|
||||
|
|
ГЛАВА 7. ЕЩЕ НЕСКОЛЬКО ПРИМЕРОВ ПРОГРАММВ каждом разделе этой главы рассматривается некоторое конкретное применение Пролога. Мы советуем вам прочитать все разделы. Не огорчайтесь, если вы не поймете назначение какой-либо программы потому, что незнакомы с данной конкретной областью применения. Например, оценить значение символьного дифференцирования смогут лишь читатели, уже знакомые с дифференциальным исчислением. Тем не менее прочтите этот раздел, потому что программа нахождения символьных производных показывает, как установление соответствия между образцами используется при преобразовании структур одного вида (арифметическое выражение) в структуры другого вида. Самое главное – добиться понимания техники программирования на Прологе, находящейся в распоряжении программиста, независимо от конкретной прикладной задачи. Мы надеемся, что набор задач достаточен, чтобы удовлетворить вкусам большинства читателей. Естественно, что все выбранные задачи относятся к таким областям, которые хорошо укладываются в те способы представления явлений реального мира, которые предлагает Пролог. Например, здесь отсутствует задача расчета потока тепла через трубу прямоугольного сечения. Правда, такие задачи тоже можно решать с помощью Пролога, однако выразительность и силу Пролога невыгодно демонстрировать на задачах, которые сводятся лишь к многократным повторениям вычислений над массивом чисел. Хотелось бы также рассмотреть и большие Пролог-программы, вроде тех, что используются в исследованиях по искусственному интеллекту для распознавания фраз естественного языка. К сожалению, цель такой книги как эта, не позволяет рассматривать программы, размеры которых превышают страницу текста и которые могут быть предложены лишь специально подготовленному читателю. 7.1. Словарь в виде упорядоченного дереваПредположим, что мы хотим установить отношения между элементами информации с тем, чтобы использовать их, когда потребуется. Например, толковый словарь ставит в соответствие слову его определение, а словарь иностранного языка ставит в соответствие слову на одном языке слово на другом языке. Мы уже познакомились с одним способом составления словаря: с помощью задания фактов. Если нам нужно составить таблицу выигрышей на скачках, проводившихся на Британских островах в течение 1938 г., то мы можем просто определить факты вида выигрыши(Х, Y), где X - кличка лошади, a Y – количество гиней (денежных единиц), выигранных этой лошадью. Следующая база данных может рассматриваться как часть этой таблицы: Выигрыши(abaris,582). Выигрыши(careful,17). Выигрыши(jingling_silvee,300). Bыигрыши(majola,356). Если мы хотим узнать, какую сумму выиграла лошадь по кличке maloja, нам нужно просто правильно построить вопрос и Пролог даст нам ответ: ?- Bыигрыши(maloja, X). X=356 Напомним, что Пролог просматривает базу данных сверху вниз. Это значит, что если база данных нашего словаря упорядочена в алфавитном порядке, как в приведенном выше примере, то на поиск суммы выигрыша для ablaze Пролог затратит меньше времени, чем на поиск суммы выигрыша для zoltan. Однако хотя Пролог способен просмотреть свою базу данных гораздо быстрее, чем вы сможете просмотреть напечатанную таблицу, неразумно просматривать таблицу с начала до конца, если известно, что данные искомой лошади расположены в самом конце. Точно так же, хотя в Прологе имеются специальные средства быстрого просмотра базы данных, он не всегда проходит так быстро, как хотелось бы. В зависимости от размеров таблицы и от того, сколько информации хранится о каждой лошади, Прологу может потребоваться на просмотр таблицы неприемлемо большое время. По этим и другим причинам специалисты по информатике потратили немало сил на поиски хороших способов организации хранения таких данных, как таблицы и словари. Сам Пролог использует некоторые из этих методов внутри себя при организации хранения своих собственных фактов и правил, но иногда их полезно использовать и в наших программах. Мы рассмотрим один такой метод организации словаря, который называется методом упорядоченного дерева. Метод упорядоченного дерева является одновременно и эффективным способом использования словаря и средством демонстрации того, насколько полезны списки структур. 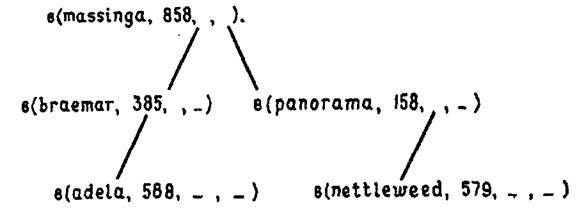 Рис. 7.1. Упорядоченное дерево состоит из некоторого числа структур, называемых узлами, причем каждому входу словаря соответствует один узел. Каждый узел содержит четыре компоненты. Сюда входят два связанных с узлом элемента данных, как в предикате выигрыши в вышеприведенном примере. Один из этих элементов называется ключом, его имя определяет место в словаре (кличка лошади в нашем примере). Другой элемент используется для хранения какой-либо другой информации о данном объекте (сумма выигрыша в нашем примере). Кроме того, каждый узел содержит ссылку (наподобие ссылки на хвост списка) на узел со значением ключа, которое лексикографически (по алфавиту) меньше, чем имя, являющееся ключом данного узла, а также еще одну ссылку на узел со значением ключа лексикографически большим, чем имя, являющееся ключом данного узла. Будем использовать структуру, которую обозначим как в(Л,В,М, Б) (в - сокращение от «выигрыши»), где Л – кличка лошади (атом), используемая в качестве ключа, В – сумма выигрыша в гинеях (целое), М – структура, соответствующая лошади, кличка которой меньше, чем та, что хранится в Л, а Б – структура, соответствующая лошади, кличка которой больше, чем значение в Л. Когда для М и Б нет соответствующих структур, мы не будем их конкретизировать. Для небольшого множества лошадей указанная структура, будучи записанной в виде дерева, могла бы иметь вид, как представлено на рис. 7.1. Если записать ее на Прологе в ступенчатом виде, учитывая ширину страницы, то она могла бы выглядеть так: в(massinga,858, в(braermar,385, в(adela,588,_,_), _), в(panorama,158, в(nettleweed,579,_,_), _). ). Теперь, располагая такой структурой, мы хотим «просмотреть» ее по кличкам лошадей, чтобы узнать их выигрыши в течение 1938 г. Как и раньше, структура должна иметь формат в(Л,В,М, Б). Условие окончания поиска состоит в том, что кличка искомой лошади должна совпасть с Л. В этом случае поиск удачен и не требуется пробовать другие варианты. В противном случае мы должны использовать предикат меньше, определенный в гл. 3, чтобы определить, какую из «ветвей» дерева, М или Б, нужно рекурсивно просмотреть. Мы используем эти принципы при определении предиката искать, причем искать(Л,Т, Г) означает, что лошадь Л, если она найдена в таблице Т (которая организована в виде структуры формата в), выиграла Г гиней: искать (Л, в(Л,Г,_,),Г):- !. искать Л, в(Л1,_,До,_),Г):-меньше(Л,Л1),искать(Л,До,Г). искать(Л, в(Л1,_,_,После),Г):- not (меньше(Л,Л1)), искать(Л,После,Г). Если при поиске по упорядоченному дереву использовать этот предикат, то в общем случае проверок будет меньше, чем если бы их данные были организованы в виде простого списка и просматривались бы с начала до конца. Предикат искать обладает одним интересным и удивительным свойством: когда вводим вопрос о лошади, клички которой нет в структуре, то любая информация, содержащаяся в вопросе, остается зафиксированной в этой структуре после окончания поиска. Иными словами, вопрос ?- искать(ruby_vintage,S,X). имеет следующую интерпретацию: построить структуру в, в которой кличке ruby_vintage поставлен в соответствие выигрыш X, и присвоить ее в качестве значения переменной S. Таким образом, искать осуществляет вставку новых компонент в частично заданную структуру. Поэтому многократно обратившись к искать, можно построить словарь. Например, вопрос ?- искать(abaris,X,582), искать(maloja,X,356). привел бы к тому, что значение переменной X стало упорядоченным деревом из двух вхождений. Понять то, каким образом искать одновременно выполняет и создание и выборку компонент, можно на основе тех знаний о Прологе, которыми вы уже располагаете; мы настоятельно рекомендуем разобраться в этом самостоятельно. Подсказка: если искать(Л,Т, Г) используется в конъюнкции целей, то «изменения» в структуре Т сохраняются только в области определения Т. Упражнение 7.1. Поэкспериментируйте с предикатом искать, чтобы установить, какие различия будут в словаре, если элементы в него вставлять каждый раз в разном порядке. Например, как будет выглядеть дерево словаря, если вставлять его элементы в таком порядке: massinga, braemar nettleweed, panorama? А если в таком порядке: adela, braemar, nettleweed, massinga? 7.2. Поиск в лабиринтеСтоит темная грозовая ночь. Когда вы ехали по пустынной сельской дороге, ваша машина сломалась и вы оказались перед входом сказочного дворца. Вы подошли к двери, обнаружили, что она открыта, и стали искать телефон. Как нужно осматривать дворец, чтобы не заблудиться и быть уверенным, что вы осмотрели каждую комнату? И каков кратчайший путь к телефону? Именно для таких крайних обстоятельств и разработаны методы поиска в лабиринте. Во многих программах для ЭВМ, подобных программам поиска в лабиринте, полезно вести информационные списки и просматривать нужный список, когда впоследствии понадобится некоторая информация. Например, если мы решили найти во дворце телефон, нам может понадобиться список уже осмотренных комнат. Чтобы не плутать, снова и снова заходя в те же самые комнаты, нам нужно просто записывать на листке бумаги номера комнат, где мы уже побывали. Перед тем, как войти в комнату, мы проверяем, нет ли ее номера на нашем листке. Если он есть, мы пропускаем эту комнату, потому что уже должны были побывать там раньше. Если номера этой комнаты нет на листке, то мы записываем ее номер и входим в комнату, и так до тех пор, пока не найдем телефон. Этот метод нуждается в некоторых уточнениях, но мы сделаем их позднее, при обсуждении проблем поиска на графе. А сначала давайте запишем по порядку наши шаги, чтобы знать, какие задачи предстоит решать: 1. Подойти к двери какой-либо комнаты. Если номер комнаты есть в нашем списке, то перейти к шагу 1. 2. Если в поле зрения нет ни одной комнаты, то «вернуться назад» через ту комнату, через которую мы прошли сюда, и посмотреть, нет ли возле нее каких-либо других комнат. 3. Иначе дописать номер комнаты к нашему списку. 4. Поискать телефон в этой комнате. 5. Если телефона нет, то перейти к шагу 1. Иначе мы останавливаемся, и наш список содержит путь, который мы прошли, чтобы попасть в нужную комнату. Будем считать, что номера комнат являются константами (безразлично целыми числами или атомами). Сначала мы можем решить, как просматривать номера комнат, записанные на листке бумаги. Для этого можно использовать предикат принадлежит, определенный в разд. 3.3, полагая, что содержимое листка бумаги представлено в виде списка. Теперь мы можем продвинуться в решении задачи поиска в лабиринте. Рассмотрим небольшой пример, где задан план дома, комнаты которого помечены буквами (см. рис. 7.2). Заметим, что просветы в стенах обозначают двери и что комната а – это просто представление пространства вне дома. Имеются двери, ведущие из а в b, из с в d, из f в е, и так далее. Сведения о том, где имеются двери, могут быть представлены в виде фактов Пролога: д(а,b). д(b,е). д(b,с). д(d,c). д(c,d). д(e,f). д(g,e). 