: Jesse Liberty (jl) 24: // 25: // Разработан: Pentium 200 Pro. 128MB RAM MVC 5.0 26: // 27: // Требования: Не зависит от платформы 28: // 29: // История создания: 9/94 - Первый выпуск (jl) 30: // 4/97 - Обновлено (jl) 31: // ************************************ 32: 33: #include <iostream.h> 34: 35: // классы исключений 36: class Exception { }; 37: class OutOfMemory : public Exception{ }; 38: class NullNode : public Exception{ }; 39: class EmptyList : public Exception { }; 40: class BoundsError : public Exception { }; 41: 42: 43: // **************** Part ************** 44: // Абстрактный базовый класс запчастей 45: class Part 46: { 47: public: 48: Part():its0bjectNumber(1) { } 49: Part(int 0bjectNumber):its0bjectNumber(ObjectNumber){ } 50: virtual ~Part(){ }; 51: int GetObjectNumber() const { return itsObjectNumber; } 52: virtual void Display() const =0; // функция будет замещена в производном классе 53: 54: private: 55: int itsObjectNumber; 56: }; 57: 58: // выполнение чистой виртуальной функции, необходимой 59: // для связывания объектов производного класса 60: void Part::Display() const 61: { 62: cout << "\nPart Number: " << itsObjectNumber << endl; 63: } 64: 65: // Этот оператор << будет вызываться для всех объектов запчастей. 66: // Его не нужно объявлять другом, поскольку он не обращается к закрытым данным. 67: // Он вызывает метод Display(), в результате чего реализуется полиморфизм классов. 68: // Было бы не плохо замещать функцию оператора для разных 69: // типов thePart, но C++ не поддерживает контравариантность 70: ostream& operator<<( ostream& theStream,Part& thePart) 71: { 72: thePart.Display(); // косвенная реализация полиморфизма оператора вывода! 73: return theStream; 74: } 75: 76: // **************** Car Part ************ 77: class CarPart : public Part 78: { 79: public: 80: CarPart():itsModelYear(94){ } 81: CarPart(int year, int partNumber); 82: int GetModelYear() const { return itsModelYear; } 83: virtual void Display() const; 84: private: 85: int itsModelYear; 86: }; 87: 88: CarPart::CarPart(int year, int partNumber): 89: itsModelYear(year), 90: Part(partNumber) 91: { } 92: 93: void CarPart::Display() const 94: { 95: Part::Display(); 96: cout << "Model Year: " << itsModelYear << endl; 97: } 98: 99: // **************** AirPlane Part ************ 100: class AirPlanePart : public Part 101: { 102: public: 103: AirPlanePart():itsEngineNumber(1){ } ; 104: AirPlanePart(int EngineNumber, int PartNumber); 105: virtual void Display() const; 106: int GetEngineNumber()const { return itsEngineNumber; } 107: private: 108: int itsEngineNumber; 109: }; 110: 111: AirPlanePart::AirPlanePart(int EngineNumber, int PartNumber): 112: itsEngineNumber(EngineNumber), 113: Part(PartNumber) 114: { } 115: 116: void AirPlanePart::Display() const 117: { 118: Part::Display(); 119: cout << "Engine No,: " << itsEngineNumber << endl; 120: } 121: 122: // Обьявление класса List 123: template <class T> 124: class List; 125: 126: // **************** Node ************ 127: // Общий узел, который можно добавить к списку 128: // ********************************** 129: 130: template <class T> 131: class Node 132: { 133: public: 134: friend class List<T>; 135: Node (T*); 136: ~Node(); 137: void SetNext(Node * node) { itsNext = node; } 138: Node * GetNext() const; 139: T * GetObject() const; 140: private: 141: T* its0bject; 142: Node * itsNext; 143: }; 144: 145: // Выполнение узла... 146: 147: template <class T> 148: Node<T>::Node(T* p0jbect): 149: itsObject(pOjbect), 150: itsNext(0) 151: { } 152: 153: template <class T> 154: Node<T>::~Node() 