|
||||
|
|
ГЛАВА 9. ИСПОЛЬЗОВАНИЕ ГРАММАТИЧЕСКИХ ПРАВИЛ В ПРОЛОГЕ9.1. Проблема синтаксического анализаПредложения на естественном языке, таком как английский представляют собой нечто большее, чем просто произвольные последовательности слов. Мы не можем соединить вместе произвольное множество слов и получить при этом предложение, имеющее смысл. По крайней мере результат должен соответствовать тому, что мы называем грамматически правильным предложением. Грамматика языка – это множество правил, позволяющих определить, какие последовательности слов приемлемы в качестве предложений этого языка. Она определяет, как из слов образуются словосочетания и какие последовательности этих словосочетаний допустимы. Если задана грамматика некоторого языка, то для любой последовательности слов мы можем сказать, является ли она допустимым предложением. И в случае, когда это предложение действительно является допустимым, в результате проверки мы определим, какие естественные группы слов имеются и как они связаны друг с другом. То есть будет определена внутренняя структура предложения. Очень простой класс грамматик составляют так называемые контекстно-свободные грамматики. Вместо того, чтобы давать формальное определение понятия контекстно-свободной грамматики, мы проиллюстрируем его на одном простом примере. Приведенные ниже правила можно рассматривать как начальную часть грамматики предложений английского языка: предложение--› группа_существительного, группа_глагола. группа_существительного--› определитель, существительное. группа_глагола--› глагол, группа_существительного. группа_глагола--› глагол. определитель--› [the]. существительное--› [apple]. существительное--› [man]. глагол--› [eats]. глагол--› [sings]. 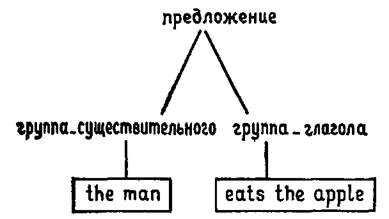 Рис. 9.1. Эта грамматика состоит из множества правил, каждое из которых записано в отдельной строке. Каждое правило определяет форму словосочетания определенного вида. Первое правило показывает, что предложение состоит из словосочетания, называемого группа_существительного, за которым следует словосочетание, называемое группа_глагола. Эти два словосочетания есть не что иное, как подлежащее и сказуемое предложения (см. рис. 9.1). Чтобы представлять, что значит правило в контекстно-свободной грамматике, их следует читать следующим образом: X--›Y как «X может иметь вид Y», а 'X, Y' как «X, за которым следует Y». Так первое правило может быть прочитано: предложение может иметь вид: группа_существительного, за которой следует группа_ глагола. Все это очень хорошо, но что представляют собой группа_существительного и группа_глагола? Как мы должны распознавать подобные объекты и как узнать их грамматическую структуру? Ответы на эти вопросы следуют из второго, третьего и четвертого правил грамматики. Например, группа_существительного может иметь вид: определитель, за которым следует существительное. Неформально, группа существительного – это группа слов, служащая для обозначения некоторого объекта (или объектов). Такая группа содержит слово – существительное, которое определяет главный класс, которому принадлежит этот объект. Так «the man» (человек) обозначает человека, «the program» (программа) обозначает программу и так далее. Кроме того, в соответствии с приведенной грамматикой, существительному должна предшествовать группа слов, названная «определитель» (см. рис. 9.2). Аналогично, внутренняя структура словосочетания группа_глагола описывается соответствующими правилами. Заметим, что для этого словосочетания существуют два правила. Это вызвано тем, что оно может принимать два вида. Словосочетание группа_глагола может содержать словосочетание группа_существительного, как в предложении «the man eats the apple» (человек ест яблоко), или группа_существительного может отсутствовать, как в предложении «the man sings» (человек поет). Для чего нужны остальные правила грамматики? Эти правила показывают, как некоторые словосочетания могут быть построены из настоящих слов, а не сводят их к совокупности более мелких словосочетаний. Слова английского языка записываются в квадратных скобках, так что правило: определитель--› [the]. можно читать так: определитель может иметь вид: слово the. Теперь, когда мы получили достаточно полное представление о грамматике, мы можем поговорить о том, какие последовательности слов являются грамматически правильными предложениями в соответствии с приведенной грамматикой. Наша грамматика очень проста и нуждается в целом ряде расширений. Основной недостаток заключается в том, что она допускает предложения, составленные лишь из пяти различных слов. Если мы хотим определить, является ли заданная последовательность слов предложением, в соответствии с тем, как оно определяется грамматикой, то необходимо применить первое правило, чтобы получить ответ на следующий вопрос: можно ли разбить заданную последовательность на два словосочетания таким образом, чтобы первое из них было группа_существительного, а второе группа_глагола? Затем, чтобы проверить, является ли первое словосочетание группой существительного, необходимо применить второе правило, которое можно интерпретировать как вопрос: можно ли разбить словосочетание на определитель и существительное, следующее за определителем? 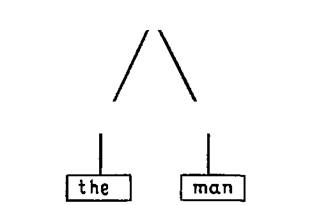 Рис. 9.2. И так далее. В результате этой процедуры, если она завершится успешно, мы выделим все словосочетания и их части, входящие в заданное предложение, в соответствии с тем, как они определены грамматикой, и получим структуру, подобную приведенной на рис. 9.3. Эта диаграмма, показывающая структуру разбиения предложения на словосочетания, называется деревом (синтаксического) разбора предложения. Мы увидели, как, имея грамматику языка, можно построить деревья разбора для предложений этого языка, чтобы показать их структуру. Задача построения дерева разбора предложения по заданной грамматике называется задачей синтаксического разбора (анализа). Программа для ЭВМ, которая строит деревья разбора для предложений языка, называется синтаксическим анализатором. В этой главе будет показано, как задача синтаксического анализа может быть сформулирована в рамках языка Пролог. Будет введен используемый в Прологе формализм грамматических правил, значительно облегчающий создание синтаксических анализаторов на Прологе. Область применения вводимых далее идей не ограничивается синтаксисом естественных языков. Действительно, те же самые методы применимы к любой задаче, объектом рассмотрения которой является упорядоченная последовательность элементов, которая некоторым естественным образом может быть разбита на группы, а порядок этих групп может быть определен множеством правил. Однако, ради простоты, в оставшейся части этой главы будет рассматриваться задача синтаксического анализа предложений на английском языке, а обобщение изложенных далее идей и методов на другие области предоставляется читателю. предложение 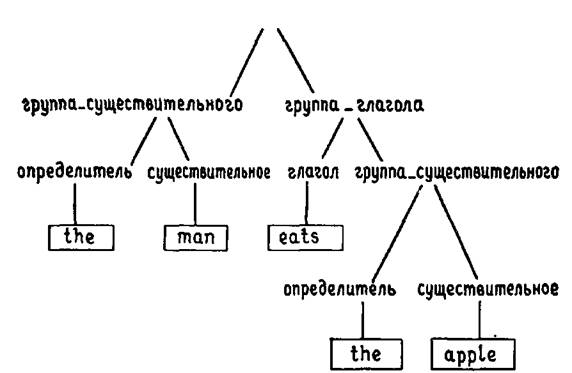 Рис. 9.3. 