|
||||
|
|
ТЕМА НОМЕРА: Архитектура CPUВ 70-х годах прошлого столетия проектирование и изготовление центральных процессоров было занятием, принципиально доступным каждому. Если какому-нибудь сотруднику, скажем, Стэндфордского университета приходила в голову интересная идея, он мог легко набрать команду, основать фирму, найти инвесторов и уже через год-два выбросить на рынок свои CPU. Через тридцать с небольшим лет процессоры усложнились до такой степени, что разработка хоть сколько-нибудь быстрого по современным меркам кристалла требует огромной армии инженеров, гигантских инвестиций и целого моря времени. И дело здесь отнюдь не в тонких кремниевых технологиях и стоящих миллиарды долларов полупроводниковых фабриках - просто уже в 80-х годах разработка принципиально нового CPU требовала двух-трех, а в 90-х - пяти-шести лет напряженной работы. Те же китайцы, даже располагая подробной информацией о тридцатилетней истории проектирования процессоров, владея новейшими фабриками по производству кремниевых кристаллов и не стремясь изобретать что-то новое, потратили на разработку собственного простейшего MIPS32-подобного процессора Godson (примерно эквивалентного по производительности i486) несколько лет. Это не считая еще одного года, когда новый кристалл отлаживали. А на разработку MIPS64-подобной архитектуры с приемлемой производительностью (~Pentium III 500-600 МГц) у китайской Академии наук ушло еще четыре года, - четыре года, потраченных только на то, чтобы повторить успех более чем двенадцатилетней давности. Но почему все получается так сложно? Чтобы ответить на этот вопрос нам придется вернуться на 30-40 лет в прошлое Шаг первый. CISC Так уж исторически сложилось, что поначалу совершенствование процессоров было направлено на то, чтобы сконструировать по возможности более функциональный компьютер, который позволил бы выполнять как можно больше разных инструкций. Во-первых, так было удобнее для программистов (компиляторы языков высокого уровня еще только начинали развиваться, и все по-настоящему важные программы писались на ассемблере), а во-вторых, использование сложных инструкций зачастую позволяло сильно сократить размеры написанной на ассемблере программы. А где меньше инструкций - меньше и затраченное на исполнение программы время. Надо признать, что достигнутые на этом пути успехи действительно впечатляли - в последних версиях ЭВМ выразительность ассемблерного листинга зачастую не уступала выразительности программы, написанной на языке высокого уровня. Одной-единственной машинной инструкцией можно было сказать практически все, что угодно. К примеру, такие машины, как DEC VAX, аппаратно поддерживали инструкции «добавить элемент в очередь», «удалить элемент из очереди» и даже «провести интерполяцию полиномом» (!); а знаменитое семейство процессоров Motorola 68k почти для всех инструкций поддерживало до двенадцати (!) режимов адресации памяти, вплоть до взятия в качестве аргумента инструкции «данных, записанных по адресу, записанному вон в том регистре, со смещением, записанным вот в этом регистре». Отсюда и общее название соответствующих архитектур: CISC - Complex Instruction Set Computers («компьютеры с набором инструкций на все случаи жизни»). На практике это привело к тому, что подобные инструкции оказалось сложно не только выполнять, но и просто декодировать (выделять из машинного кода новую инструкцию и отправлять ее на исполнительные устройства). Чтобы машинный код CISC-компьютеров из-за сложных инструкций не разрастался до огромного размера, машинные инструкции в большинстве этих архитектур имели неоднородную структуру (разное расположение и размеры кода операции и ее операндов) и сильно отличающуюся длину (в x86, например, длина инструкций варьируется от 1 до 15 байт). Еще одной проблемой стало то, что при сохранении приемлемой сложности процессора многие инструкции оказалось принципиально невозможно выполнить «чисто аппаратно», и поздние CISC-процессоры были вынуждены обзавестись специальными блоками, которые «на лету» заменяли некоторые сложные команды на последовательности более простых. В результате все CISC-процессоры оказались весьма трудоемкими в проектировании и изготовлении. Но что самое печальное, к моменту расцвета CISC-архитектур стало ясно, что все эти конструкции изобретались в общем-то зря - исследования программного обеспечения того времени, проведенные IBM, наглядно показали, что даже программисты, пишущие на ассемблере, все эти «сверхвозможности» почти