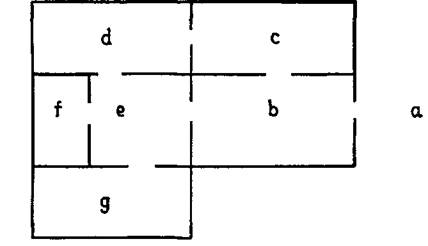 Рис. 7.2. Заметим, что информация о наличии дверей не избыточна. Например, мы сказали, что имеется дверь, ведущая из комнаты g в комнату е, но не сказали, что имеется дверь, ведущая из комнаты е в комнату g, т. е. мы не зафиксировали утверждение д(e,g). Чтобы обойти эту проблему представления двухсторонних дверей, мы могли бы повторно записать д-факт для каждой двери с перестановкой аргументов. Или мы могли бы устроить программу таким образом, чтобы она понимала, что каждая дверь фактически может рассматриваться как двухсторонняя. Этот вариант мы и выбрали в нижеследующей программе. Чтобы перейти из одной комнаты в другую, мы должны распознать один из следующих случаев: • мы находимся в той комнате, которая нам нужна, или • мы должны войти в дверь и распознать эти случаи снова (рекурсивно). Рассмотрим целевое утверждение переход(X,Y,T), которое доказуемо (согласуется с базой данных), если можно перейти из комнаты X в комнату Y. Третий аргумент Т – это наш листок бумаги, который мы носим с собой и на котором записан перечень номеров комнат, в которых мы побывали до сего момента. Граничное условие перехода из комнаты X в комнату Y состоит в том, что, возможно, мы уже находимся в комнате Y (т. е., возможно, X есть Y). Это условие представлено в виде утверждения: переход(Х,Х,Т). В противном случае мы выбираем некоторую смежную комнату, назовем ее Z, и смотрим, были ли мы в ней раньше. Если нет, то «переходим» из Z в Y, дописывая Z в наш список. Все это выражается в виде следующего утверждения: переход(Х, Y,T,):- Д(Х,Z),not(принадлежит(Z,Т)), переход(Z,Y,[Z|T]). Словами это может быть выражено так: для того чтобы «перейти» из X в Y, не проходя через комнаты из списка Т, надо найти дверь из X куда-либо (т. е. в Z), убедиться, что Z еще не занесена в список Т, и «перейти» из Z в Y, используя список Т с дописанной в него Z. При использовании этого правила существуют три возможности возникновения ошибки: во-первых, если в X вообще нет двери. Во-вторых, если дверь, которую мы выбрали, уже есть в списке. В-третьих, если «переход» в комнату Z приведет в тупик на следующих уровнях. Если первое целевое утверждение д(X, Z) не согласуется с базой данных, то и данное целевое утверждение переход также недоказуемо. На «самом верхнем» уровне (не рекурсивный вызов) это означает, что из X в Y нет пути; на более глубоких уровнях это означает, что мы должны сделать «шаг назад» и поискать другую дверь. Наша программа рассматривает каждую дверь как одностороннюю. Если мы считаем, что наличие двери из комнаты а в комнату b – это то же самое, что наличие двери из комнаты b в комнату а, то, как отмечалось выше, мы должны указать это явно. Кроме повторного задания д-фактов с перестановкой аргументов, имеются два способа задать эту информацию в самой программе. Самый очевидный способ – это добавить еще одно правило, получая в итоге: переход(Х,X,T). переход(X,Y,T):- д(X,Z), not(принадлежит(Z,Т)),переход(Z,Y[Z|T]). переход(Х,Y,T):- д(Z,Х), not(принадлежит(Z,Т)),пeреход(Z,Y,[Z|T]). Или, используя предикат ';' (обозначающий дизъюнкцию), можно записать: переход(Х,Х,Т). переход(Х,Y,T):- (д(Х,Z); д(Z,Х)), not(принадлежит (Z,T)),пepexод(Z,Y,[Z|T]). Теперь о том, как найти телефон. Рассмотрим целевое утверждение есть_телефон(X), которое согласуется с базой данных, если в комнате X есть телефон. Если мы хотим сказать, что в комнате g есть телефон, то мы просто записываем в нашу базу данных факт есть_телефон(g). Предположим, мы начали поиск с комнаты а. Один из способов узнать дорогу к телефону – это задать вопрос: ?- переход(а,Х,[]), есть_телефон(X). Это – вопрос типа «создать и проверить», который находит достижимые комнаты и затем проверяет наличие в них телефона. Другой способ – это найти сопоставление сначала для предиката есть_телефон(Х), а затем попробовать перейти из комнаты а в X: ?- есть_телефон(Х), переход(а,Х,[]). Последний метод более эффективен, однако он подразумевает что мы «знаем», где телефон, еще до того, как начали поиск. Начальная установка третьего аргумента пустым списком означает, что мы начинаем поиск, имея чистый лист бумаги. Изменяя эту начальную установку, можно получить разные варианты поиска. Вопрос «найти телефону не заходя в комнаты d и f» можно выразить на Прологе так: ?- есть_телефон(X), переход (a,X,[d,f]). В разд. 7.9 мы рассмотрим некоторые общие процедуры поиска по графу, в том числе программу, находящую кратчайший путь. Упражнение 7.2. Допишите вышеприведенную программу так, чтобы она печатала такие сообщения, как «входим в комнату X» и «телефон найден в комнате Y», подставляя в них соответствующие номера комнат. Упражнение 7.3. Может ли эта программа находить альтернативные пути? Если да, то где нужно «отсечь», чтобы избежать нахождения более чем одного пути? Упражнение 7.4. Чем определяется порядок, в котором просматриваются комнаты? 7.3. Ханойские башниХанойские башни - это игра, в которой используются три штыря и набор дисков. Все диски различаются диаметром и нанизываются на штыри через отверстие в центре каждого диска. Первоначально все диски находятся на левом штыре. Цель игры состоит в том, чтобы переместить все диски на центральный штырь. Правый штырь можно использовать как «запасной» для временного размещения дисков. При каждом перемещении диска с одного штыря на другой должны соблюдаться два ограничения: перемещать можно только самый верхний диск на штыре, и, кроме того, нельзя ставить диск на другой диск меньшего размера. Многим из тех людей, которые играют в эту игру, практически никогда не удается обнаружить весьма простую стратегию, позволяющую успешно играть в Ханойские башни с тремя штырями и N дисками. Чтобы не утомлять вас поисками решения этой задачи, мы откроем его: • Граничное условие выполняется в случае, когда на исходном (левом) штыре нет дисков. • Переместить N-1 дисков с исходного штыря на запасной (правый) штырь, используя итоговый штырь как запасной; отметим, что это перемещение осуществляется рекурсивно. • Переместить один диск с исходного штыря на итоговый штырь. В этом месте наша программа будет выдавать сообщение об этом перемещении. • Наконец, переместить N-1 дисков с запасного на итоговый, используя исходный штырь в качестве запасного. Пролог-программа, реализующая данную стратегию, определяется следующим образом. Определяется предикат ханой с одним аргументом, такой, что xaной(N) означает выдачу сообщений о последовательности перемещений, когда на исходном штыре находится N дисков. Из двух утверждений предиката переместить один задает граничное условие, которое сформулировано выше, а второй – реализует рекурсивные случаи. Предикат переместить имеет четыре аргумента. Первый аргумент – это число дисков, которые нужно переместить. Три другие представляют исходный, итоговый и запасной штыри для перемещения дисков. Предикат сообщить использует предикат write для печати названий штырей, участвующих в перемещении диска. xaной(N):- переместить(N, левый,средний,правый). переместить(О,_,_,_):-!. переместить(N, А,В,С):-М is N-1,переместить(М,А,С,В),сообщить(А,В), переместить(М,С,В,А). сообщить(Х,Y):-write([переместили,диск,со,штыря,Х,на, штырь,Y]),nl. 7.4. Справочник комплектующих деталейВ главе 3 мы рассматривали программу, выдающую на печать список деталей, необходимых при сборке некоторого узла на основе справочника комплектующих деталей. В данном разделе мы усовершенствуем эту программу, будем учитывать количество деталей путем суммирования числа требуемых деталей по мере перехода от узлов к их составляющим. Кроме того, усовершенствованная программа правильно обрабатывает повторения; процедура собрать устраняет повторения при суммировании для каждой из требуемых деталей перед тем, как ответ выдается на печать. Организация базы данных справочника сходна с тем, что описано в гл. 3. Сборочный узел представлен в виде списка структур вида чис(X, Y), где X – это имя некоторой детали (простой детали или узла), a Y – необходимое количество таких деталей. Ниже перечислены все предикаты измененной программы с указанием их назначения: Деталиузла(А): выдает на печать список всех простых деталей, требующихся для сборки узла А, и количество каждой детали. Деталиузлов(N,X,P): P - это список структур чис(Дет, Кол), где Дет - это название детали, а Кол - это количество таких деталей, требующихся для сборки каждого из экземпляров узлов X. N - целое, а X – атом, представляющий название некоторой детали. Деталировка(N,S,Р): Р - это, как и выше, список структур чис, требующихся для сборки всех узлов, представленных элементами списка S; N задает число экземпляров списка S, N – целое; S – список структур чис. Собрать(Р, А): Р и А – списки структур чис. А – это список, составленный из тех же элементов, что и Р, но без повторений одной и той же детали. Причем количество каждой детали, указанное в списке А, совпадает с суммой всех повторений этой детали в списке Р. Предикат собрать мы используем для того, чтобы собрать несколько описей наборов одинаковых деталей в одну опись. Например, 3 винта, 4 шайбы и 4 винта собираются вместе, давая 7 винтов и 4 шайбы. Дособрать(Х,М, L,O,N) : L и О - это списки структур, чис, О – это список всех элементов списка L, в состав которых не входит деталь X; X – это атом, задающий название некоторой детали; N – это общее количество X в списке L, сложенное с М; М – это целое число, которое используется для суммирования количеств X в L и передается как аргумент в каждом вызове дособрать. При выходе из рекурсии, который обеспечивается выполнением граничного условия, М возвращается как N. Вывдеталейузла(Р): Р – это список структур чис, который выдается на печать по одной структуре на строке вывода. Цель put(9) выводит литеру с кодом ASCII=9, что соответствует горизонтальной табуляции. С предикатом присоединить мы уже неоднократно встречались ранее. Полностью Пролог-программа выглядит так: деталиузла(Т):-деталиузлов(1,Т,Р), co6paть(P,Q), вывдеталейузла(Q). деталиузлов(N,Х,Р):-узел(Х,S), деталировка(N,S,Р). деталиузлов(N,Х, [чис(Х,N)]):- деталь(Х). деталировка(_, [], []). деталировка(N, [чис(Х, Число) |L],T):-М is N * Число, деталиузлов(М,Х,Хдетали),деталировка (N, L,Остдетали,Т),присоединить(Хдетали,Остдетали,Т). собрать([],[]). coбpaть([чис(X,N)|R],[чис(X,Nитог)|R2]):-дособрать(Х,N,R,O,Nитог),собрать(О,R2). досo6paть(_,N,[],[],N). дособрать(Х,N,[чис(Х,Число)|Oст],Прочие,Nитог):-!,М is N+Число, дособрать(Х,М,Ост,Прочие,Nитог). дособрать(Х,N,[Друг|Ост],[Друг|Прочие],Nитог):-дособрать(Х, N, Ост, Прочие, Nитог). вывдеталейузла([]). вывдеталейузла([чис(Х,N)|R):-tab(4),write(N),put(9),write(X),nl, вывдеталейузла(R). 7.5. Обработка списковВ этом разделе мы рассмотрим некоторые основные предикаты, полезные при работе со списками. Поскольку Пролог позволяет работать с произвольными структурами данных, списки не могут играть в нем той незаменимой роли, какая им отводится в других языках программирования, таких, как Лисп и Поп-2. Однако независимо от того, будут или не будут использоваться списки в ваших программах, всегда важно представлять себе, как работают предикаты, определения которых рассматриваются в данном разделе, поскольку они основаны на принципах, которые применимы при работе с любыми структурами данных. Нахождение последнего элемента списка: Цель последний(X, L) согласуется с базой данных, если элемент X является последним элементом списка L. Граничное условие выполняется, когда список L содержит только один элемент. Это условие проверяется первым правилом. Второе правило задает общий рекурсивный случай: последний(Х,[Х]). последний(Х,[_,|Y]):- последний(Х,Y). ?