9.2. Описание синтаксического анализа на языке ПрологОсновная структура данных, о которой идет речь при обсуждении задачи синтаксического анализа, представляет последовательность слов. Предполагается, что можно выделить подпоследовательности этой структуры, представляющие различные словосочетания, допустимые грамматикой, и, основываясь на этом, показать, что последовательность в целом допустима в качестве словосочетания типа предложение. Так как стандартным способом представления последовательности является список, то входные данные для синтаксического анализатора будут представлены как список языка Пролог. А какое же представление имеют сами слова? Для решаемой здесь задачи знание внутренней структуры слов представляется несущественным, так как все, что необходимо делать,- это сравнивать слова друг с другом. Поэтому естественно представлять слова как атомы языка Пролог, Давайте разработаем программу, позволяющую определять, является ли заданная последовательность слов предложением в соответствии с приведенной выше грамматикой. Для того чтобы сделать это, программа будет должна выявить внутреннюю структуру заданных ей предложений. Далее будет показано, как разрабатывать программу, которая запоминает эту структуру и делает ее доступной для обозрения, но здесь этот вопрос не будет рассматриваться, чтобы не усложнять программу. Так как программа проверяет, является ли некоторая последовательность слов предложением, то давайте определим предикат предложение. Этот предикат использует лишь один аргумент и соответствует следующему утверждению: предложение(Х) означает, что X является последовательностью слов, образующей грамматически правильное предложение. Таким образом, предполагается, что можно задавать вопросы, подобные следующему: ?- предложение ([the, man, eats, the apple]). Ответом на этот вопрос будет «да», если «the man eats the apple» является предложением, и «нет» в противном случае. Представляется довольно неудачным, что мы должны задавать предложения искусственным способом, используя для этого списки атомов языка Пролог. Для более серьезных применений было бы желательно иметь возможность печатать английские предложения на терминале в их естественном виде. В главе 5 было показано, как может быть определен предикат ввести для того, чтобы преобразовывать напечатанное предложение в список атомов языка Пролог. Очевидно, что мы могли бы использовать этот предикат в нашем синтаксическом анализаторе, чтобы обеспечить естественный способ общения с пользователем программы. Однако здесь мы не будем прибегать к таким «косметическим» средствам, а сконцентрируем внимание на реальных проблемах собственно синтаксического анализа. В чем состоит проверка последовательности слов на принадлежность множеству правильных предложений? В соответствии с первым правилом грамматики, исходная задача сводится к нахождению словосочетания группа_существительного в начале заданной последовательности слов, а затем словосочетания груп-па_глагола в оставшейся части последовательности. К концу этого процесса мы должны использовать в точности все слова последовательности, ни одним словом больше и ни одним словом меньше. Введем предикаты группа_существительного и группа_глагола, чтобы выразить свойства принадлежности группе существительного и группе глагола: группа_существительного(Х) означает, что последовательность X является группой существительного. Аналогично, группа_глагола(Х) значит, что последовательность X является группой глагола. Используя эти предикаты, мы можем дать определение предиката предложение. Последовательность X является предложением, если ее можно разбить на две подпоследовательности Y и Z, где Y – это группа_существительного, Z – группа_глагола. Так как мы представляем последовательности как списки, то у нас уже есть предикат присоединить, выполняющий разбиение списка на два других. Таким образом, можно записать: предложение(Х):-присоединить(Y,Z,Х), группа_существительного(Y), группа_глагола(Z). Аналогично группа_существительного(Х):- присоединить(Y,Z,Х), определитель(Y), существительное(Z). группа_глагола(Х):- присоединить(Y,Z,Х), глагол(Y), группа_существительного(Z). группа_глагола(Х):- глагол(Х). Отметим, что два правила для предиката группа_ глагола превращаются в два утверждения для нашего предиката, что соответствует двум возможным способам проверки последовательности на принадлежность классу группа_глагола. И наконец, не составляет труда написать утверждения, соответствующие правилам, вводящим слова: определитель([the]). существительное([аррlе]). существительное([man]). глагол([eats]). глагол([sings]). Теперь наша программа завершена. Действительно, эта программа успешно идентифицирует последовательности слов, являющиеся предложениями для приведенной грамматики. Однако, прежде чем считать задачу решенной, следует посмотреть, что в действительности произойдет, когда мы зададим вопрос о некоторой последовательности слов. Рассмотрим утверждение для предиката предложение: предложение(Х):- присоединить(Y,Z,Х), группа_существительного(Y), группа_глагола(Z). и следующий вопрос: ?- предложение([the, man, eats, the, apple]). Переменная X в правиле конкретизируется значением [the, man, eats, the, apple], а переменные Yи Z не будут конкретизированы, так что данная цель будет порождать возможные пары значений для Y и Z такие, что результат присоединения списка Z к списку Y равен X. С помощью механизма возврата будут порождены все возможные пары, по одной при каждом возврате. Цель группа_ существительного будет выполняться лишь при условии, что Y действительно приемлем как группа_существительного. Иначе она не выполняется и присоединить будет вынужден найти другое значение для Y. Так что последовательность выполнения первой части предиката предложение будет следующей: 1. Целью является предложение(thе, man, eats, the, apple]). 2. Разбиение исходного списка на два списка Y и Z. Возможны следующие варианты разбиения; Y = [], Z = [the,man,eats,the,apple] Y = [the], Z = [man,eats,the,apple] Y= [the,man], Z = [eats,the,apple] Y= [the,man,eats], Z = [the,apple] Y= [the,man,eats,the], Z = [apple] Y= [the, man, eats, the, apple], Z = [] 3. Выбор варианта значений для Y и Z из приведенного выше списка вариантов и проверка принадлежности Y классу группа_существительного. То есть, попытка согласования подцели группа_существительного(Y). 