155: { 156: delete its0bject; 157: itsObject = 0; 158: delete itsNext; 159: itsNext = 0; 160: } 161: 162: // Возвращает значение NULL, если нет следующего узла 163: template <class T> 164: Node<T> * Node<T>::GetNext() const 165: { 166: return itsNext; 167: } 168: 169: template <class T> 170: T * Node<T>::GetObject() const 171: { 172: if (itsObject) 173: return itsObject; 174: else 175: throw NullNode(); 176: } 177: 178: // **************** List ************ 179: // Общий шаблон списка 180: // Работает с любым нумерованным объектом 181: // ********************************** 182: template <olass T> 183: class List 184: { 185: public: 186: List(); 187: ~List(); 188: 189: T* Find(int & position, int 0bjectNumber) const; 190: T* GetFirst() const; 191: void Insert(T *); 192: T* operator[](int) const; 193: int GetCount() const { return itsCount; } 194: private: 195: Node<T> * pHead; 196: int itsCount; 197: }; 198: 199: // Выполнение списка... 200: template <class T> 201: List<T>::List(); 202: pHead(0), 203: itsCount(0) 204: { } 205: 206: template <class T> 207: List<T>::~List() 208: { 209: delete pHead; 210: } 211: 212: template <class T> 213: T* List<T>::GetFirst() const 214: { 215: if (pHead) 216: return pHead->itsObject; 217: else 218: throw EmptyList(); 219: } 220: 221: template <class T> 222: T * List<T>::operator[](int offSet) const 223: { 224: Node<T>* pNode = pHead; 225: 226: if (!pHead) 227: throw EmptyList(); 228: 229: if (offSet > itsCount) 230: throw BoundsError(); 231: 232: for (int i=0;i<offSet; i++) 233: pNode = pNode->itsNext; 234: 235: return pNode->itsObject; 236: } 237: 238: // Находим данный обьект в списке на основе его идентификационного номера (id) 239: template <class T> 240: T* List<T>::Find(int & position, int 0bjectNumber) const 241: { 242: Node<T> * pNode = 0; 243: for (pNode = pHead, position = 0; 244: pNode!=NULL; 245: pNode = pNode->itsNext, position++) 246: { 247: if (pNode->itsObject->GetObjectNumber() == 0bjectNumber) 248: break; 249: } 250: if (pNode == NULL) 251: return NULL; 252: else 253: return pNode->itsObject; 254: } 255: 256: // добавляем в список, если номер объекта уникален 257: template <class T> 258: void List<T>::Insert(T* pObject) 259: { 260: Node<T> * pNode = new Node<T>(p0bject); 261: Node<T> * pCurrent = pHead; 262: Node<T> * pNext = 0; 263: 264: int New = p0bject->Get0bjectNumber(); 265: int Next = 0; 266: itsCount++; 267: 268: if (!pHead) 269: { 270: pHead = pNode; 271: return; 272: } 273: 274: // если номер текущего объекта меньше номера головного, 275: // то этот объект становится новым головным узлом 276: if (pHead->itsObject->GetObjectNumber() > New) 277: { 278: pNode->itsNext = pHead; 279: pHead = pNode; 280: return; 281: } 282: 283: for (;;) 284: { 285: // если нет следующего обьекта, добавляем в конец текущий объект 286: if (!pCurrent->itsNext) 287: { 288: pCurrent->itsNext = pNode; 289: return; 290: } 291: 292: // если данный объект больше текущего, но меньше следующего, 293: // то вставляем его между ними, в противном случае переходим к следующему объекту 294: pNext = pCurrent->itsNext; 295: Next = pNext->itsObject->GetObjectNumber(); 296: if (Next > New) 297: { 298: pCurrent->itsNext = pNode; 299: pNode->itsNext = pNext; 300: return; 301: } 302: pCurrent = pNext; 303: } 304: } 305: 306: 307: int main() 308: { 309: List<Part> theList; 310: int choice; 311: int ObjectNumber; 312: int value; 313: Part * pPart; 314: while (1) 315: { 316: cout << "(0)Quit (1)Car (2)Plane: "; 317: cin >> choice; 318: 319: if (!choice) 320: break; 321: 322: cout << " New PartNumber?: "; 