- последний(Х,[talk,of,the,town]). X = town Проверка порядка следования элементов: Цель следомза(Х, Y, L) согласуется с базой данных, если элементы X и Y являются последовательными элементами списка L. Особенности работы переменных допускают, чтобы или X, или Y, или обе переменные были неконкретизированы перед попыткой согласовать цель. В первом утверждении, которое проверяет граничное условие, должно быть также предусмотрено, что после X и Y в списке могут быть другие элементы. Этим объясняется появление анонимной переменной, в которой сохраняется хвост списка: следомза(Х,Y,[Х,Y|_]). следомза(Х,Y,[_|Z]):- следомза(Х,Y,Z). Объединение списков: С приводимым примером мы уже встречались ранее в разд. 3.6. Цель присоединить(X, Y, Z) согласуется с базой данных в том случае, если Z – это список, построенный путем добавления Y в конец X. Например, ?- присоединить([a,b,с],[d,e,f],Q). Q=[a,b,c,d,e,f] Определение предиката присоединить выглядит следующим образом: присоединить([],L,L). присоединить([Х|L1],L2,[Х|LЗ]):- присоединить(L1,L2,LЗ). Граничное условие выполняется тогда, когда первый аргумент является пустым списком. Действительно, пополнение какого-либо списка пустым списком не изменяет его. В дальнейшем мы постепенно приближаемся к граничному условию, поскольку каждое рекурсивное обращение к присоединить удаляет один элемент из головы первого аргумента. Заметим, что любые два аргумента присоединить могут быть конкретизированы, и в этом случае присоединить конкретизирует третий аргумент соответствующим результатом. Этим свойством, которое можно было бы назвать «недетерминированным программированием», обладают многие из определяемых в данной главе предикатов. Указанная гибкость присоединить позволяет определить с его помощью ряд других предикатов, что мы и сделаем: последний(Е1,Список):- присоединить(_,[Е1],Список). следомза(Е11,Е12,Список):- присоединить(_,[Е11,Е12|_], Список). принадлежит(Е1,Список):- присоединить(_,[Е1|_],Список). Обращение списка: Цель обр(L,M) согласуется с базой данных, если результат перестановки в обратном порядке элементов списка L есть список М. В программе используется стандартный прием, когда обращенный список получается присоединением его головы к обращенному хвосту. Лучший способ обратить хвост – это использовать сам обр. Граничное условие выполняется тогда, когда первый аргумент сократился до пустого списка, в этом случае результатом также является пустой список: обр([],[]). обр([Н|Т],L):- обр(T,Z), присоединить(Z,[Н],L). Заметим, что на месте второго аргумента присоединить стоит Н в квадратных скобках. Причина в том, что Н – это голова первого аргумента, а голова списка сама не обязана быть списком. Хвост же списка по определению всегда является списком. Для более эффективной реализации обр мы можем встроить действия по объединению списков непосредственно в утверждения для обр: o6p2(L1,L2):- обрдоп(L1,[],L2). обрдоп([X|L],L2fL3):- обрдоп(L,[Х|L2],LЗ). обрдоп([],L,L). Второй аргумент обрдоп используется для хранения «текущего результата». Каждый раз, когда выявляется новый фрагмент результата (X), передаваемый в остальную часть программы, «текущий результат» представляет из себя старый «текущий результат», дополненный новым фрагментом X. В самом конце последний «текущий результат» возвращается в качестве результата исходного целевого утверждения. Аналогичный прием используется в разд. 7.8 при определении предиката имя_целого. Исключение одного элемента: Цель исключ1(Х, Y,Z) исключает первое вхождение элемента X из списка Y, формируя новый сокращенный список Z. Если в списке Y нет элемента X, то целевое утверждение недоказуемо. Граничное условие выполняется тогда, когда мы находим искомый элемент X, иначе осуществляется рекурсивная обработка хвоста списка Y: исключ1(А,[А|L],L):-!. исключ1(А,[В|L],[В|М]):- исключ1(А,L,М). Легко добавить утверждение, которое обеспечит доказательство предиката, когда второй аргумент сократится до пустого списка. Это утверждение, реализующее новое граничное условие, есть исключ1(_,[],[])- Исключение всех вхождений некоторого элемента; Цель исключить(Х, L1, L2) создает список L2 путем удаления всех элементов X из списка L1. Граничное условие выполняется тогда, когда L1 является пустым списком. Это означает, что мы рекурсивно исчерпали весь список. Если X находится в голове списка, то результатом является хвост этого списка, из которого X тоже удаляется. Последний случай возникает, если во втором аргументе обнаружено, что-то отличное от X. Тогда мы просто входим в новую рекурсию. исключить(_, [],[]). исключить(Х,[Х|L],М):-!, исключить(Х,L,М). исключить(Х,[Y|L1],[Y|L2]):- исключить(Х,L1,L2). Замещение: Этот предикат очень напоминает исключить, с той лишь разницей, что вместо удаления искомого элемента мы заменяем его некоторым другим элементом. Цель заменить(Х, L,A,M) строит новый список М из элементов списка L, при этом все элементы X заменяются на элементы А. Здесь возможны 3 случая. Первый, связанный с граничным условием, в точности совпадает с тем, что было в исключить. Второй случай – когда в голове второго аргумента содержится элемент X, а третий – когда там содержится нечто отличное от X: заменить(_,[],_,[]). заменить(Х,[Х|L],А,[А|М]):-!, заменить(Х,L,А,М). заменить(Х,[Y|L],А,[Y|М]):- заменить(Х,L,А,М). Подсписки: Список X является подсписком списка Y, если каждый элемент X содержится и в Y с сохранением порядка следования и без разрывов. Например, доказуемо следующее: подсписок[[собрание, членов, клуба],[общее, собрание, членов, клуба, будет, созвано, позже]). Программа подсписок требует двух предикатов: один для нахождения совпадения с первым элементом, и второй, чтобы убедиться, что остальная часть первого аргумента поэлементно совпадает с соответствующей частью второго аргумента. подсписок([Х|L],[Х|М]):- совпало(L,M),!. подсписок(L,[_|М]):- подсписок(L,M). совпало([],_). совпало([Х|L],[Х|М]):- совпало(L,М). Отображение: Это мощный метод, заключающийся в преобразовании одного списка в другой с применением к каждому элементу первого списка некоторой функции и использованием ее результата в качестве очередного элемента второго списка. Программа преобразования одного предложения в другое, которая рассматривалась в гл. 3, является одним из примеров отображения. Мы говорим, что «отображаем одно предложение в другое». Отображение настолько полезно, что заслуживает отдельного раздела. Кроме того, поскольку списки в Прологе – это просто частные случаи структур, мы отложим обсуждение отображения списков до разд. 7.12. Отображение многолико. В разд. 7.11, посвященном символическому дифференцированию, описывается способ отображения одного арифметического выражения в другие. 7.6. Представление и обработка множествМножество - одна из наиболее важных структур данных, используемых как в математике, так и в программировании. Множество – это набор элементов, напоминающий список, но отличающийся тем, что вопрос о том, сколько раз и в каком месте что-либо входит в множество в качестве его элемента, не имеет смысла. Так, множество (1, 2, 3) – это то же самое множество, что и (1, 2, 3, 1), поскольку значение имеет только сам факт, принадлежит данный элемент множеству или нет. Элементами множеств могут также быть другие множества. Самой фундаментальной операцией над множествами является определение того, принадлежит некоторый элемент данному множеству или нет. Не должно вызывать удивления, что множества удобно представлять в виде списков. Список может содержать произвольные элементы, включая другие списки, и над списками можно определить предикат принадлежности. Однако условимся, что когда мы представляем множество в виде списка, такой список содержит только по одному элементу на каждый объект, принадлежащий множеству. При работе со списками без повторяющихся элементов упрощаются некоторые операции, такие, как удаление элементов. Итак, нам предстоит иметь дело только со списками без повторяющихся элементов. Предикаты, рассматриваемые ниже, соблюдают это свойство и опираются на него. Над множествами обычно определяется следующий набор операций (мы будем применять и общепринятые математические обозначения для тех читателей, кто к ним привык): Принадлежность множеству: X∈Y X принадлежит некоторому множеству Y, если X является одним из элементов Y. Пример: а∈{с,а,t}. Включение: X⊂Y Множество Y включает в себя множество X, если каждый элемент множества X является также элементом Y. Множество Y может содержать некоторые элементы, которых нет в X. Пример: {x,r,u}⊂{p,q,r,f,t,u,v,w,x,y,z}. Пересечение: X∩Y Пересечением множеств X и Y является множество, содержащее те элементы, которые одновременно принадлежат X и Y. Пример: {r,a,p,i,d} ∩ {p,i,c,t,u,r,e} = {r,i,p}. Объединение: X ∪ Y Объединением множеств X и Y является множество, содержащее все элементы, принадлежащие X или Y или одновременно им обоим. Пример: {a,b,c} ∪ {с,d,е} = {a,b,c,d,e}. Это – основные операции, которые обычно используются при работе с множествами. Теперь мы можем приступить к написанию Пролог-программ, реализующих каждую из них. Первая основная операция 'принадлежность' реализуется тем же самым предикатом принадлежит, с которым мы уже встречались несколько раз. Однако в нашем определении принадлежит в граничном случае нет символа «отсечения», поэтому мы можем создавать последовательные элементы списка, используя возвратный ход: принадлежит(Х,[Х|_]). принадлежит(Х,[_|Y]):- принадлежит(Х,Y). Следующая операция 'включение' реализуется предикатом включает, причем включает(Х, Y) завершается успешно, если X является подмножеством Y, т. е. Y включает X. Второе утверждение в его определении опирается на математическое соглашение о том, что пустое множество является подмножеством любого множества. В Прологе это соглашение дает способ проверки граничного условия для первого аргумента, поскольку запрограммирована рекурсивная обработка его хвоста: включает([А|Х],Y):- принадлежит(А,Y), включает(Х,Y). включает([],Y). Следом идет самый сложный случай, реализация пересечения. Целевое утверждение пересечение(Х, Y,Z) доказуемо, если пересечением X и Y является Z. Это как раз тот случай, когда используется предположение, что данные списки не содержат повторяющихся элементов: пересечение([], X, []). пересечение([X|R],Y,[X|Z]):-принадлежит(Х, Y),!,пересечение(R, Y,Z). пересечение([Х|R],Y,Z):- пересечение(R, Y,Z). Наконец, объединение. Целевое утверждение объединение (X,Y,Z) доказуемо, если объединением X и Y является Z. Заметим, что реализация предиката объединение сконструирована на основе определений предикатов пересечение и присоединить: объединение([],Х,Х). объединение([Х|R],Y,Z):- принадлежит(Х,Y),!, объединение(R,Y,Z). объединение([X |R],Y,[X|Z]):- объединение(R,Y,Z). Этим исчерпывается наш перечень предикатов работы с множествами. И хотя использование множеств