4. Если группа_существительного выполняется для Y, то перейти к группа_глагола. Иначе возвратиться к шагу 3 и попробовать другой вариант. Очевидно, что при таком подходе выполняется совершенно ненужный поиск. Цель присоединить(Y,Z,X) порождает множество решений, большая часть которых бесполезна и не может быть идентифицирована как группа существительного. Должен существовать более прямой путь получения решения. Как следует из нашей грамматики, группа_существительного должна содержать в точности два слова. Этим можно было бы воспользоваться, чтобы не прибегать к поиску среди возможных вариантов разбиения исходной последовательности слов. Опасность заключается в том, что это не всегда так, если мы изменяем грамматику. Даже небольшое изменение в правиле для определитель могло бы повлиять на возможную длину группы существительного, а значит и на способ идентификации группы существительного. При разработке программы было бы хорошо сохранять некоторую модульность. Если мы хотим изменить одно утверждение, то это не должно вызывать изменение программы в целом. Таким образом, эвристика относительно длины группы существительного имеет слишком частный характер, чтобы ее использовать в программе. Тем не менее, ее можно рассматривать как частный случай некоторого общего принципа. Если мы хотим выделить подпоследовательность, которая является группой существительного, то мы можем использовать свойства этой группы, чтобы ограничить набор подходящих для этого последовательностей. Если определение группы существительного подвержено изменениям, то это можно сделать, только передав всю ответственность по проверке соответствующих свойств утверждению группа_существительного. Так как именно утверждение группа_ существительного выражает свойства, которыми обладает группа существительного, то почему не предположить, что этот предикат сам может решить, на что должна быть похожа соответствующая последовательность? Давайте потребуем, чтобы предикат группа_существительного сам решил, какая часть последовательности ему необходима и что необходимо оставить для последующей обработки предикатом группа_глагола. Это обсуждение приводит нас к новому определению предиката группа_существительного, который теперь имеет уже два аргумента: группа_существительного(Х, Y) истинно, если начальная часть последовательности X является группой существительного, а остальная часть последовательности есть Y. Таким образом, можно было бы ожидать, что следующие вопросы: ?- группа_существительного([the,man,eats,the,apple], [eats, the,apple]). ?- группа_существительного([thе,аррlе,sings], [sings]). должны иметь ответ «да». Теперь, чтобы отразить это изменение, мы должны пересмотреть определение предиката группа_существительного. Для этого надо решить, как последовательность, выбранная в качестве группы существительного, разбивается на последовательность, представляющую определитель, за которой следует последовательность, являющаяся существительным. Мы можем вновь предоставить решение задачи о том, какую часть последовательности следует выбрать, непосредственно тем утверждениям, которые обрабатывают соответствующие группы слов, положив: группа_существительного(Х,Y):- определитель(Х,Z), существительное(Z, Y). Таким образом, в начале последовательности X имеется группа, существительного, если мы можем выделить определитель в начале X, обозначив оставшуюся часть Z, а затем можем выделить существительное в начале Z. Часть последовательности, остающаяся после выделения группы существительного, совпадает с последовательностью, следующей за существительным. На диаграмме это выглядит так: [the, man, eats, the, apple] |--------------X--------------| |-----------Z-----------| |-------Y-------| Для того чтобы все происходило так, как здесь описано, мы должны будем принять относительно предикатов определитель и существительное соглашение, подобное тому, какое мы приняли для предиката группа_существительного. Приведенное утверждение для предиката группа_существи-тельного говорит о том, как задачу выделения группы существительного свести к задаче выделения определителя и следующего за ним существительного. Это аналогично сведению задачи разбора предложения к выделению группы существительного, за которой следует группа глагола. Все это очень абстрактно. Ничто из сказанного не говорит нам о том, как много слов входят в состав определителя, группы существительного или предложения. Эта информация должна извлекаться, исходя из нашей версии правил, которые фактически вводят английские слова. Мы вновь можем представить их в виде утверждений языка Пролог, но на этот раз мы должны добавить дополнительный аргумент, как например: определитель([the|Х],Х). Это правило (грамматики) выражает тот факт, что определитель стоит в начале последовательности, начинающейся со слова the. Более того, определитель занимает лишь первое слово этой последовательности и оставляет все следующие за ним. В действительности, для того чтобы показать, как в этой группе слов «используются» слова из последовательности и какая часть последовательности остается необработанной, к каждому предикату, распознающему группу слов некоторого вида, можно добавить дополнительный аргумент. В частности, для единообразия было бы разумно сделать то же самое и с предикатом предложение. Как теперь выглядит исходная цель, с которой мы обращаемся к программе? Необходимо решить, какие два аргумента задавать в вопросе для предиката предложение. Эти аргументы обозначают последовательность, с которой начинается обработка, и последовательность, оставшуюся после ее завершения. Очевидно, что первый из аргументов – тот же самый, что мы задавали ранее в предикате предложение. Кроме того, так как мы хотим выделить предложение, которое включает в себя всю последовательность целиком, то нам надо, чтобы после того, как предложение выделено, ничего не осталось, т. е. чтобы осталась лишь пустая последовательность. Поэтому мы должны обратиться к программе следующим образом: ?