никогда не использовали, а компиляторы языков высокого уровня - и не пытались использовать. К началу 80-х годов классические CISC полностью исчерпали себя. Расширять набор инструкций в рамках этого подхода дальше не имело смысла, наоборот - технологи столкнулись с тем, что из-за высокой сложности CISC-процессоров оказалось трудно наращивать их тактовую частоту, а из-за «тормознутости» оперативной памяти тех времен зашитые в память процессора расшифровки сложных инструкций зачастую работают медленнее, чем точно такие же цепочки команд, встречающиеся в основной программе. Короче говоря, стало очевидным, что CISC-процессоры нужно упрощать - и на свет появился RISC, Reduced Instruction Set Computer. Регистровые окна SPARC При построении RISC-процессоров принимается во внимание медлительность оперативной памяти. Обращения к ней (даже с учетом различных кэшей) - «дорогостоящи» и требуют дополнительных вычислений, а потому, насколько это возможно, их следует избегать. Но Load/Store-архитектура и большое число регистров - не единственное, что можно сделать. В любом программном коде можно встретить немало вызовов функций - фактически требований к процессору перейти в заданное место программы, продолжить выполнение программы до специальной инструкции возврата, после чего - вернуться к тому месту, где произошел вызов, почти полностью восстановив свое состояние до вызова функции. Чтобы это можно было сделать, при вызове функции процессор должен «запомнить» свое текущее состояние - в частности, содержимое некоторых регистров общего назначения и значительной части специальных регистров. Традиционное решение - «запихнуть» все необходимые данные в специальную конструкцию - стек[ Стек можно условно представить как запаянную с одного конца трубку, в которую по одному кладутся и по одному же извлекаются шарики (данные). Первый положенный в трубку шарик извлекается последним, так что если мы, скажем, по очереди положим (push) в стек числа 1, 2, 3, то извлекая (pop) данные, мы поочередно достанем 3, 2, 1.], которую процессор поддерживает на аппаратном уровне и которая в большинстве процессоров реализована в виде пары служебных регистров и выделенного участка оперативной памяти, куда все складываемые в стек данные и записываются. Поэтому любой вызов функции в традиционной схеме неявным образом приводит к записи в оперативную память десятков, а то и сотен байт информации. Есть даже целый ряд модельных задачек на эту тему - как написать компилятор, минимизирующий количество сохраняемой информации; причем кое-какие из этих наработок поддерживаются популярными компиляторами (например, соглашение __fastcall в некоторых компиляторах C/C++). Но оказывается, что всего этого можно избежать. В типичной SPARC-архитектуре используется регистровый файл из 128 регистров; причем пользователю из них одномоментно доступны только расположенные подряд 24 регистра, образующие в этом файле окно, плюс еще восемь стоящих особняком глобальных регистров. Глобальные регистры используются для глобальных переменных[В структурных языках программирования типа C принято разделять локальные переменные, которые определены и используются только одной конкретной функцией и существуют только то время, пока эта функция работает; и глобальные переменные, которые существуют все время, пока выполняется программа, и доступны всем функциям программы]; регистровое окно - для локальных. Когда нам нужно вызвать какую-нибудь функцию, мы записываем необходимые для ее работы исходные данные в конец окна, а процессор при вызове функции попросту смещает окно по регистровому файлу таким образом, чтобы записанные данные оказались в начале нового, пока пустого окна. Требовавшие сохранения временные данные вызывавшего функцию кода оказываются за пределами окна, так что испортить их нечаянными действиями невозможно. А когда функция заканчивает работу, то полученные результаты записываются в те же самые регистры в начале окна, после чего процессор смещает его обратно. И никаких расходов на сохранение-восстановление стека. Расположение окон в SPARC’ах можно программировать, добиваясь максимально эффективного использования схемы (либо много окон, но маленьких, либо мало - но больших; в зависимости от того, что за функции встречаются в программе) - этот факт даже отражен в названии процессора (Scalable Processor ARChitecture). Подобно многим своим RISC-сестрам, разработанная в середине 80-х годов и пережившая расцвет в середине 90-х, SPARC-архитектура не