323: cin >> ObjectNumber; 324: 325: if (choice == 1) 326: { 327: cout << "Model Year?: "; 328: cin >> value; 329: try 330: { 331: pPart = new CarPart(value,ObjectNumber); 332: } 333: catch (OutOfMemory) 334: { 335: cout << "Not enough memory; Exiting..." << endl; 336: return 1; 337: } 338: } 339: else 340: { 341: cout << "Engine Number?: "; 342: cin >> value; 343: try 344: { 345: pPart = new AirPlanePart(value,ObjectNumber); 346: } 347: catch (OutOfMemory) 348: { 349: cout << "Not enough memory: Exiting..." << endl; 350: return 1; 351: } 352: } 353: try 354: { 355: theList.Insert(pPart); 356: } 357: catch (NullNode) 358: { 359: cout << "The list is broken, and the node is null!" << endl; 360: return 1; 361: } 362: catch (EmptyList) 363: { 364: cout << "The list is empty!" << endl; 365: return 1; 366: } 367: } 368: try 369: { 370: for (int i = 0; i < theList.GetCount(); i++ ) 371: cout << *(theList[i]); 372: } 373: catch (NullNode) 374: { 375: cout << "The list is broken, and the node is null!" << endl; 376: return 1; 377: } 378: catch (EmptyList) 379: { 380: cout << "The list is empty!" << endl; 381: return 1; 382: } 383: catch (BoundsError) 384: { 385: cout << "Tried to read beyond the end of the list!" << endl; 386: return 1; 387: } 388: return 0; 389: } Результат: (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 2837 Model Year? 90 (0)Quit (1)Car (2)Plane: 2 New PartNumber?: 378 Engine Number?: 4938 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 4499 Model Year? 94 (0)Quit (1)Car (2)Plane: 1 New PartNumber?: 3000 Model Year? 93 (0)Quit (1)Car (2)Plane: 0 Part Number: 378 Engine No. 4938 Part Number: 2837 Model Year: 90 Part Number: 3000 Model Year: 93 Part Number 4499 Model Year: 94 Анализ: Итоговая программа, основанная на материале за неделю 3, — это модификация программы, приведенной в обзорной главе по материалам за неделю 2. Изменения заключались в добавлении шаблона, обработке объекта ostream и исключительных ситуаций. Результаты работы обеих программ идентичны. В строках 36—40 объявляется ряд классов исключений. В этой программе используется несколько примитивная обработка исключительных ситуаций. Классы исключений не содержат никаких данных или методов, они служат флагами для перехвата блоками catch, которые выводят простые предупреждения, а затем выполняют выход. Более надежная программа могла бы передать эти исключения по ссылке, а затем извлечь контекст или другие данные из объектов исключения, чтобы попытаться исправить возникшую проблему. В строке 45 объявляется абстрактный класс Part, причем точно так же, как это было сделано в листинге, обобщающем материал за неделю 2. Единственное интересное изменение здесь — это использование оператора operator<<(), который не является членом класса (он объявляется в строках 70—74). Обратите внимание, что он не является ни членом класса запчастей Part, ни другом класса Part. Он просто принимает в качестве одного из своих параметров ссылку на класс Part. Возможно, вы бы хотели иметь замещенный оператор operator<<() для объектов классов CarPart и AirPlanePart с учетом различий в типах объектов. Но поскоДьку программа передает указатель на объект базового класса Part, а не указатель на указатель производных классов CarPart и AirPlanePart, то выбор правильной версии функции пришлось бы основывать не на типе объекта, а на типе одного из параметров функции. Это явление называется контравариантностью и не поддерживается в C++. Есть только два пути достижения полиморфизма в C++: использование полиморфизма функций и виртуальных функций. Полиморфизм функций здесь не