- предложение(the,man,eats,the,аррlе],[]). Посмотрим теперь, как выглядит грамматика в целом после того, как мы переписали ее с учетом обсуждавшихся выше изменений: предложение(S0,S):- группа_существительного(S0,S1), группа_глагола(S1,S). группа_существительного(S0,S):- определитель(S0,S1), существительное(S1,S). группа_глагола(S0,S):- глагол(S0,S). группа_глагола(S0,S):- глагол(S0,S1), группа_существительного(S1,S). определитель([the|S],S). существительное([man|S],S). существительное([аррle|S],S). глагол([eats|S],S). глагол([sings|S],S). Таким образом, теперь мы получили эффективную версию программы для распознавания предложений, допустимых грамматикой. Однако, к сожалению, последняя запись программы выглядит несколько беспорядочной по сравнению с предыдущей версией. Все дополнительные аргументы засоряют ее и их необходимость не очевидна. Теперь мы рассмотрим, как преодолеть эту проблему. 9.3. Запись грамматических правил в ПрологеСпециальная форма записи грамматических правил в языке Пролог была разработана, чтобы помочь программисту в написании синтаксических анализаторов, использующих описанные только что методы. Такая форма записи облегчает чтение программы, так как скрывается вся информация, не представляющая интереса. В силу того, что эта форма записи является более краткой, чем обычная для Пролога, вероятность сделать глупую опечатку также меньше, если для написания синтаксических анализаторов используются грамматические правила. Хотя форма записи грамматических правил, о которой здесь идет речь, вводится сама по себе, важно помнить, что это лишь сокращенная запись обычных Пролог-программ. Вы можете воспользоваться грамматическими правилами либо потому, что ваша Пролог-система уже знает, как их обрабатывать, либо потому, что имеется библиотечный пакет программ, позволяющий использовать специальную форму предиката consult. В любом случае, способ обработки грамматических правил системой заключается в распознавании их при вводе и трансляции на обычный Пролог. Таким образом, грамматические правила превращаются в обычные утверждения Пролога, хотя, естественно, выглядят несколько по-иному по сравнению с тем, что программист обычно вводит в систему. Рассматриваемая форма записи основывается на форме записи, использованной в начале этой главы для контекстно-свободных грамматик. Действительно, если бы грамматика, представленная в разд. 9.1 (она воспроизведена ниже), была введена в Пролог-систему, то она (грамматика) была бы оттранслирована в точности в те же самые утверждения, которые составляют последнюю версию программы синтаксического анализатора, приведенной в конце предыдущего раздела. предложение--› группа_существительного, группа_глагола. группа_существительного--› определитель, существительное. группа_глагола--› глагол. группа_глагола -› глагол, группа_существительного, определитель--› [the]. существительное--› [man]. существительное--› [apple]. глагол--› [eats]. глагол--› [sings]. На самом деле грамматические правила представляют структуры языка Пролог с главным функтором '--›' который объявлен как инфиксный оператор. Все, что должна сделать Пролог-система,- это проверить, имеет ли вводимый терм (при использовании предиката consult и ему подобных) указанный функтор и, если это так, оттранслировать его в соответствующее утверждение. Как происходит эта трансляция? Прежде всего, каждый атом, обозначающий класс словосочетания, должен быть оттранслирован в предикат с двумя аргументами – для входной последовательности и последовательности, остающейся после обработки, как в нашей программе. Затем, всякий раз, когда в правиле встречаются идущие одно за другим имена словосочетаний, соответствующие предикаты должны быть расположены так, чтобы аргументы показывали, что последовательность, которая остается после обработки одного словосочетания, образует входную последовательность для следующего словосочетания. И наконец, всякий раз, когда в правиле указывается, что словосочетание может быть реализовано как последовательность более мелких словосочетаний, аргументы должны говорить о том, что число слов, входящих в словосочетание, равно суммарному числу слов, входящих в более мелкие словосочетания, упоминаемые в правой части правила. Эти критерии гарантируют, например, что правило: предложение-› группа_существительного, группа_глагола. транслируется в утверждение: предложение (S0, S):- группа_существительного(S0,S1), группа_глагола(S1,S). или Между началом S0 и S имеется предложение, если между началом S0 и S1 имеется группа существительного, и если между началом S1 и S имеется группа глагола. Наконец, система должна знать, как транслировать правила, вводящие реальные слова. Трансляция таких правил производится путем включения слов в списки, образующие аргументы соответствующих предикатов, так что, например, правило определитель--› [the]. транслируется в утверждение: определитель(the|S],S). Если программа синтаксического анализатора представлена в виде совокупности грамматических правил, то каким образом надо задать целевые утверждения, чтобы можно было обработать их программой? Так как известно, как грамматические правила транслируются в утверждения обычного Пролога, то можно выразить целевые утверждения обычным образом, добавив при этом дополнительные аргументы. Первый добавляемый аргумент представляет обрабатываемый список слов, а второй аргумент соответствует списку слов, оставшемуся после обработки, который как правило является пустым списком []. Таким образом, целевое утверждение можно задать так: ?- предложение([thе, man, eats,the,apple],[]). ?- группа_существительного([the,man,sings],X). В некоторых реализациях Пролога в качестве альтернативы имеется встроенный предикат phrase, который просто добавляет дополнительные аргументы. Предикат определен следующим образом: phrase (P,L) истинно, если список L является допустимым словосочетанием типа Р. Таким образом, можно было бы заменить первое из приведенных выше целевых утверждений следующим: ?- phrase(прeдложeниe, [the,man,eats,the,apple]). Заметим, что определение предиката phrase предполагает, что обрабатывается весь список целиком, а список, оставшийся после обработки должен быть пустым. Поэтому второе целевое утверждение нельзя изменить, используя предикат phrase. Если в реализации Пролога нет встроенного предиката phrase, то его можно легко определить следующим образом: phrase(P,L):- Goal =.. [P,L,[]], call(Goal). Отметим однако, что данное определение будет не приемлемо, если используются более общие грамматические правила, о которых мы скажем в следующем разделе. Упражнение 9.1. Может быть вы захотите определить на Прологе процедуру translate таким образом, что translate(X,Y) истинно, если X – грамматическое правило (подобное тем, с какими мы сталкивались в этом разделе), a Y – терм, представляющий соответствующее утверждение Пролога. Это упражнение довольно трудное. Процедуры подобные translate имеются в Пролог-системе либо как встроенные, либо в виде библиотечных программ. Но если вы действительно напишите процедуру translate, то это поможет вам понять, что представляет собой процесс трансляции. 