выдержала «гонки мегагерц» и сегодня фактически умерла. Но предложенный ею подход живет и здравствует - его позволяет использовать, например, архитектура IA-64 (Itanium). Шаг второй. RISC Точно так же, как когда-то CISC-процессоры проектировались под нужды asm-программистов, RISC проектировался в расчете на типовой код, генерируемый компиляторами. Для начала разработчики свели к минимуму набор инструкций и к абсолютному минимуму - количество режимов адресации памяти; упаковав все, что осталось, в простой и удобный для декодирования регулярный машинный код. В частности, в классическом варианте RISC из инструкций, обращающихся к оперативной памяти, оставлены только две (Load - загрузить данные в регистр и Store - сохранить данные из регистра; так называемая Load/Store-архитектура), и нет ни одной инструкции вроде вычисления синуса, косинуса или квадратного корня (их можно реализовать «вручную»), не говоря уже о более сложных[Канонический пример - инструкция INDEX, выполнявшаяся на VAX медленнее, чем вручную написанный цикл, выполняющий ровно тот же объем работы]. Да что там синус с косинусом - в некоторых RISC-процессорах пытались отказаться даже от трудно реализуемого аппаратного умножения и деления! Правда, до таких крайностей ни один коммерческий RISC, к счастью, не дошел, но как минимум две попытки (ранние варианты MIPS и SPARC) предприняты были. Второе важное усовершенствование RISC-процессоров, целиком вытекающее из Load/Store-архитектуры, - увеличение числа GPR (регистров общего назначения). Варианты, у которых меньше шестнадцати GPR, - большая редкость, причем почти все эти регистры полностью равноправны, что позволяет компилятору свободно распоряжаться ими, сохраняя большую часть промежуточных данных именно там, а не в стеке или оперативной памяти. В некоторых архитектурах, типа SPARC, «регистровость» возведена в абсолют, в некоторых - оставлена на разумном уровне; однако почти любой RISC-процессор обладает куда большим набором регистров, чем даже самый продвинутый CISC. Для сравнения: в классическом x86 IA-32 всего восемь регистров общего назначения, причем каждому из них приписано то или иное «специальное назначение» (скажем, в ESP хранится указатель на стек) затрудняющее или делающее невозможным его использование. Среди прочих усовершенствований, внесенных в RISC, - такие нетривиальные идеи, как условные инструкции ARM или режимы работы команд[Например, некий модификатор в архитектуре PowerPC и некоторых других показывает, должна ли инструкция выставлять по результатам своего выполнения определенные флаги, которые потом может использовать инструкция условного перехода, или не должна. Это позволяет разнести в пространстве инструкцию, выполняющую вычисление условия, и инструкцию собственно условного перехода - что в конвейерных архитектурах зачастую позволяет процессору не «гадать», будет совершен переход или нет, а сразу достоверно это знать]. В классическом CISC они почти не встречаются, поскольку на момент разработки соответствующих наборов инструкций ценность этих решений была сомнительной (они выйдут на сцену только в конвейеризированных процессорах). «В чистом виде» идею «легкого» RISC-процессора можно встретить у компании ARM с ее невероятно простыми и тем не менее весьма эффективными 32-разрядными CPU. Но простота далеко не главный показатель в процессоре, и как самоцель подход RISC в целом себя, наверное, не оправдал бы - резко уменьшившаяся сложность CPU и сопутствующее увеличение тактовой частоты и ускорение исполнения инструкций хорошо уравновешивались возросшими размерами программ и сильно упавшей их вычислительной плотностью[Среднее количество вычислений на единицу длины машинного кода]. К счастью, в то же время, когда начались разработки первых коммерческих RISC-процессоров, был сделан… Условные инструкции ARM Архитектура ARM (Advanced RISC Machines) разработана в 1983-85 годах в компании Acorn Computers. Команда Роджера Вильсона и Стива Фербера взяла за основу набора инструкций ARM некогда популярный, а ныне забытый процессор MOS Technology 6502 и снабдила его специальным четырехбитным кодом условия, которым можно было дополнить любую инструкцию. Идея условных инструкций проста, как все гениальное: инструкция с условным кодом выполняется, только если в процессоре выставлен бит соответствующего условия. В противном случае она игнорируется. Ближайший аналог в наборе инструкций x86 - инструкции условного перехода, срабатывающие, только если в процессоре был выставлен