может оказаться не характерным для ваших программ, тем не менее полезно изучить эти примеры. Они позволяют вам получить ясное представление о том, как можно использовать рекурсию и возвратный ход. 7.7. СортировкаИногда полезно упорядочить список элементов в соответствии с заданным порядком их следования. Если элементами списка являются целые числа, то для того чтобы определить соблюден ли порядок следования, можно использовать предикат '‹'. Список (1, 2, 3) упорядочен, поскольку любая пара соседних целых чисел этого списка удовлетворяет предикату '‹'. Если элементами списка являются атомы, то мы можем воспользоваться предикатом меньше, о чем уже говорилось в гл. 3. Список [alpha,beta,gamma] упорядочен в алфавитном порядке, поскольку каждая пара соседних атомов этого списка удовлетворяет предикату меньше. Специалисты по информатике разработали много методов сортировки списков, когда задан некоторый предикат, который говорит нам о том, находятся ли соседние элементы списка в требуемом порядке следования. Мы рассмотрим Пролог-программы для четырех таких методов: наивная сортировка, сортировка включением (вставками), сортировка методом пузырька и быстрая сортировка. В каждой программе используется предикат упорядочено, который может быть определен через '‹' меньше или любой другой предикат по вашему усмотрению, в зависимости от того, какого рода структуры вы сортируете. При этом предполагается, что целевое утверждение упорядочено(Х, Y) доказуемо, если объекты X и Y удовлетворяют требуемому порядку следования, т. е. если X в некотором смысле меньше чем Y. Один из способов сортировки чисел в порядке возрастания состоит в следующем: вначале создается некоторая перестановка чисел, затем проверяется расположен ли полученный список в порядке возрастания. Если это не так, то создается новая перестановка чисел. Этот метод известен под названием наивная сортировка: наивсорт(L1,L2):- перестановка(L1,L2),отсортировано(L2),!. перестановка(L,[H|T]):-присоединить(V,[Н|U],L), присоединить(V,U,W), перестановка(W,Т). перестановка([],[]). отсортировано(L):- отсортировано(0,L). отсортировано(_,[]). отсортировано(N,[H|T]):- упорядочено(N,Н),отсортировано(Н,T). Используемый здесь предикат присоединить многократна определялся ранее. В этой программе предикаты имеют следующий смысл: Наивсорт(L1, L2) означает, что L2 – это список, являющийся упорядоченной версией списка L1; Перестановка(L1, L2) означает, что L2- это список, содержащий все элементы списка L1 в одном из многих возможных порядков их следования; в терминологии разд. 4.3 – это генератор. Предикат отсортировано(L) означает, что числа в списке L упорядочены в порядке возрастания; это – 'контролер'. Процесс поиска упорядоченной версии списка заключается в создании некоторой перестановки элементов и проверки ее упорядоченности. Если это так, то единственный ответ найден. Иначе мы вынуждены продолжать создание перестановок. Это не очень эффективный метод сортировки списка. При сортировке включением каждый элемент списка рассматривается отдельно и включается в новый список на соответствующее место. Этот метод используется, например, при игре в карты, когда игрок сортирует имеющиеся на руках карты, вынимая и переставляя по одной карте за раз. Целевое утверждение вклюсорт(X, Y) доказуемо тогда, когда список Y является упорядоченной версией списка X. Каждый элемент удаляется из головы списка и передается предикату вклюсорт2, который включает этот элемент в список и возвращает измененный список. вклюсорт([],[]). вклюсорт([Х|L],М):- вклюсорт(L,N), вклюсорт2(Х,N,М). вклюсорт2(Х,[А|L],[А|М]):- упорядочено(А,Х),!,вклюсорт2(Х,L,М). вклюсорт2(Х,L,[Х |L]). Чтобы сделать предикат сортировки включением более универсальным, удобно задавать предикат проверки порядка следования в качестве аргумента предиката вклюсорт. Используем для этого предикат ' =..', который рассматривался в гл. 6: вклюсорт([],[],_). вклюсорт([Х|L],М,О):- вклюсорт(L,N,О),вклюсорт2(Х,N,М,О). вклюсорт2(Х,[А|L],[А|М],0):-Р=..[O,А,Х], call(P),!, вклюсорт2(Х,L,М,O). вклюсорт2(Х,L,[Х|L],О). Теперь мы можем использовать такие цели как вклюсорт(А,В,'‹') и вклюсорт(А,В,меньше), т. е. отпадает необходимость в предикате упорядочено. Этот метод может быть распространен.и на другие алгоритмы сортировки данного раздела. При сортировке методом пузырька в списке ищется пара соседних элементов, расположенных не по порядку следования. Если такие элементы находятся, то они меняются местами. Этот процесс продолжается до тех пор, пока перестановки станут ненужными. Если при сортировке включением выбранный элемент как бы «тонет», попадая на нужное место, то сортировка методом пузырька названа так потому, что здесь элементы, подобно пузырькам воздуха, постепенно «всплывают», занимая соответствующее место. пусорт(L,S):-присоединить(Х,[А,В|Y],L),упорядочено(В,А),присоединить(Х, [В, А|Y],M),пусорт(M,S). пусорт(L,L). присоединить([],L,L). присоединить([Н|Т],L[Н|V]):- присоединить(Т,L,V). Заметим, что здесь применяется тот же самый предикат присоединить, с которым мы встречались ранее. Этот пример отличается от предыдущих необходимостью возвратного хода после каждого найденного решения. Поэтому в первом правиле в определении пусорт «отсечение» не используется. Эта программа еще один пример «недетерминированного» программирования,- для выбора элементов списка L здесь используется предикат присоединить. При этом контроль полноты выполненных перестановок целиком возложен на присоединить. Быстрая сортировка - это более сложный метод сортировки, предложенный Хоором и применимый для сортировки больших списков. Для реализации быстрой сортировки на Прологе мы должны сначала разделить список, состоящий из головы Н и хвоста Т, на два списка L и М такие, что: • все элементы L меньше или равны Н; • все элементы М больше чем Н; • порядок следования элементов в L и М такой же как в [Н |Т]. После того, как мы разделили список, применяем быструю сортировку к каждому из полученных списков (это рекурсивная часть), и присоединяем М к L Цель разбить(H,T,L,M) разделяет список [Н |Т] на списки L и М, как сказано выше: paзбить(H,[A|X],[A|Y],Z):- А=‹ Н, разбить(Н,Х,Y,Z). разбить(Н,[А|Х],Y,[А|Z]):- А › Н, разбить(Н,Х,Y,Z). разбить(_,[], [],[]). Тогда программа быстрой сортировки примет вид: бысорт([],[]). бысорт([H|T],S):-разбить(Н,Т,А,В),бысорт(А,А1),бысорт(В,В1), присоединить(А1, [H|B1],S). Предикат присоединить можно встроить внутрь программы сортировки. Тогда получается другой предикат бысорт2 ([H|T], S,X):-разбить(Н,T,А,В), бысорт2(А,S,[Н|Y]), бысорт2(B,Y,X). бысорт2([],Х,Х). В этом случае третий аргумент используется как временная рабочая область, и при обращениях к бысорт2 этот аргумент должен заполняться пустым списком. Более подробные сведения о методах сортировки можно найти в книге D. Knuth, The Art of Computer Programming, v. 3 (Sort and Searching), Addison-Wesley, 1973 (Имеется перевод: Кнут Д. Искусство программирования для ЭВМ, т. 3 (Сортировка и поиск). М.: Мир, 1978.- Перев.) Метод быстрой сортировки Хоора описан в его статье в Computer Journal n. 5 (1962), стр. 10-15. Упражнение 7.5. Проверьте, что предикат перестановка (L1, L2) строит все перестановки заданного списка L1 (причем каждую по одному разу) и выдает их как альтернативные значения списка L2. В каком порядке строятся эти решения? Упражнение 7.6. Быстрая сортировка лучше всего работает ка больших списках, поскольку там она обеспечивает более быструю сходимость к решению. В то же время объем работы, выполняемой на каждом уровне рекурсии быстрой сортировки, превышает то, что делается в других методах, из-за использования разбить. Поэтому, при сортировке небольших списков рекурсивные вызовы бысорт, видимо, можно заменить обращениями к другим методам сортировки, например, к сортировке включением. Разработайте «гибридную» программу, которая использует быструю сортировку для обработки больших подсписков (списков, полученных с помощью предиката разбить), но переключается на другой метод (сортировка включением) при значительном уменьшении длины подсписка. Подсказка: поскольку разбить должен просмотреть все элементы списка, то он может заодно подсчитать и длину списка. 7.8. Использование базы данных: random, генатом, найтивсеВо всех программах, которые рассматривались до сих пор, база данных использовалась лишь для хранения фактов и правил, с помощью которых определяются предикаты. Можно использовать базу данных и для хранения обычных структур, т. е. таких, которые порождаются при выполнении программы. До сих пор для передачи таких структур от одного предиката к другому мы применяли механизм аргументов. Однако существуют доводы в пользу хранения этой информации в базе данных. Иногда некоторый элемент информации может потребоваться во многих частях программы. Передача его через механизм аргументов может привести к появлению одного – двух дополнительных аргументов у большинства предикатов. Другим доводом является возможность сохранения информации при возвратном ходе. В этом разделе мы рассмотрим три предиката, которые позволяют хранить в базе данных структуры, время жизни которых превышает то, что может быть обеспечено с помощью переменных. Вот эти три предиката: random, вырабатывающий при каждом вызове псевдослучайное целое, найтивсе, порождающий список всех структур, обеспечивающих истинность данного предиката, и генатом, порождающий атомы с различающимися именами. Генератор случайных чисел (random)Цель random(R, N) конкретизирует N целым числом, случайно выбранным в диапазоне от 1 до R. Метод выбора случайного числа основан на конгруэнтном методе с использованием начального числа («затравки») инициализируемого произвольным целым числом. Каждый раз, когда требуется случайное число, ответ вычисляется на основе существующего начального значения, и при этом порождается новое начальное число, которое сохраняется до тех пор, пока вновь не потребуется вычислить случайное число. Для хранения начального числа между вызовами random мы используем базу данных. После того как начальное число использовано, мы убираем (с помощью retract) из базы данных старую информацию о начальном числе, вычисляем его новое значение, и засылаем в базу данных новую информацию (с помощью asserta). Исходное начальное значение – это просто факт в базе данных, с функтором seed имеющим одну компоненту – целое значение начального числа. seed(13). random (R,N):-seed(S),N is (S mod R) + 1,retract(seed(S)),NewSeed is (125 * S + 1) mod 4096,asserta(seed(NewSeed)),!. Используя семантику retract можно упростить определение random следующим образом: random(R,N):-retract(seed(S)),N is (S mod R)+1,NewSeed is (125 * S +1) mod 4096,asserta(seed(NewSeed)),!. Для того, чтобы напечатать последовательность случайных чисел, расположенных в диапазоне между 1 и 10, которая обры-вается после того, как будет порождено значение 5, нужно задать следующий вопрос: ?