9.4. Присоединение дополнительных аргументовДо сих пор рассматривался лишь довольно ограниченный класс грамматических правил. В этом разделе мы введем одно полезное расширение, позволяющее использовать в грамматических правилах дополнительные аргументы. Это «расширение» не выходит за рамки стандартных средств, предоставляемых в Прологе для записи грамматических правил. Уже было показано, как имя некоторого класса словосочетаний, встретившееся в грамматическом правиле, транслируется в предикат, имеющий два дополнительных аргумента. Таким образом, грамматические правила приводят к множеству предикатов с двумя аргументами. Иногда при написании синтаксических анализаторов, помимо аргументов, служащих для представления обрабатываемой последовательности, могут потребоваться дополнительные аргументы, тем более, что предикаты в Прологе могут иметь произвольное число аргументов. Предлагаемая здесь форма представления грамматических правил обеспечивает такую возможность. Давайте рассмотрим пример, показывающий, когда такие дополнительные аргументы полезны. Разберем задачу «согласования числа» между подлежащим и сказуемым предложения. Последовательности слов подобные *The boys eats the apple. *The boy eat the apple. не являются грамматически правильными предложениями, даже если бы они и допускались грамматикой после незначительного ее расширения ('*' используется для обозначения грамматически неправильных предложений). Причина, по которой они не могут считаться грамматически правильными, состоит в том, что, если подлежащее в предложении употребляется в единственном числе, то и сказуемое в этом предложении должно быть глаголом в единственном числе. Аналогично, если подлежащее употребляется во множественном числе, то и сказуемое должно быть в форме множественного числа. Это можно было бы выразить в грамматических правилах, указав, что существуют два типа предложений: предложения с подлежащим в единственном числе и предложения с подлежащим во множественном числе. Предложение первого типа должно начинаться с группы существительного в единственном числе, в которую должно входить существительное, стоящее в форме единственного числа, и так далее. Это привело бы к следующему множеству правил: предложение--› предложение_едч. предложение--› предложение_мнч. группа_существительного--› группа_существительного_едч. группа_существительного--› группа_существительного_мнч. предложение_едч--› группа_существительного_едч, группа_глагола_едч. группа_существительного_едч--› определитель_едч, существительное_едч. группа_глагола_едч--› глагол_едч, группа_существительного. группа_глагола_едч--› глагол_едч. определитель_едч--› [the]. существительное_едч--› [boy]. глагол_едч--› [eats]. Аналогичное множество правил можно написать и на случай множественного числа. Такой способ согласования числа не очень изящен и скрывает тот факт, что структура предложений для единственного и множественного числа во многом совпадает. Более удачный способ состоит в том, чтобы связать с классами словосочетаний дополнительный аргумент, указывающий на использование единственного или множественного числа. Так предложение(едч) обозначает словосочетание предложение, употребленное в форме единственного числа. В общем случае, предложение (X) обозначает предложение, форма числа которого равна X. При этом правила согласования числа сводятся к условиям согласованности значений этих аргументов. Форма числа подлежащего в группе существительного должна совпадать с формой числа группы глагола и так далее. Переписав соответствующим образом грамматические правила, получаем: предложение--› предложение(Х). предложение(Х)--› группа_существительного(Х), группа _глагола(Х). группа_существительного(Х)--› определитель(Х), существительное(Х). группа_глагола(Х)--› глагол(Х). группа_глагола(X)--› глагол(Х), группа_существительного(Y). существительное(едч)--› [boy]. существительное(мнч) -› [boys]. определитель(_)--› [the]. глагол(едч)--› [eats]. глагол(мнч)--›[eat]. Обратим внимание на способ, каким можно определить форму числа для the. С этого слова могло бы начинаться словосочетание, употребленное в форме как единственного, так и множественного числа, и поэтому форма числа этого слова может быть сопоставлена с чем угодно. Отметим также, что во втором правиле для предиката группа_глагола имена переменных выражают факт, что форма числа группы глагола (которая должна быть согласована с формой числа подлежащего) определяется по форме числа глагола, а не по форме числа объекта, если таковой имеется. Можно ввести аргументы, выражающие другую важную информацию помимо согласования числа подлежащего и сказуемого. Например, их можно использовать для хранения перечня элементов, составляющих предложения, встретившихся не на своем обычном месте, и тем самым обрабатывать ситуации, называемые лингвистами «смещением». Или же они могут быть использованы для отражения семантических характеристик, указывающих, каким образом значение (смысл) словосочетания составляется из значений более мелких словосочетаний, входящих в исходное. Эти вопросы далее не будут обсуждаться, хотя в разд. 9.6 приведен простой пример использования семантической информации в синтаксическом анализаторе. Однако существует один момент, который здесь необходимо отметить. Лингвистам, возможно, интересно знать, что если в грамматические правила введены дополнительные аргументы, то нельзя гарантировать, что язык, определяемый этой грамматикой, по-прежнему остается контекстно-свободным языком, хотя довольно часто он будет таковым. Представляется важной возможность использования дополнительных аргументов для возврата дерева разбора, являющегося результатом синтаксического анализа. В главе 3 было показано, как можно представить деревья в виде структур Пролога. Здесь это будет использовано при расширении синтаксического анализатора с целью включить в него построение дерева разбора. Польза деревьев синтаксического разбора в том, что они дают структурное представление предложения. Удобно писать программы, которые обрабатывают эти структурные представления подобно тому, как обрабатывались арифметические формулы и списки в гл. 7. Новая программа для грамматически правильного предложения, такого например, как The man eats the apple. строит в качестве результата структуру вида: предложение( группа_существительного( определитель(thе), существительное(man)), группа_глагола( глагол(eats), группа_существительного(определитель(the),существительное(аррlе)) ) ) Чтобы добиться этого, необходимо лишь добавить дополнительные аргументы к каждому предикату, указывая, каким образом дерево, соответствующее всему словосочетанию в целом, конструируется из деревьев для частей этого словосочетания. Так первое правило можно изменить следующим образом: предложение(Х,предложение(NP,VP))--› группа_существительного(X,NP), группа_глагола(X,VP). Это правило указывает, что, если можно найти последовательность, составляющую группу существительного с деревом разбора NP, за которой следует последовательность, составляющая группу глагола, с деревом разбора VP то можно найти последовательность, составляющую полное предложение, и деревом разбора для этого предложения является предложениe(NP,VP). Или, в более процедурной формулировке: для того, чтобы выполнить разбор предложения необходимо найти группу существительного, за которой следует группа глагола, и затем объединить деревья разбора этих двух составляющих, используя функтор предложение для построения дерева разбора предложения. Отметим, что аргументы X – это аргументы, использовавшиеся ранее для согласования формы числа, и решение поставить аргументы для построения дерева разбора после, а не перед ними является совершенно произвольным. Если вам трудно понять это расширение возможностей грамматических правил, то полезно напомнить, что последнее правило представляет собою всего лишь краткую запись следующего утверждения на языке Пролог: предложение(Х,предложение(NР,VP),S0,S):-группа_существительного(Х,NР,S0,S1), группа_глагола(Х,VР,S1,S). где S0, S1 и S – части входной последовательности слов. Аргументы, предназначенные для построения дерева разбора, можно ввести в правила грамматики обычным образом. Здесь приведен получившийся после этого фрагмент грамматики (аргумент, используемый для согласования формы числа, для ясности опущен): предложение(предложение(NР,VP))--›группа _существительного (NP), группа _ глагола (VP). группа_глагола(группа_глагола(V))--› глагол(V). существительное(существительное(man)) – › [man]. глагол(глагол(eats))--› [eats]. Механизм трансляции, необходимый для перевода грамматических правил с дополнительными аргументами в утверждения Пролога, представляет простое расширение описанного ранее механизма. Ранее, для каждого класса словосочетаний создавался новый предикат с двумя аргументами, представляющими входную последовательность и последовательность, оставшуюся после обработки. Теперь надо создать предикат, имеющий на два аргумента больше, чем имеет соответствующее ему грамматическое правило. По соглашению, эти два дополнительных аргумента записываются в конце списка аргументов предиката (хотя в других Пролог-системах может использоваться иное соглашение). Таким образом, грамматическое правило предложение(Х)--› группа_существительного(Х),группа_глагола(Х). транслируется в утверждение предложение(Х,S0,S):- группа_существительного(Х,S0,S1),группа_глагола(Х,S1,S). При вызове целевых утверждений, содержащих грамматические правила, с самого верхнего уровня интерпретатора (т. е. из вопросов, задаваемых программистом.- Ред.) или из обычных правил Пролога, необходимо явным образом указать дополнительные аргументы, добавив их в конец списка аргументов. Таким образом, правильное целевое утверждение, содержащее обращение к функтору предложение, должно быть таким: ?- предложение(Х,[a,clergyman,eats,a, cake],[]). ?- предложение(Х, [every, bird, sings,and,pigs,can,fly],L). Упражнение 9.2. Напишите новый вариант предиката phrase, допускающий использование грамматических правил с дополнительными аргументами. Этот предикат должен допускать целевые утверждения вида: ?- phrase(предложение(Х),[the, man,sings]). 9.5. Введение дополнительных условийРассматривавшиеся до сих пор грамматические правила, входящие в программу синтаксического анализатора, содержали информацию лишь о том, какая часть входной последовательности обрабатывается каждым из правил. Каждый элемент описания правил должен содержать указание о том, как обрабатывать два дополнительных аргумента, добавленных транслятором грамматических правил. Так что каждое целевое утверждение в результирующем утверждении Пролога обрабатывало определенную часть входной последовательности. Иногда может возникнуть желание определить целевые утверждения иного типа, не связанные непосредственно с обработкой входной последовательности, и рассматриваемый формализм грамматических правил позволяет сделать это. В языке принято следующее соглашение: каждое целевое утверждение, заключенное в фигурные скобки {}, при трансляции не меняется. Рассмотрим несколько примеров ситуаций, в которых было бы полезно использовать эту возможность. Мы покажем, как можно улучшить «словарь» синтаксического анализатора, т. е. его «знания» о словах обрабатываемого языка. Прежде всего рассмотрим накладные расходы, связанные с введением нового слова в программу, в которой используются оба множества дополнительных аргументов (для согласования формы числа и для построения дерева разбора). Если нужно добавить новое слово, например banana, то для этого необходимо добавить хотя бы правило существительное(едч, существительное(banana))--› [banana]. которое сводится к следующему факту на Прологе: существительное(едч, существительное(banana),[banana|S],S). Это слишком большой объем информации для определения каждого существительного, особенно когда мы знаем, что каждое существительное представляется лишь одним элементом входного списка и порождает небольшое дерево с функтором существительное. Значительно более экономичный способ представления основывается на разделении информации. Информация, общая для всех существительных, помещается в одном месте, а информация о конкретных словах в другом месте. Это можно сделать, если одновременно использовать возможности грамматических правил и обычного Пролога. Общая информация о том, каким образом существительные входят в другие словосочетания, представляется с помощью грамматического правила, а информация о том, какие слова являются существительными, представляется с помощью обычных утверждений Пролога. Этот подход можно применить к последнему примеру следующим образом: существительное(S,существительное(N)) --› [N], {является_существительным(N,S)}. где обычный предикат является_существительным указывает, какие слова являются существительными и в какой форме - единственного или множественного числа – они