тот или иной флаг; в архитектуре ARM подобные «условности» применимы к любой инструкции, а флаги можно определять самостоятельно. Идея в том, что в коде типа Если (условие) то Выполнить1 иначе Выполнить 2 вместо того, чтобы записать традиционную конструкцию 1 Вычислить условие 2 Если условие выполнено, то идти к 5 3 Выполнить2 4 Идти к 6 5 Выполнить1 используя условные инструкции, можно записать 1 Вычислить условие и поставить Флаг1 по результатам вычисления 2 Выполнить1 при условии выставленного Флаг1 3 Выполнить2 при условии невыставленного Флаг1 Обратите внимание, что получившийся код не только более компактен, но и лишен одного условного и одного безусловного перехода, присутствовавших в классическом варианте, - тех самых переходов, которые обычно больно бьют по производительности конвейерных архитектур. Еще ряд дополнений в ARM предусматривал введение инструкций, одновременно выполняющих несколько простых операций, тем самым избавляя регистры процессора от необходимости сохранять результаты промежуточных вычислений и увеличивая вычислительную плотность кода. Этот подход нетипичен для RISC-процессоров, поскольку плохо вписывается в «основную идею» их максимального упрощения, но в конечном счете он привел к тому, что процессоры Acorn при прочих равных получили большую производительность на единицу частоты. Конечно, ARM-подход тоже имеет недостатки (например, необходимость выполнять пустые инструкции), однако в общем и целом он позволяет создавать очень простые процессоры с очень хорошей производительностью. В 1985 вышел первенец архитектуры ARM - 32-разрядный процессор ARM1; в 1986-м - первый коммерческий вариант архитектуры, процессор ARM2. ARM2 был настоящим шедевром - в его ядре насчитывалось всего 30 тысяч транзисторов (вчетверо меньше, чем в i80286, и втрое меньше, чем в MC68000); он отличался крайне низким энергопотреблением и обладал при всем при том производительностью, превосходящей производительность 286-го процессора (не говоря уже о том, что 286-й был 16-разрядным, а ARM2 - 32-разрядным процессором). Немного позже увидел свет и ARM3, в котором появилось четыре килобайта кэш-памяти, еще увеличившей производительность процессоров ARM. Трудно сказать, ожидала ли Acorn Computers такого успеха, однако воспользовалась им в полной мере. В 1990 году Acorn, работавшая над развитием ARM уже в сотрудничестве с Apple, преобразовала подразделение, занимавшееся ARM, в отдельную фирму- Advanced RISC Machines. Результатом совместной работы стало ядро ARM6 и процессор ARM610, использовавшийся, в частности, в одном из первых КПК в мире - Apple Newton. Ядро ARM6 было по-прежнему невероятно простым (всего 35 тысяч транзисторов!), мало потребляющим и обеспечивало приличный уровень производительности. Поскольку тягаться в производительности с гораздо более сложными монстрами вроде i386 оно не могло (да и ниша высокопроизводительных вычислений была прочно занята MIPS), руководство Advanced RISC Machines избрало оригинальный способ ведения бизнеса - позиционировав ARM6 как «встраиваемое» вычислительное ядро, которое любой желающий за сравнительно небольшие деньги мог интегрировать в свои специализированные процессоры. Ядро ARM6 вышло столь удачным и так хорошо подходило для этой бизнес-модели (благодаря простоте, его можно было изготавливать даже на сильно устаревшем дешевом оборудовании), что вскоре архитектура ARM получила широчайшее распространение. Самый яркий пример подобного «гибрида» - ядро ARM7TDMI, являющееся основой для подавляющего большинства процессоров сотовых телефонов. Сегодня ARM используется в более чем 75% всех интегрированных процессоров, выпускаемых в мире, - от контроллеров жестких дисков, калькуляторов и микропроцессоров игрушек до сетевых маршрутизаторов. То есть там, где от процессора не требуется очень высокого быстродействия. Другое направление, которым сегодня «жива» ARM, - это более производительная архитектура StrongARM, широко используемая в КПК, коммуникаторах и некоторых терминалах. StrongARM была разработана в 1995 году компанией DEC совместно с ARM; а позднее, после судебного разбирательства, - продана вместе с соответствующим подразделением корпорации Intel, которая сейчас и занимается ее развитием в виде линейки процессоров XScale. Шаг 3. Введение конвейера Идея конвейера, давным-давно предложенная Генри Фордом, состоит в том, что производительность цепочки последовательных действий определяется не сложностью этой цепочки, а лишь длительностью самой