- repeat, random(10,X), write(X), nl, X=5. Генератор имен (генатом) Предикат генатом позволяет порождать новые атомы Пролога. Если у нас есть программа, которая воспринимает информацию об окружающем мире (например, путем анализа описывающих его предложений на английском языке), то в случае появления в этом мире нового объекта возникают трудности с его обозначением. Естественно представлять объект атомом Пролога. Если объект ранее не встречался, мы должны убедиться в том, что тот атом, который мы ему сопоставляем, случайно не совпал с другим атомом, уже представляющим какой-то другой объект. Иными словами, нам необходимо иметь возможность формировать новые атомы. Мы можем также потребовать, чтобы созданный атом имел также некоторое мнемоническое значение: это облегчит понимание информации выводимой нашей программой. Если бы атомы представляли, скажем, студентов, то целесообразно было бы назвать первого студента – студент1, второго – студент2, третьего – студентЗ и т. д. Если к тому же нам нужно было бы работать с объектами представляющими еще и преподавателей, то можно было бы выбрать для их представления атомы преподаватель1, преподаватель2, преподавательЗ и т. д. Функция программы генатом состоит в том, чтобы порождать новые атомы от заданных корней (таких как студент и преподаватель). Для каждого корня программа запоминает, какой номер был использован в последний раз. Поэтому, когда в следующий раз от нее требуется породить атом с данным корнем можно гарантировать, что он будет отличаться от тех, что были порождены ранее. Так, когда вопрос ?- генатом(студент,X). задан впервые, ответом будет X = студент1 В следующий же раз ответом будет X = студент2 и т. д. Заметим, что эти различающиеся решения при возвратном ходе не порождаются (генатом(Х, Y) нельзя согласовать вновь), они порождаются последующими целями, включающими этот предикат. В определении генатом используется вспомогательный предикат тек_номер. Контроль за тем, какой номер использовать следующим для данного корня, осуществляется программой генатом путем записи в базу данных фактов вида тек_номер и удаления фактов, которые стали ненужными. Факт тек_номер (Корень, Номер) означает, что последний номер, использованный с корнем Корень, был Номер. Иными словами, последний атом, порожденный для этого корня, состоял из литер, взятых из Корень, за которыми был приформирован номер, взятый из Номер. Когда Пролог пытается доказать согласованность цели генатом, обычно делается следующее: последний факт тек_номер для заданного корня удаляется из базы данных, к его номеру прибавляется 1, и новый факт тек_номер запоминается в базе данных, заменяя исключенный факт. С этого момента новый номер может быть использован как основа для порождения нового атома. Хранить информацию о текущем номере в базе данных очень удобно. В противном случае каждый предикат, прямо или косвенно участвующий в выполнении генатом, должен был бы пересылать информацию о текущих номерах через дополнительные аргументы. Последние несколько утверждений этой программы определяют предикат целое_имя, который используется для преобразования целого числа в последовательность литер-цифр. Атомы, порождаемые генатом, формируются с помощью встроенного предиката name, который формирует атом из литер корня, за которыми следуют цифры номера. В некоторых реализациях Пролога используется версия предиката name, которая выполняет также функции предиката целое_имя, однако весьма поучительно посмотреть, как его можно определить на Прологе. В этом определении неявно используется тот факт, что коды ASCII для цифр 0, 1, 2 и т. д. равны соответственно 48, 49, 50 и т. д. Поэтому, чтобы преобразовать число меньшее 10 в код ASCII соответствующей цифры, достаточно прибавить к этому числу 48. Перевести в последовательность литер число, большее 9, сложнее. Последнюю цифру такого числа получить легко, поскольку это просто остаток от деления на 10 (число mod 10). Таким образом, цифры числа легче формировать в обратном порядке. Мы просто циклически повторяем следующие операции: получение последней цифры, вычисление остальной части числа (результат его целого деления на 10). Определение этого на Прологе выглядит следующим образом: цифры_наоборот(N,[С]):- N‹10,!, С is N+48. цифры_наоборот(М,[С|Сs]):-С is (N mod 10) + 48,N1 is N/10,цифры_нaoбopот(N1,Cs). Чтобы получить цифры в правильном порядке, применим трюк: в этот предикат добавим дополнительный аргумент – список «уже сформированных» цифр, С помощью этого аргумента мы можем получать цифры по одной в обратном порядке, но в итоговый список вставлять их в прямом порядке. Это делается следующим образом. Пусть у нас есть число 123. В начале список «уже сформированных» цифр есть []. Первым получаем число 3, которое преобразуется в литеру с кодом 51. Затем мы рекурсивно вызываем целое_имя, чтобы найти цифры числа 12. Список «уже сформированных» цифр, который передается в это целевое утверждение, содержит литеру, вставленную в исходный список «уже сформированных» цифр – это список [51]. Вторая цель целое_имя выдает код 50 (для цифры 2) и снова вызывает целое_имя, на этот раз с числом 1 и со списком «уже сформированных» цифр [50, 51]. Эта последняя цель успешно выполняется и, поскольку число было меньше 10, дает ответ [49,50,51]. Этот ответ передается через аргументы разных целей целое_имя и дает ответ на исходный вопрос – какие цифры соответствуют числу 123? Приведем теперь всю программу полностью. /* Породить новый атом, начинающийся с заданного корня, и оканчивающийся уникальным числом. */ генатом (Корень,Атом),выдать_номер(Корень,Номер), name(Корень,Имя1), целое_имя(Номер,Имя2), присоединить(Имя1,Имя2,Имя), name(Атом,Имя). выдать_номер(Корень, Номер):-retract(тeк_номер(Корень, Номер1)),!,Номер is Номер 1 + 1, asserta(тек_номер(Корень, Номер)). выдать_номер(Корень,1):- asserta(тек_номep(Kopeнь,l)). /* Преобразовать целое в список цифр */ целое_имя(Цел,Итогспи):- целое_имя (Цел, [], Итогспи). целое_имя(I,Текспи,[С|Текспи]:- I ‹10,!, С is I+48. целое_имя(I,Текспи,Итогспи):-Частное is I/10, Остаток is I mod 10,С is Остаток+48. целое_имя(Частное,[С|Текспи],Итогспи). Генератор списков структур (найтивсе) В некоторых прикладных задачах полезно уметь определять все термы, которые делают истинным заданный предикат. Например, мы могли бы захотеть построить список всех детей Адама и Евы с помощью предиката родители из гл. 1 (и располагая базой данных с фактами родители о родительских отношениях). Для этого мы могли бы использовать предикат по имени найтивсе, который мы определим ниже. Цель найтивсе(Х,G, L) строит список L, состоящий из всех объектов X таких, что они позволяют доказать согласованность цели G. При этом предполагается, что переменная G конкретизирована произвольным термом, однако таким, что найтивсе рассматривает его как целевое утверждение Пролога. Кроме того переменная X должна появиться где-то внутри G. Таким образом G может быть конкретизирована целевым утверждением Пролога произвольной сложности. Для того, чтобы найти всех детей Адама и Евы, необходимо было бы задать следующий вопрос: ?- найтивсе(Х, родители(Х,ева,адам), L). Переменная L была бы конкретизирована списком всех X, для которых предикату родители(Х,ева,адам) можно найти сопоставление в базе данных. Задача найтивсе заключается в том, чтобы повторять попытки согласовать его второй аргумент, и каждый раз, когда это удается, программа должна брать значение X и помещать его в базу данных. Когда попытка согласовать второй аргумент завершится неудачно, собираются все значения X, занесенные в базу данных. Получившийся при этом список возвращается как третий аргумент. Если попытка доказать согласованность второго аргумента ни разу не удастся, то третий аргумент будет конкретизирован пустым списком. При помещении элементов данных в базу данных используется встроенный предикат asserta, который вставляет термы перед теми, которые имеют тот же самый функтор. Чтобы поместить элемент X в базу данных, мы задаем его в качестве компоненты структуры по имени найдено. Программа для найтивсе выглядит следующим образом: найтивce(X,G,_):-asserta(найденo(мapкep)), call(G), asserta(найденo(X)),fail. найтивсе(_,_,L):- собрать_найденное([],М),!, L=M. собрать_найденное(S,L):- взятьеще(Х),!,собрать_найденное([Х |S],L). собрать_найденное(L,L). взятьеще(Х):- retract(найдено(Х)),!, Х\==маркер. Предикат найтивсе, начинает свою работу с занесения специального маркера, который представляет из себя структуру с функтором найдено и с компонентой маркер. Этот специальный маркер отмечает место в базе данных, перед которым будут занесены (с помощью asserta) все X, согласующие G с базой данных при данном запуске найтивсе. Затем делается попытка согласовать G и каждый раз, когда это удается, X заносится в базу данных в качестве компоненты функтора найдено. Предикат fail инициирует процесс возврата и попытку повторно согласовать G (asserta согласуется не более одного раза). Когда попытка согласовать G завершается неудачей, процесс возврата приводит к неудаче первого утверждения из определения найтивсе, и делается попытка согласовать в качестве цели второе утверждение. Второе утверждение вызывает собрать_найденное для выборки из базы данных всех структур найдено и включения их компонент в список. Предикат собрать_найденное вставляет каждый элемент в переменную, где хранится список «уже собранных» элементов. Этот прием мы рассматривали выше при разборе программы ге-натом. Как только встречается компонента маркер, взятьеще завершается неудачей, после чего выбирается второе утверждение для собрать_найденное. При сопоставлении его с текущей целью второй аргумент (результат) сцепляется с первым аргументом (с набранным списком) Заметим, что присутствие в базе данных структуры найдено (маркер) указывает на некоторое конкретное употребление найтивсе. Это означает, что найтивсе может вызываться рекурсивно – любое использование найтивсе во втором аргументе другого найтивсе будет обработано правильно. В разд. 7.9 мы разработаем программу, которая использует предикат найтивсе для построения списка всех потомков узла в графе. Этот список необходим для реализации программы поиска по графу вширь. Упражнение 7.7. Напишите Пролог-программу случайный_выбор такую, что цель случайный_выбор(L, Е) конкретизирует Е случайно выбранным элементом списка L. Подсказка: используйте генератор случайных чисел и определите предикат, который возвращает N-й элемент списка. Упражнение 7.8. Задана цельнайтивсе(Х,G, L). Что произойдет, если в G имеются неконкретизированные переменные не сцепленные с X? 7.9. Поиск по графуГраф – это сеть, состоящая из узлов, соединенных дугами. Например, географическую карту можно рассматривать как граф, где узлами являются населенные пункты, а дугами, соединяющие их дороги. Если вы хотите найти кратчайший маршрут между двумя населенными пунктами, вам предстоит решить задачу нахождения кратчайшего пути между двумя узлами графа. Проще всего описать граф в базе данных с помощью фактов, представляющих дуги между узлами графа. На рис, 7.3 приведен пример графа и его представления с помощью фактов. Чтобы пройти от узла g к узлу а, мы можем пойти по пути g, d, e, а или по одному из многих других возможных путей. Если мы представляем ориентированный граф, то предикат а следует понимать так, что а(Х, Y) означает, что существует дуга из X в Y, но из этого не следует существование дуги из Y в X. В данном разделе мы будем иметь дело только с неориентированными графами, у которых все дуги двунаправленные. Это допущение совпадает с тем, которое мы делаем в разд. 7.2 при поиске в лабиринте. 