будет работать, сигнатуры функций, принимающих ссылку на класс Part, одинаковы. Виртуальные функции также не будут здесь работать, поскольку оператор operator<< не является функцией-членом класса запчастей Part. Вы не можете сделать оператор operator<< функцией-членом класса Part, потому что в программе потребуется выполнить следующий вызов: cout << thePart Это означает, что фактически вызов относится к объекту cout.operator<<(Part&), а объект cout не имеет версии оператора operator<<, который принимает ссылку на класс запчастей Part! Чтобы обойти это ограничение, в приведенной выше программе используется только один оператор operator<<, принимающий ссылку на класс Part. Затем вызывается метод Display(), который является виртуальной функцией-членом, в результате чего вызывается правильная версия этого метода. В строках 130—143 класс Node определяется как шаблон. Он играет ту же роль, что и класс Node в программе из обзора за неделю 2, но эта версия класса Node не связана с объектом класса Part. Это значит, что данный класс может создавать узел фактически для любого типа объекта. Обратите внимание: если вы попытаетесь получить объект из класса Node и окажется, что не существует никакого объекта, то такая ситуация рассматривается как исключительная и исключение генерируется в строке 175. В строках 182—183 определяется общий шаблон класса List. Этот класс может содержать узлы любых объектов, которые имеют уникальные идентификационные номера, кроме того, он сохраняет их отсортированными в порядке возрастания номеров. Каждая из функций списка проверяет ситуацию на исключительность и при необходимости генерирует соответствующие исключения. В строках 307—308 управляющая программа создает список двух типов объектов класса Part, а затем печатает значения объектов в списке, используя стандартные потоки вывода. Если бы в языке C++ поддерживалась контравариантность, можно было бы вызывать замещенные функции, основываясь на типе объекта указателя, на который ссылается указатель базового класса. Программа, представленная в листинге 3.2, демонстрирует суть контравариантности, но, к сожалению, ее нельзя будет скомпилировать в C++. Вопросы и ответы В комментарии, содержащемся в строках 65-69 говорится, что C++ не поддерживает контравариантность. Что такое контравариантность? Контравариантностью называется возможность создания указателя базового класса на указатель производного класс. Предупреждение:ВНИМАНИЕ: Этот листинг не будет скомпилирован! Листинг 3.2. Пример контравариантности #include <iostream.h> class Animal { public: virtual void Speak() { cout << "Animal Speaks\n";} }; class Dog : public Animal { public: void Speak() { cout << "Dog Speaks\n"; } }; class Cat : public Animal { public: void Speak() { cout << "Cat Speaks\n"; } }; void DoIt(Cat*); void DoIt(Dog*); int main() { Animal * pA = new Dog; DoIt(pA); return 0; } void DoIt(Cat * с) { cout << "They passed а cat!\n" << endl; c->Speak(); } void DoIt(Dog * d) { cout << "They passed a dog!\n" << endl; d->Speak(); } Но в C++ эту проблему можно решить с помощью виртуальной функции. #include<iostream.h> class Animal { public: virtual void Speak() { cout << "Animal Speaks\n"; } }; class Dog : public Animal { public: void Speak() { cout << "Dog Speaks\n"; } }; class Cat : public Animal { public: void Speak() { cout << "Cat Speaks\n"; } }; void DoIt(Animal*); int main() { Animal * pA = new Dog; DoIt(pA); return 0; } void DoIt(Animal * с) { cout << "They passed some kind of animal\n" << endl; c->Speak(); } |
|
||
| Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх | ||||
|
|
||||