сложной операции. Иными словами, совершенно неважно, сколько человек занимаются производством автомобиля и как долго длится его изготовление в целом, - важно то, что если каждый человек в цепочке тратит, скажем, на свою операцию одну минуту, то с конвейера будет сходить один автомобиль в минуту, ни больше и ни меньше; независимо от того, сколько операций нужно совершить с отдельным автомобилем и сколько заняла бы его сборка одним человеком. Применительно к процессорам принцип конвейера означает, что если мы сумеем разбить выполнение машинной инструкции на несколько этапов, то тактовая частота (а вернее, скорость, с которой процессор забирает данные на исполнение и выдает результаты) будет обратно пропорциональна времени выполнения самого медленного этапа. Если это время удастся сделать достаточно малым (а чем больше этапов на конвейере, тем они короче), то мы сумеем резко повысить тактовую частоту, а значит, и производительность процессора. Процедуру выполнения практически любой инструкции можно разбить как минимум на пять непересекающихся этапов: Выборка инструкции (FETCH) из памяти. Из программы извлекается инструкция, которую нужно выполнить. Декодирование инструкции (DECODE). Процессор «соображает», что от него хотят, и переправляет запрос на нужное исполнительное устройство. Подготовка исходных данных для выполнения инструкции. Собственно выполнение инструкции (EXECUTE). Сохранение полученных результатов. Конвейеризация потенциально применима к любой процессорной архитектуре, независимо от набора команд и положенных в ее основу принципов. Даже самый первый x86-процессор, Intel 8086, уже содержал своеобразный примитивный «двухстадийный конвейер» - выборка новых инструкций (FETCH) и их исполнение осуществлялись в нем независимо друг от друга. Однако реализовать что-то более сложное для CISC-процессоров оказалось трудно: декодирование неоднородных CISC-инструкций и их очень сильно различающаяся сложность привели к тому, что конвейер получается чересчур замысловатым, катастрофически усложняя процессор. Подобных трудностей у RISC-архитектуры гораздо меньше (а SPARC и MIPS, например, и вовсе были специально оптимизированы для конвейеризации), так что конвейеризированные RISC-процессоры появились на рынке много раньше, чем аналогичные x86. Недостатки конвейера неочевидны, но, как обычно и бывает, из-за нескольких «мелочей» реализовать грамотно организованный конвейер совсем не просто. Основных проблем три. Необходимость наличия блокировок конвейера. Дело в том, что время исполнения большинства инструкций может очень сильно варьироваться. Скажем, умножение (и тем более деление) чисел требуют (на стадии EXECUTE) нескольких тактов, а сложение или побитовые операции - одного такта; а для операций Load и Store, которые могут обращаться к разным уровням кэш-памяти или к оперативной памяти, это время вообще не определено (и может достигать сотен тактов). Соответственно, должен быть какой-то механизм, который бы «притормаживал» выборку и декодирование новых инструкций до тех пор, пока не будут завершены старые. Методов решения этой проблемы много, но их развитие приводит к одному - в процессорах прямо перед исполнительными устройствами появляются специальные блоки-диспетчеры (dispatcher), которые накапливают подготовленные к исполнению инструкции, отслеживают выполнение ранее запущенных инструкций и по мере освобождения исполнительных устройств отправляют на них новые инструкции. Даже если исполнение займет много тактов - внутренняя очередь диспетчера позволит в большинстве случаев не останавливать подготавливающий все новые и новые инструкции конвейер[Новые инструкции тоже не каждый такт удается декодировать, так что возможна и обратная ситуация: новых инструкций за такт не появилось, и диспетчер отправляет инструкции на выполнение «из старых запасов»]. Так в процессоре возникает разделение на две независимо работающие подсистемы: Front-end (блоки, занимающиеся декодированием инструкций и их подготовкой к исполнению) и Back-end (блоки, собственно исполняющие инструкции). Необходимость наличия системы сброса процессора. Поскольку операции FETCH и EXECUTE всегда выделены в отдельные стадии конвейера, то в тех случаях, когда в программном коде происходит разветвление (условный переход), зачастую оказывается, что по какой из веток пойти - пока неизвестно: инструкция, вычисляющая код условия, еще не выполнена[Вот здесь-то и нужны те самые режимы выставления флагов PowerPC, о которых шла речь