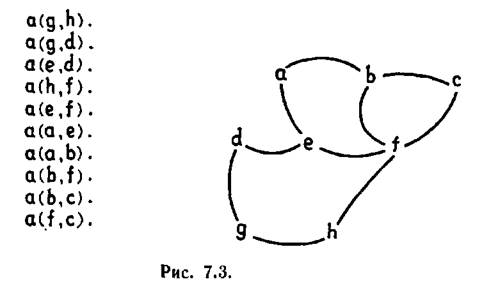 Простейшая программа поиска по графу, представленному так, как указано выше, выглядит следующим образом: переход(Х,X). переход(Х,Y):- (a(X,Z);a(Z,X)), переход(Z,Y). К сожалению, эта программа может зацикливаться. Поэтому, как и раньше, мы используем список Т для хранения перечня тех узлов, в которых мы уже побывали в какой-либо рекурсии предиката. переход(Х,Х,Т). переход(Х,Y,T):- (a(X,Z);a(Z,X)), not (принадлежит(Z, Т)),переход(Z, Y,[Z|T]). Эта программа, разработанная в разд. 7.2, осуществляет так называемый поиск «вглубь», поскольку вначале рассматривается только один из соседей узла по графу, Другие же соседи игнорируются до тех пор, пока неудачные попытки согласовать цели в рекурсивных вызовах не возвратят Пролог к рассмотрению данного узла. Теперь давайте рассмотрим такой поиск по графу, который мог бы быть полезен на практике. Как быть, если мы должны спланировать маршрут поездки из одного города Северной Англии в другой? Для этого потребуется база данных с информацией о дорогах между городами в Северной Англии и их протяженности: а(ньюкасл,карлайл,58). а(карлайл,пенрит,23). а(дарлингтон,ньюкасл,40). а(пенрит, дарлингтон,52). а(уэркингтон,карлайл,33). а(уэркингтон,пенрит,39). На некоторое время мы можем забыть о расстояниях и определить новый предикат: a(X,Y):- a(X,Y,Z). С помощью этого определения предиката а уже имеющаяся программа поиска по графу (переход) будет находить пути, по которым можно переезжать из одного места на графе в любое другое. Однако программа переход имеет недостаток: когда она успешно завершается, мы не знаем, какой путь она нашла. По меньшей мере мы вправе ожидать от программы переход выдачи нам в нужном порядке списка мест, которые придется посетить. Тем более, что в программе имеется перечень этих мест, правда, в порядке, обратном тому, какой нам нужен. Чтобы получить правильный список, мы можем воспользоваться программой обр, определенной в разд. 7.5. Тогда мы получим новое определение программы переход, которая возвращает найденный маршрут через свой третий аргумент: переход(Старт,Цель,Путь):- переход0(Старт,Цель,[],R),обр(R, Путь). переход0(Х,Х,Т,[Х|Т]). переход0(Место,Y,Т,R):-следузел(Место,Т,Сосед),переход0(Сосед,Y,[Место|T],R). следузел(Х,Бывали,Y):- (a(X,Y); a(Y,X)),not (принадлежит(Y,Бывали)). Заметим, что предикат следузел позволяет получать для узла X «правильный» узел Y, т. е. такой, к которому можно непосредственно перейти от узла X. Ниже приводится пример работы этой программы при поиске маршрута из Дарлингтона в Уэркингтон: ?- переход(дарлингтон,уэркингтон,Х) Х=[дарлингтон,ньюкасл,карлайл,пенрит,уэркингтон] Это не самый лучший маршрут, однако, программа найдет другие маршруты если мы инициируем процесс возврата. У этой программы много недостатков. Она совершенно не управляет выбором следующего участка пути, поскольку у нее нет доступа к полному набору возможных вариантов, а те выборы, которые у программы имеются, не представлены явно в виде структуры, которая может анализироваться программой, а неявно предопределены схемой работы механизма возврата. Ниже приведен переработанный вариант программы, который отличается большей универсальностью. В дальнейшем мы увидим, как с помощью простых изменений в этой программе можно получить разнообразные методы поиска. переход(Старт,Цель,Путь):- переход1([[Старт]],Цель,R),обр(R, Путь). переход1([Первый|Ост],Цель,Первый):- Первый =[Цель|_]. переход1([[Послед|Бывали]|Прочие],Цель,Путь):-найтивсе([Z, Послед|Бывали], следузел(Послед, Бывали,Z), Список), присоединить(Список, Прочие, НовПути), переход1(НовПути,Цель,Путь). Предикат следузел остается прежним. Предикату переход1 передается список рассматриваемых путей вместе с конечным пунктом, и в последнем аргументе он возвращает удачный путь. Список рассматриваемых путей – это просто все дороги, начинающиеся в начальной точке, которые мы уже рассмотрели. Мы надеемся, что одна из них при продлении даст путь, который приведет нас в конечный пункт. Все пути представлены в виде обратных списков населенных пунктов, так что они могут также выполнять функции перечня мест, где мы уже бывали. В самом начале имеется только один возможный путь, который можно пытаться продлить. Это просто путь, который начинается в исходном пункте и никуда не ведет. Если мы стартуем из Дарлингтона, то это будет [дарлингтон]. Если теперь исследовать пути ведущие из Дарлингтона в соседние города, то можно обнаружить, что имеются два возможных пути [ньюкасл, дарлингтон] и [пенрит, дарлингтон]. Поскольку Уэркингтон не встречается ни на одном из этих путей, необходимо решить, какой из этих путей следует продолжить. Если принято решение продлить первый путь, то мы обнаружим, что существует всего один доступный узел – последний город на этом пути. Итак, кроме пути Дарлингтон – Пенрит у нас есть новый путь: [карлайл, ньюкасл, дарлингтон]. Наш «изыскатель», переход1 ведет полный список путей, по которым, может быть, стоит двигаться. Как же он решает какой из путей следует рассмотреть первым? Он просто выбирает первый попавшийся. Затем он ищет все возможные способы продления этого пути до следующего населенного пункта (используя найтивсе для построения списка всех таких продленных путей) и помещает получившиеся пути в начало списка для рассмотрения их на следующем уровне рекурсии. В результате, переход1 ведет себя таким образом, что он попробует все возможные способы продления первого пути прежде чем будет рассматривать альтернативные пути. Такая стратегия поиска является одним из вариантов поиска вглубь. Между прочим, переход1 рассматривает пути совершенно в том же порядке, что и переход0. Быть может вам будет интересно выяснить, почему это так. Если нас интересует кратчайший путь от Дарлингтона до Уэркингтона, то имеющаяся программа для этого не подходит. Первое найденное ею решение – это не кратчайший путь, а наоборот, самый длинный (в данном случае). Нам нужно изменить программу таким образом, чтобы она строила пути в порядке возрастания их длины. Если мы изменим ее так, чтобы она всегда продлевала более короткие пути, прежде чем рассматривать более длинные, то она будет вынуждена находить вначале кратчайшие пути (если измерять длину пути числом городов на нем). Полученная программа будет осуществлять поиск вширь. Единственное, что нужно сделать для этого – это вставлять новые альтернативы в конец всего списка возможностей, а не в начало, как в последнем примере. Мы просто исправим второе утверждение в определении переход1, чтобы он выглядел следующим образом: переход1([[Послед|Бывали]|Прочие],Цель,Путь):-найтивсе([Z,Послед|Бывали], следузел(Послед, Бывали,Z),Список), присоединить(Прочие,Список,НовПути), переход1(НовПути,Цель, Путь). Теперь исправленная программа находит возможные пути из Дарлингтона в Уэркингтон в следующем порядке: [дарлингтон,пенрит,уэркингтон] [дарлингтон,ньюкасл, карлайл,уэркингтон] [дарлингтон,пенрит,карлайл,уэркингтон] [дарлингтон,ньюкасл,карлайл,пенрит,уэркингтон] Мы можем значительно упростить эту программу, если уверены, что ответ на вопрос всегда существует и если нам нужно только первое решение. В этом случае отпадает необходимость в проверке на зацикливание. Попробуйте самостоятельно выяснить, почему это так. К сожалению, путь через наименьшее число городов не обязательно будет самым кратчайшим по километражу. До сих пор мы не принимали во внимание информацию о расстояниях, имеющуюся в нашем графе. Если же мы добавим к нашему графу несколько фиктивных городов, чтобы получить: а(ньюкасл,карлайл,58). а(карлайл,пенрит,23). а(городБ,городаА,15). а(пенрит, дарлингтон,52). а(городБ,городВ,10). а(уэркингтон, карлайл, 33). а(уэркингтон,городВ,5). а(уэркингтон,пенрит,39). а(дарлингтон,городА,25). то путь, кратчайший по километражу, фактически будет построен последним, поскольку он проходит через большое число городов. С каждым путем, который может быть продолжен, нам нужно связать и поддерживать в процессе работы программы указатель текущей длины этого пути. Тогда программа будет всегда продлевать путь с наименьшим километражем. Такая стратегия называется поиском по критерию первый-лучший. Будем теперь представлять путь в списке альтернативных путей в виде структуры г(М, П), где М – общая длина пути в километрах, а П – список мест, где мы уже побывали. Модифицированный предикат переходЗ находит кратчайший путь в списке альтернатив. Предикат кратчайший выделяет кратчайший путь в отдельный список, а остальные пути – в другой список. Предикат продлить находит все допустимые продолжения текущего кратчайшего пути и добавляет их к списку. Это в свою очередь требует новой версии предиката следузел, которая прибавляет расстояние до следующего города к уже вычисленному расстоянию. В целом программа выглядит так: переходЗ (Пути,Цель,Путь):-кратчайший (Пути,Кратчайший,ОстПути), продлить(Кратчайший,Цель,ОстПути,Путь). продлить(г(Расст,Путь),Цель,_,Путь):- Путь = [Цель|_]. продлить(г(Расст,[Послед| Бывали]),Цель,Пути,Путь):-найтивсе(г(D1,[Z,Послед|Бывали]),следузел(Послед,Бывали,Z,Расст,D1),Список), присоединить(Список,Пути,НовПути), переходЗ(НовПути,Цель,Пути). кратчайший([Путь[Пути],Кратчайший,[ПутьЮст]):-кратчайший(Пути,Кратчайший,Ост), короче(Кратчайший,Путь),!. кратчайший(Путь|Ост],Путь,Ост). короче(г(М1,_),г(М2, _):- M1 ‹ М2. следузел(Х,Бывали,Y,Расст,НовРасст):-(a(X,Y,Z); a(Y,X,Z)),not(принадлежит(Y,Бывали)),НовРасст is Расст+Z. Чтобы использовать эту программу, необходимо задать вопрос, содержащий предикат переход, определенный следующим образом: переход (Старт,Цель,Путь):-переход3([г(0,[Старт])],Цель,R), обр(R,Путь). Эта новая программа успешно строит возможные пути в по-рядке возрастания их фактической протяженности. Может быть, вам захочется изменить ее так, чтобы вместе с ответами она печатала длины различных путей. Мы лишь затронули вопрос о возможных способах организации поиска по графу. Сведения о том, как осуществлять поиск по графу с использованием более эффективных критериев, чем «первый лучший», можно найти в литературе по искусственному интеллекту. Например: Nilsson N. Principles of Artificial Intelligence, Springer-Verlag, 1982[10] и Winstone P. Artificial Intelligence, (second edition), Addison-Wesley, 1984.[11] 7.10. Просеивай Двойки, Просеивай ТройкиПросеивай Двойки,(Аноним) Простое число – это целое положительное число, которое делится нацело только на 1 и на само себя. Например, число 5 – простое, а число 15 – нет, поскольку оно делится на 3. Один из методов построения простых чисел называется «решетом Эратосфена». Этот метод, «отсеивающий» простые числа, не превышающие N, работает следующим образом: 1. Поместить все числа от 2 до N в решето. 2. Выбрать и удалить из решета наименьшее число. 3. Включить это число в список простых. 4. Просеять через решето (удалить) все числа, кратные этому числу. 