употребляются. является_существительным(banana,едч). является_существительным(bananas,мнч). является_существительным(man,едч). . . . Давайте подробно разберем, что означает это грамматическое правило. Оно указывает, что словосочетание класса существительное может состоять из единственного слова N (переменная, определенная в списке), удовлетворяющего некоторому ограничению. Это ограничение заключается в том, что N должно входить в число слов, представленных предикатом является_существительным, с указанием конкретной формы числа S. В этом случае, форма числа словосочетания также S, а порождаемое дерево разбора состоит из двух вершин: вершины существительное и расположенной под ней вершины N. Почему целевое утверждение является_существительным (N,S) должно быть заключено в фигурные скобки? Потому, что оно выражает отношение, не имеющее ничего общего с обработкой входной последовательности. Если убрать фигурные скобки, то результат трансляции будет выглядеть примерно так: является_существительным(N,S,S1,S2) и это целевое утверждение никогда не было бы сопоставлено с утверждениями для является_существительным. Заключив целевое утверждение в фигурные скобки, мы тем самым предотвращаем какие-либо его изменения при трансляции. Так что правило будет правильно оттранслировано в следующее утверждение существительное(S,существительное(N),[N|Посл],Посл):- является_существительным(N,S). Несмотря на внесенное изменение, используемый способ обработки отдельных слов по-прежнему остается недостаточно изящным. Неудобство этого способа состоит в том, что для каждого вновь вводимого слова надо записывать два утверждения является_существительным – одно для формы единственного числа, а другое для формы множественного числа. Но в этом нет необходимости, поскольку для большинства существительных формы единственного и множественного числа связаны простым правилом: Если X – существительное в форме единственного числа, то слово, получаемое в результате прибавления 's' к концу слова X, является формой множественного числа этого существительного. Это правило можно использовать для пересмотра определения для существительное. В результате будет получено новое множество условий, которым должно удовлетворять слово N, для того, чтобы быть существительным. Так как эти условия связаны с внутренней структурой слова и не имеют никакого отношения к обработке входной последовательности, то они будут записаны с использованием фигурных скобок. Слова английского языка представляются как атомы Пролога и поэтому обсуждение вопроса разбиения слов на буквы сводится к рассмотрению литер, составляющих соответствующие атомы. Следовательно, в новом определении необходимо будет использовать предикат name. Улучшенный вариант правила выглядит следующим образом: существительное(мнч,существительное(КореньN))--› [N], {(name(М,Мнимя), присоединить(Едимя,"s",Мнимя), name(КореньN,Едимя), является_существительным(КореньN,едч))}. Конечно, представленное здесь общее правило о форме множественного числа существительных справедливо не во всех случаях (например, множественное число для «fly» не совпадает с «flys»), И по-прежнему необходимо исчерпывающим образом описывать все исключения. Обратите внимание на использование двойных кавычек для представления списка, содержащего литеру 's'. Теперь необходимо определять утверждения для предиката является_существительным лишь для существительных в единственном числе, если форма множественного числа для них образуется по указанному выше правилу. Заметьте, что в соответствии с приведенным определением в дерево разбора вставляется существительное в форме единственного, а не множественного числа. Это может оказаться полезным при последующей обработке дерева разбора. Обратите также внимание на то, как использованы фигурные скобки. В различных реализациях Пролога некоторые детали синтаксиса могут немного отличаться, но наиболее безопасно заключать содержимое фигурных скобок в дополнительные круглые скобки, если оно состоит более чем из одного целевого утверждения, и оставлять пропуск между фигурной скобкой и точкой, завершающей правило. Большинство трансляторов синтаксических правил, помимо целевых утверждений, заключенных в фигурные скобки, оставляют неизменными и некоторые другие целевые утверждения. Так, обычно нет необходимости заключать в фигурные скобки '!' или дизъюнкции (;) целевых утверждений. 9.6. ЗаключениеВ этом разделе мы подведем итог тем сведениям, которые мы получили о синтаксисе грамматических правил. Затем будут указаны некоторые из возможных расширений и показаны некоторые интересные способы использования грамматических правил. Лучший способ описать синтаксис грамматических правил – сделать это с помощью самих же грамматических правил. Таким образом, здесь приводится некоторое неформальное описание синтаксиса. Отметим, что оно не является абсолютно строгим, так как в нем не учитывается влияние приоритета операторов на синтаксис. грамматическое правило--› заголовок, ['--›'], тело. заголовок--› нетерминальный_символ. заголовок--› нетерминальный_символ, [','], терминальный_символ тело--› тело, [','], тело. тело--› тело, [';'], тело. тело--› элемент_тела. элемент_тела--› ['!']. элемент_тела--› ['{'], целевые_утверждения_пролога, ['}']. элемент_тела--› нетерминальный_символ. элемент_тела--› терминальный_символ. Ряд элементов описания неопределен. Здесь приведены их определения на естественном языке. нетерминальный_символ обозначает класс словосочетаний, которые могут входить во входную последовательность. Он имеет вид структуры языка Пролог, функтор которой обозначает категорию словосочетаний, а аргументы дают дополнительную информацию (форму числа, значение и так далее). терминальный_символ указывает ряд слов, которые могут быть частью входной последовательности. Он имеет вид списка языка Пролог и может быть либо пустым списком [], либо списком некоторой фиксированной длины. Элементы этого списка должны быть сопоставимы со словами последовательности в соответствии с заданным порядком. целевые_утверждения_пролога - это любые целевые утверждения языка Пролог. Они могут быть использованы для записи дополнительных условий и действий, ограничивая возможные пути анализа и указывая, как сложные результаты строятся из простых. При трансляции на Пролог, целевые_утверждения_пролога остаются неизменными, а нетерминальный_символ получает два дополнительных аргумента, которые вставляются после явно указанных аргументов. Дополнительные аргументы соответствуют последовательности, в которой выделяется словосочетание, и последовательности, которая остается после выделения