5. Если решето не пусто, то повторить шаги 2-5. Чтобы перевести эти правила на Пролог, мы определим предикат целые для получения списка целых чисел, предикат отсеять для проверки каждого элемента решета и предикат удалить для создания нового содержимого решета путем удаления из старого всех чисел, кратных выбранному числу. Это новое содержимое опять передается предикату отсеять. Предикат простые - это предикат самого верхнего уровня, такой что простые(N, L) конкретизирует L списком простых чисел, заключенных в диапазоне от 1 до N включительно. простые(Предел,Рs):- целые(2,Предел,Is),отсеять(Is,Рs). целые (Min,Max,[Min|Oct]):-Min=‹Max,!, М is Min+1,целые(М,Мах,Ост). целые(_,_,[]). отсеять([],[]). отсеять([I|Is],[I|Ps]):-удалить(I,Is,Нов),отсеять(Нов,Рs). удалить(Р,[],[]). удалить (P,[I|Is],[I|Nis]):-not(0 is I mod Р),!,удалить(Р,Is,Nis). удалить (P,[I|Is],Nis):-0 is I mod Р,!,удалить(Р,Is,Nis). Продолжая эту арифметическую тему, рассмотрим Пролог-программу, реализующую рекурсивную формулировку алгоритма Евклида для нахождения наибольшего общего делителя (НОД) и наименьшего общего кратного (НОК) двух чисел. Целевое утверждение нод(I,J,K) доказуемо, если K является наибольшим общим делителем чисел I и J. Целевое утверждение нок(I,J,K) доказуемо, если K является наименьшим общим кратным чисел I и J: нод(I,0,I). нод(I,J,K):- R is I mod J, нод(J,R,K). нок(I,J,K):- нод(I,J,R), K is (I*J)/R. Заметим, что из-за особенностей способа вычисления остатка эти предикаты не являются «обратимыми». Это означает, что для того чтобы они работали, необходимо заблаговременно конкретизировать переменные I и J. Упражнение 7.10. Если числа X, Y и Z таковы, что квадрат Z равен сумме квадратов X и Y (т. е. если Z²=X²+Y²), то про такие числа говорят, что они образуют Пифагорову тройку. Напишите программу, порождающую Пифагоровы тройки. Определите предикат pythag такой что, задав вопрос ?- pythag(X,Y,Z). и запрашивая альтернативные решения, мы получим столько разных Пифагоровых троек, сколько пожелаем. Подсказка: используйте предикаты, подобные целое_число из гл. 4. 7.11. Символьное дифференцированиеСимвольным дифференцированием в математике называется операция преобразования одного арифметического выражения в другое арифметическое выражение, которое называется производной. Пусть U обозначает арифметическое выражение, которое может содержать переменную х. Производная от U по х записывается в виде dU/dx и определяется рекурсивно с помощью некоторых правил преобразования, применяемых к U. Вначале следуют два граничных условия. Стрелка означает «преобразуется в»; U и V обозначают выражения, а с – константу: dc/dx → 0 dx/dx → 1 d(-U)/dx → -(dU/dx) d(U+V)/dx → dU/dx+dV/dx d(U-V)/dx → dU/dx-dV/dx d(cU)/dx → c(dU/dx) d(UV)/dx → U(dV/dx) + V(dU/dx) d(U/V)dx → d(UV-1)/dx d(Uc)/dx → cUc-l(dU/dx) d(lnU)/dx → U-1(dU/dx) Этот набор правил легко написать на Прологе, поскольку мы можем представить арифметические выражения как структуры и использовать знаки операций как функторы этих структур. Кроме того, сопоставление целевого утверждения с заголовком правила мы можем использовать как сопоставление образцов. Рассмотрим цель d(E,X, F), которая считается согласованной, когда производная выражения E по константе[12] X есть выражение F. Помимо знаков операций +, -, *, /, которые имеют встроенные определения, нам нужно определить операцию ^, такую, что X^Y означаете xy, а также одноместную операцию ~, такую что ~Х означает «минус X». Эти определения операций введены исключительно для того, чтобы облегчить распознавание синтаксиса выражений. Например, после того как d определен, можно было бы задать следующие вопросы: ?- d(x+1,x,X). X = 1+0 ?- d(x*x-2,x,X). X = х*1+1*х-0 Заметим, что само по себе простое преобразование одного выражения в другое (на основе правил) не всегда дает результат в приведенной (упрощенной) форме. Приведение результата должно быть записано в виде отдельной процедуры (см. разд. 7.12). Программа дифференцирования состоит из определений дополнительных операций и построчной трансляции приведенных выше правил преобразования в утверждения Пролога: ?- op(10,yfx,^). ?- op(9,fx,~). d(X,X,1):-!. d(C,X,0):- atomic(C). d(~U,X,~A):- d(U,X,A). d(U+V,X,A+B):- d(U,X,A), d(V,X,B). d(U-V,X,A-В):- d(U,X,A), d(V,X,B). d(C*U,X,C*A):- atomic(C), C\=X, d(U,X,A),!. d(U*V,X,B*U+A*V):- d(U,X,A), d(V,X,B). d(U/V,X,A):- d(U*V^~1),X,A). d(U^C,X,C*U^(C-1)*W):- atomic(C),C\=X,d(U,X,W). d(log(U),X,A*U^(~1)):- d(U,X,A). Обратите внимание на два места, в которых задан предикат отсечения. В первом случае отсечение обеспечивает тот факт, что производная от переменной по ней самой распознается только первым утверждением, исключая возможность применения второго утверждения. Во втором случае предусмотрено два утверждения для умножения. Первое – для специального случая. Если имеет место специальный случай, то утверждение для общего случая должно быть устранено из рассмотрения. Как уже говорилось, данная программа выдает решения в неприведенной форме (т. е. без упрощений). Например, всякое вхождение х*1 может быть приведено к х, а всякое вхождение вида х*1+1*х-0 может быть приведено к 2*х. В следующем разделе рассматривается программа алгебраических преобразований, которую можно использовать для упрощения арифметических выражений. Примененный способ очень похож на тот, каким выше выводились производные. 7.12. Отображение структур и преобразование деревьевЕсли некоторая структура покомпонентно копируется с целью образования новой структуры, то мы говорим, что одна структура отображается в другую. Обычно при копировании каждая компонента слегка изменяется подобно тому, как в гл. 3 мы изменяли одно предложение, превращая его в другое. В том примере нам иногда нужно было скопировать какое-то слово в точности в том виде, в каком оно встретилось в исходном предложении, а иногда при копировании нам нужно было изменить слово. Для этого мы использовали следующую программу, которая отображает первый аргумент предиката преобразовать во второй его аргумент: преобразовать([],[]). преобразовать([А|В],[С|D]):- заменить(А,С),преобразовать(В,D). Поскольку отображение имеет довольно широкое применение, мы можем определить предикат отобспис такой, что целевое утверждение отобспис(Р, L, M) согласуется с базой данных, применяя предикат Р к каждому элементу списка L и образуя в результате новый список М. При этом предполагается, что предикат Р имеет два аргумента: первый аргумент для передачи «входного» элемента, а второй аргумент – для измененного элемента, подлежащего включению в список М. отобспис((_,[],[]). отобспис((P,[X|L],[Y|M]):- Q =..[P,X,Y],call(Q),отобспис(Р,L,М). Об этом определении следует сказать несколько слов. Во-первых, определение содержит граничное условие (первое утверждение) и общий рекурсивный случай (второе утверждение). Во втором утверждении используется оператор '=..', формирующий целевое утверждение на основе предиката (Р), входного элемента (X) и переменной (Y), которую предикат Р должен конкретизировать, чтобы образовать измененный элемент. Затем делается попытка согласовать цель Q, в результате чего Y конкретизируется, образуя голову третьего аргумента данного вызова предиката отобспис. Наконец, рекурсивный вызов отображает хвост первого аргумента в хвост второго. Функции предиката преобразовать может выполнять предикат отобспис. Полагая, что предикат заменить определен как в гл. 3, такое использование отобспис могло бы выглядеть следующим образом: ?- отобспис(заменить,[уоu,аrе,а,computer],Z). Z = [i, [am, not], a, computer] Путем упрощения предиката отобспис получается предикат обрабспис, который просто обрабатывает список, применяя некоторый предикат от одного аргумента к каждому элементу списка. При этом новый список не порождается. обрабспис(_,[]). обрабспис(Р,[Х|L]):-Q =…[Р,Х],call(Q),обрабспис(Р,L). Заметим, что предикат печать_строки из гл. 5 можно было бы заменить запросом вида обрабспис(put, L), где L – это строка, которую нужно напечатать. Отображение применимо не только к спискам; оно может быть определено для структуры любого вида. Например, рассмотрим арифметическое выражение, составленное из функторов * и +, имеющих по два аргумента. Пусть мы хотим отобразить одно выражение в другое, устраняя при этом все умножения на 1. Это алгебраическое приведение могло быть определено с помощью предиката s такого, что s(Op, L, R,Ans) означает, что выражение, состоящее из операции Ор с левым аргументом L и правым аргументом R приводится к упрощенному выражению Ans. Факты, необходимые для устранения умножений на 1, могли бы выглядеть так (из-за коммутативности умножения нужны два факта): s(*,X,1,X). s(*,1,X,X). Эта таблицы упрощений позволяет нам любое выражение вида 1*Х отобразить в X. Посмотрим, как можно воспользоваться этим в программе. При приведении выражения Е с помощью такой таблицы упрощений, мы вначале должны привести левый аргумент Е, затем привести правый аргумент Е и, наконец, посмотреть, подходит ли этот приведенный результат под случаи, предусмотренные в нашей таблице. Если это так, то мы порождаем новое выражение в соответствии с указаниями таблицы. В качестве «листьев» дерева, представляющего выражение, фигурируют целые числа или атомы, поэтому для приведения листьев к ним самим в граничном условии мы должны использовать встроенный предикат atomic. Как и выше, мы можем использовать ' =..', чтобы разложить выражение Е на функтор и компоненты; привести(Е,Е):- atomic(E), 1. привести(Е,F):-Е =.. [Op,L,R],привести(L,Х),привести(R, Y),s(Op,X,Y,F). Итак, предикат привести отображает выражение Е в выражение F, используя для этого факты, имеющиеся в таблице упрощений s. А что делать, если невозможны никакие упрощения? Чтобы избежать в этом случае неудачного завершения s(Op,X, Y, F), мы должны поместить в конец каждого раздела таблицы упрощений, относящегося к определенному оператору, правило-ловушку. Приведенная ниже таблица упрощений содержит правила для сложения и умножения. Кроме того, в ней выделены правила-ловушки для каждого вида операций. s(+,X,0,X). s(+,0,X,X). s(+,X,Y,X + Y) /* ловушка для + */ s(*,_,0,0). s(*,0,_,0). s(*,1,X,X). s(*,X,1,X). s(*,X,Y,X*Y). /* ловушка для * */ При наличии правил-ловушек возникает вопрос о выборе способа упрощения некоторых выражений. Например, если нам дано выражение 3+0, мы можем либо использовать первый факт, либо применить правило-ловушку для +. Благодаря способу упорядочения фактов, прежде чем применить правило-ловушку Пролог всегда будет пытаться применить правила для специальных случаев. Поэтому первое решение, полученное предикатом привести, всегда будет являться действительно упрощенным выражением (если оно возможно). Однако альтернативные решения будут иметь не самый простой вид из всех возможных. Другое упрощение, используемое при выполнении алгебраических преобразований с помощью ЭВМ, известно как свертка констант. В выражении 3*4+a константы 3 и 4 могут быть «свернуты», что дает в результате выражение 12+а. Правила свертки констант могут быть добавлены в соответствующие места приведенной выше таблицы упрощений. Правило для сложения констант выглядит следующим образом: s(+,X,Y,Z):- integer(X), integer(Y), Z is X+Y. Соответствующие правила для других арифметических операций имеют аналогичный вид. В коммутативных операциях, таких как умножение и деление, указанные выше упрощения могут давать различный эффект на выражениях, которые записаны по-разному, но алгебраически эквивалентны. Например, если правило свертки констант задано для умножения, то предикат привести совершенно правильно преобразует 2*3*а в 6*а, но а*2*3 или 2*а*3 будут преобразовываться в самих себя. Чтобы понять, почему это так, подумайте над тем, как выглядят деревья, представляющие эти выражения (см. рис. 7.4). В первом дереве самое нижнее умножение 2*3 можно свернуть, получив 6, но во втором дереве нет поддеревьев, которые было бы можно свернуть. Однако, используя коммутативность умножения, можно добавить к таблице следующее правило, которое позволит справиться с данным конкретным случаем: s(*,X*Y,W,X*Z):- integer(Y), integer(W), Z is Y*W. Более общая алгебраическая система может быть построена путем простого добавления дополнительных s-утверждений вместо увеличения объема программы для привести. 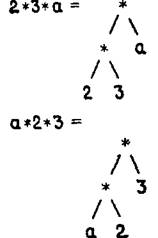 Рис. 7.4 7.13. Применение предикатов clause и retractВ этой книге мы неоднократно сталкивались с применением встроенных предикатов. На самом деле многие из них можно определить на Прологе, используя более простые встроенные предикаты. В этом разделе мы рассмотрим несколько таких определений. Они могут найти практическое применение у тех программистов, которые используют неполную в каких-либо отношениях Пролог-систему, однако в любом случае они интересны, как примеры программирования на Прологе. Может быть, они наведут вас на мысль о разработке несколько отличающихся версий этих предикатов для своего собственного применения. Мы можем определить с помощью предиката clause некоторую версию процедуры listing. Определим предикат распеч1 такой, что при согласовании цели распеч1(Х) с базой данных из последней будут выводиться на печать утверждения, заголовки которых совпадают с X. Поскольку определение распеч1 включает использование предиката clause, у которого X задан как первый аргумент, то мы вынуждены поставить условие, что переменная X конкретизирована таким образом, что главный функтор утверждения известен. Рассмотрим определение распеч1: распеч1(Х):-clause(Х,Y),выв_утвержд(Х,Y),write('.'),nl,fail. распеч1(Х). выв_утвержд(Х,true):-!, write(X). выв_утвержд(Х,Y):- write((X:- Y)). При попытке согласовать с базой данных цель распеч1(Х) первое утверждение осуществляет поиск в базе данных такого утверждения, у которого заголовок совпадает с X. Если такое утверждение найдено, то оно выводится на печать и затем с помощью предиката fail инициируется механизм возврата. Возвратный ход опять приводит нас к предикату clause, который находит другое такое же утверждение, если оно имеется, и т. д. Когда таких утверждений больше нет, цель clause больше не удается согласовать с базой данных. В этом случае будет выбрано второе утверждение определения предиката распеч1, и потому цель будет согласована с базой данных. «Побочным эффектом» этих действий является печать соответствующих утверждений. Определение предиката выв_утвержд задает способ печати найденных утверждений. Выделяется специальный случай, когда тело утверждения есть true. В этом случае на печать выводится только заголовок утверждения. Иначе на печать выводится заголовок и тело утверждения, соединенные функтором ':-'. Отметим, что использование «отсечения» здесь имеет целью указать, что в случае, когда тело есть true, можно применять только первое правило. Поскольку данный пример построен на использовании механизма возврата, то задание отсечения здесь существенно. Встроенный предикат clause можно также применить при написании Пролог-интерпретатора на самом Прологе. Это означает, что мы можем определить действия, которые представляют собой выполнение Пролог-программы, причем исполнителем этих действий также является Пролог-программа. Ниже приводится определение предиката интерпрет такого, что цель интерпрет(Х) согласуется в том и только в том случае, когда X, рассматриваемая как цель, согласуется с базой данных. Предикат интерпрет напоминает встроенный предикат call, но является более ограниченным. интерпрет(true):-!. интерпрет((Gl,G2)):-!, интерпрет(G1), интерпрет(G2). интерпрет(Цель):-clause(Цель,ЕщеЦели), интерпрет(ЕщеЦели). Первые два утверждения рассчитаны на специальные случаи, когда цель есть true и когда цель представляет собой конъюнкцию целей. Последнее утверждение рассчитано на случай простой цели. Данная процедура находит утверждение, заголовок которого совпадает с заданной целью, и затем интерпретирует цели, входящие в тело этого утверждения. Заметим, что приведенное определение не рассчитано на программы, где используются встроенные предикаты, поскольку у таких предикатов нет определяющих их в обычном смысле утверждений. Рассмотрим определение предиката consult. Разумеется, предикат consult предусмотрен среди встроенных предикатов большинства Пролог-систем, однако интересно посмотреть, как он может быть определен на Прологе. consult(Файл):-seeing(Input),sее(Файл),repeat,read(Tepм),обработать(Терм),seen,see(Input),!. обработать(Терм):- маркер_конца_файла(Терм),!. обработать((?- Q)):-!, call(Q),!, fail. обработать(Утвержд):- assertz(Утвержд), fail. Это определение отличается рядом интересных особенностей. Во-первых, цель seeing(Input) и ее партнер see(Input) призваны гарантировать, что текущий файл ввода не будет «забыт» после применения предикат consult. Во-вторых, предикат маркер_конца_файла здесь использован без определения. По замыслу он должен быть истинным только в том случае, когда его аргумент конкретизирован термом, используемым для представления конца файла (который мог бы встретиться при выполнении read). В разных реализациях Пролога для представления «конца файла» используются разные термы, поэтому маркер_конца_файла в разных реализациях может быть определен по-разному. Одно из возможных определений выглядит так: маркер_конца_файла(конец_файла). В определении предиката обработать интересна организация выполнения соответствующих действий для каждого терма, считанного из входного файла. Целевое утверждение обработать доказуемо только, когда его аргументом является маркер конца файла. Иначе после соответствующего действия имитируется неудача доказательства и инициируется механизм возврата, который возвращает программу к предикату repeat. Отметим важность «отсечения» в конце определения предиката consult. Оно фиксирует выбор, сделанный предикатом repeat[13]. И последнее замечание. Если терм, считанный из файла, представляет собой вопрос (см. второе утверждение определения предиката обработать), то делается попытка немедленно согласовать соответствующую цель с помощью предиката call (см. разд. 6.7). В качестве примера использования предиката retract здесь приведено определение полезного предиката уберивсе. При согласовании с базой данных целевого утверждения уберивсе(Х) все утверждения, заголовки которых совпадают с X, удаляются из базы данных. Поскольку в данном определении используется предикат retract, то переменная X не может быть неконкретизированной, так как в противном случае не с чем будет сопоставлять утверждения из базы данных. Данное определение должно распознавать два вида утверждений с заголовками, совпадающими с X, - факты и правила. При обработке этих двух видов утверждений в вызове retract задаются разные аргументы. В определении используется то свойство, что retract будет срабатывать при возврате до тех пор, пока все утверждения, сопоставимые с его аргументами, не будут удалены из базы данных. уберивсе(Х):- retract(X), fail. уберивсе(Х):- retract((X:- Y)), fail. уберивсе(_). В качестве примера использования предиката убери все здесь приведено определение предиката reconsult на Прологе. Назначение предиката reconsult сходно с назначением предиката consult, с той лишь разницей, что при reconsult каждое считанное утверждение замещает существующее утверждение того же предиката, а не добавляется к нему (см. разд. 6.1). reconsult(Файл):-уберивсе(сделано(_)),seeing(Старый),sее(Файл),repeat,read(Терм),проверить(Терм),seen,see(Старый),!. проверить(Х):- маркер_конца_файла(Х),!. проверить((?- Цели)):-!, call (Цели),!, fail. проверить(Утверждение):-заголовок(Утверждение, Заголовок), запись_сделана(3аголовок), assertz(Утверждение), fail. запись_сделана(3аголовок):- сделано(Заголовок),!. запись_сделана(3аголовок):- functor(Заголовок,Func,Arity), functor(Proc,Func,Arity), asserta(cдeлaнo(Proc)), уберивсе(Ргос),!. заголовок((А:- В), А):-!. заголовок (А, А). Это определение похоже на определение consult, в котором вместо предиката обработать используется предикат проверить. Основное различие заключено в предикате запись_сделана. Когда в файле появляется первое утверждение для данного предиката, то, прежде чем к базе данных будет добавлено хотя бы одно новое утверждение, из нее должны быть удалены все старые утверждения для данного предиката. Удаление этих утверждений нельзя откладывать до момента, когда в базе данных появятся их новые версии, поскольку в этом случае мы удалили бы из базы данных те утверждения, которые только что были введены. Как же определить, что некоторое утверждение в файле является первым для соответствующего предиката? Ответ заключается в том, что мы регистрируем в базе данных предикаты, для которых уже нашлись утверждения в файле. Это делается с помощью предиката сделано. Когда из файла считывается первое утверждение например, для предиката foo с двумя переменными, то имеющиеся утверждения удаляются и новое утверждение добавляется к базе данных. Кроме того, к базе данных добавляется факт: сделано(foo(_,_)). В дальнейшем, при чтении остальных утверждений для предиката too, мы сможем проверить, что старые утверждения уже удалены из базы данных. Тем самым удается избежать ошибочного удаления новых утверждений. Для данного определения важно, что мы не добавляем в базу данных что-нибудь вроде: сделано(foо(а,Х)). поскольку в этом случае аргумент предиката сделано не обязательно совпадает с заголовком утверждения для foo. Пара запросов …,functor(Заголовок,Func,Arity),functor(Proc,Func,Arity),… конкретизирует Ргос структурой, имеющей тот же функтор, что и заголовок Заголовок, но с переменными в качестве аргументов (см. разд. 6.5). Примечания:1 В книге термин «Пролог» употребляется в трех значениях: 1) Пролог – язык программирования с совокупностью синтаксических и семантических правил записи программ; 2) Пролог – программная система (интерпретатор), реализующая язык; эта система и осуществляет диалог с пользователем; 3) Пролог – машина, на которой Пролог-система выполняет (интерпретирует) программы, написанные на языке Пролог. Как правило, из контекста всегда ясно, какое значение используется в каждом конкретном случае. При необходимости явного указания при переводе использовались термины: «язык Пролог», «Пролог-система», «Пролог-машина». - Прим. пepeв. 10 Имеется перевод: Нильсон Н. Принципы искусственного интеллекта. - М.: Радио и связь, 1985. - Прим. перев. 11 Имеется перевод 1-го издания: Уинстон П., Искусственный интеллект. - М.: Мир, 1980. - Прим. перев. 12 Имеется в виду константа в смысле Пролога. - Прим. ред. 13 Тем самым обеспечивает возможность вновь согласовать предикат consult. В противном случае механизм возврата никогда не смог бы миновать repeat, у которого всегда есть альтернативное решение. - Прим. ред. |
|
||
| Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх | ||||
|
|
||||