словосочетания. Терминальные символы появляются среди дополнительных аргументов нетерминальных символов. При вызове предиката, определенного грамматическими правилами, с верхнего уровня интерпретатора или из обычного правила Пролога необходимо явно указать два дополнительных аргумента. Во втором правиле для предиката заголовок описывается класс грамматических правил, с которыми нам еще не приходилось сталкиваться. До сих пор определения терминальных и нетерминальных символов содержали информацию лишь о том, как они обрабатывают входную последовательность. Иногда может возникнуть желание определить правила таким образом, чтобы они вставляли элементы во входную последовательность (для обработки другими правилами). Например, предложение в повелительном наклонении можно было бы анализировать следующим образом. В исходное предложение Eat your supper. вставляется дополнительное слово: You eat your supper. Получившееся предложение имеет правильную структуру, согласующуюся с нашими представлениями о структуре предложений. Это можно сделать, используя грамматическое правило вида: предложение--› императив, группа_существительного, группа_глагола. императив,[you]--› []. императив--› []. Из приведенных здесь правил лишь одно заслуживает внимания. Это первое правило для императив, которое транслируется в утверждение императив(L,[уоu|L]). То есть, последовательность, возвращаемая после обработки, длиннее исходной последовательности. В общем случае, левая часть грамматического правила может включать нетерминальный символ, за которым, через запятую, следует список слов. Смысл такого правила состоит в том, что в процессе разбора предложения слова, указанные в списке, вставляются во входную последовательность после того, как завершится обработка целевыми утверждениями в правой части правила. Упражнение 9.3. Приведенное определение для грамматических правил, даже если бы оно было полным, не сможет выполнить функции синтаксического анализатора, если на вход ему подавать последовательность знаков. Почему? В заключение рассмотрим пример грамматических правил, используемых для непосредственного извлечения «смысла» предложений, минуя этап построения дерева разбора. Этот пример взят из статьи Pereira, Warren, Artificial Intelligence, v. 13. Представленные далее правила транслируют предложения из ограниченного подмножества предложений английского языка в некоторое представление на языке исчисления предикатов, отражающее смысл этих предложений. Описание исчисления предикатов и используемой формы записи даны в гл. 10. В качестве примера работы программы мы приведем предложение «every man loves a woman» и соответствующую структуру, отражающую его смысл:[14] all(X,(man(X)→exists(Y,(woman(Y)& loves(X,Y))))) Здесь представлены грамматические правила программы: ?- op(100,xfy,&) ?- op(150,xfy,→) предложение(Р)--› группа_существительного(Х,Р1,Р),группа_глагола(Х,Р1). группа_существительного(Х,Р1,Р)--›определитель(Х,Р2,Р1,Р),существительное(Х,Р3), отн_утверждение(Х,Р3,Р2). группа_существительного(Х,Р,Р)--› наст_существительное(Х). группа_глагола(Х,Р)--› перех_глагол(Х,Y,Р1),группа_существительного(Y,Р1,Р). группа_глагола(Х,Р)--› неперех_глагол(Х,Р). отн_утверждение(Х,Р1,(Р1&Р2))--› [that], группа_глагола(Х,Р2). отн_утверждение(_,Р,Р)--› []. определитель(Х,Р1,Р2,аll(Х,(Р1>Р2)))--› [every]. определитель(Х,Р1,Р2,ехists(Х,(Р1&Р2)))--› [а]. существительное(Х,man(Х))--› [man]. существительное(Х, woman (X))--› [woman]. наст_существительное(john)--› [john]. пepex_глагол(X,Y,loves(X,Y))--› [loves]. неперех_глагол(Х,lives(Х)))--› [lives]. В этой программе аргументы используются для построения структур, представляющих смысл словосочетаний. Смысл каждого словосочетания определяет последний аргумент соответствующего правила. Однако смысл словосочетания может зависеть от некоторых других факторов, представленных другими аргументами. Например, глагол lives (живет) порождает высказывание вида lives(X), где X – это объект, обозначающий человека, который живет. Смысл слова lives не позволяет заранее определить, чем будет являться X. Чтобы быть полезным, понятие подобное lives должно быть применимо к некоторому конкретному классу объектов. Что представляет этот объект, будет определено из контекста, в котором используется глагол lives. Таким образом, имеем следующее определение: для любого X, применение глагола lives к X имеет смысл lives(X). Слово, подобное every (каждый), является значительно более сложным. В этом случае понятие, соответствующее слову, должно применяться к некоторой переменной и к двум высказываниям, содержащим эту переменную. Результат можно сформулировать так: если подстановка некоторого объекта вместо переменной в первом утверждении делает что-то истинным, то подстановка того же объекта вместо переменной во втором утверждении также сделает что-то истинным. Упражнение 9.4. Разберитесь в приведенной программе. Попробуйте проследить выполнение программы при обращении к ней с вопросами типа ?- предложение(Х, [every, man, loves, a, woman],[]). Во что транслируются программой предложения «Every man that lives loves a woman» и «Every man that loves a woman lives». Предложение «Every man loves a woman» является в действительности двусмысленным - может существовать либо единственная женщина, которая нравится каждому мужчине, либо несколько женщин, каждая из которых нравится мужчине. Может ли программа породить альтернативные решения, описывающие смысл каждой из двух указанных интерпретаций предложения? Если нет, то почему? Какое простое предположение о построении структуры, отражающей смысл предложения, было сделано при написании программы? Примечания:1 В книге термин «Пролог» употребляется в трех значениях: 1) Пролог – язык программирования с совокупностью синтаксических и семантических правил записи программ; 2) Пролог – программная система (интерпретатор), реализующая язык; эта система и осуществляет диалог с пользователем; 3) Пролог – машина, на которой Пролог-система выполняет (интерпретирует) программы, написанные на языке Пролог. Как правило, из контекста всегда ясно, какое значение используется в каждом конкретном случае. При необходимости явного указания при переводе использовались термины: «язык Пролог», «Пролог-система», «Пролог-машина». - Прим. пepeв. 14 На «ломаном» русском языке этот пример можно представить следующим образом: «Каждый мужчина нравится некоторая женщина». все (X, мужчина (X)--› существует (Y, (женщина (Y) & нравится (X)))). - Прим. ред. |
|
||
| Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх | ||||
|
|
||||