в сноске 2]. В результате процессор вынужден либо приостанавливать выборку новых инструкций до тех пор, пока не будет вычислен код условия (а это может занять очень много времени и в типичном цикле страшно затормозит процессор), либо, руководствуясь соображениями блока предсказания переходов, «угадывать», какой из переходов скорее всего окажется правильным. Наконец, конвейер обычно требует наличия специального планировщика (scheduler), призванного решать конфликты по данным. Если в программе идет зависимая цепочка инструкций (когда инструкция-2, следующая за инструкцией-1, использует для своих вычислений данные, только что вычисленные инструкцией-1), а время исполнения одной инструкции (от момента запуска на стадию EXECUTE и до записи полученных результатов в регистры) превосходит один такт, то мы вынуждены придержать выполнение очередной инструкции до тех пор, пока не будет полностью выполнена ее предшественница. К примеру, если мы вычисляем выражение вида A•B+C с сохранением результата в переменной X (XfA•B+C), то процессор, выполняя соответствующую выражению цепочку из двух команд типа R4fR1•R2; R0fR3+R4, должен вначале дождаться, пока первая инструкция сохранит результат умножения A•B, и только потом прибавлять к полученному результату число С. Цепочки зависимых инструкций в программах - скорее правило, нежели исключение, а исполнение команды с записью результата в регистры за один такт - наоборот, скорее исключение, нежели правило, поэтому в той или иной степени с проблемой зависимости по данным любая конвейерная архитектура обязательно сталкивается. Оттого-то в конвейере и появляются сложные декодеры, заранее выявляющие эти зависимости, и планировщики, которые запускают инструкции на исполнение, выдерживая паузу между запуском главной инструкции и зависимой от нее. Ну как вам список проблем? Идея конвейера в процессоре очень красива на словах и в теории, однако реализовать ее даже в простом варианте чрезвычайно трудно. Но выгода от конвейеризации столь велика и несомненна, что приходится с этими трудностями мириться, ведь ничего лучшего до сих пор не придумано. В 1991-92 годах корпорация Intel, освоив производство сложнейших кристаллов с более чем миллионом транзисторов, выпустила i486 - классический CISC-процессор архитектуры x86, но с пятистадийным конвейером. Чтобы вы смогли оценить этот рывок, приведу две цифры: тактовую частоту по сравнению с i386 введение конвейера позволило увеличить втрое, а производительность на единицу частоты - вдвое[В i386 многие инструкции выполнялись за несколько тактов; а в i486 среднее «время» исполнения инструкции в тактах удалось снизить почти вдвое]. Правда, расплатой за это стала чудовищная сложность ядра i486; но такие «мелочи» по меркам индустрии центральных процессоров - пустяк: быстро растущие технологические возможности кремниевой технологии уже через пару лет позволили освоить производство i486 всем желающим. Но к тому моменту RISC-архитектуры сделали еще один шаг вперед - к суперскалярным процессорам MIPS-архитектура: «Pentium 4» 80-х годов MIPS (Microprocessor without Interlocked Pipeline Stages), «процессор без блокировок в конвейере». Основная идея, которой руководствовался Джон Хеннеси, со своей командой проектировавший в 1981 году первый MIPS-процессор, такова. Сильно упростив внутреннее устройство CPU и используя очень длинный (по тем временам) конвейер, можно получить процессор, не умеющий выполнять сравнительно сложные инструкции, зато работающий на очень высоких тактовых частотах, позволяющих скомпенсировать потери производительности на эмуляцию этих сложных инструкций. Изначально предполагалось, что MIPS-процессоры не будут аппаратно поддерживать даже операции умножения и деления - благодаря чему можно было обойтись без сложных в реализации блокировок конвейера[Процедура приостановки конвейера, инициируемая, когда процессору встречается «медленно выполняющаяся» операция, которую невозможно выполнить на какой-то из стадий за один такт. В процессорах тех времен такими операциями являлись умножение и деление; в современных процессорах блокировку может вызвать неудачное обращение в оперативную память, не находящуюся в кэше CPU] (отсюда и название архитектуры). Тем не менее даже в самых первых MIPS’ах блокировки в конвейере, равно как и аппаратные инструкции умножения и деления все-таки присутствовали - «в чистом виде» идея оказалась малопригодной для создания коммерческих процессоров. В 1984 году Хеннеси с командой покинул Стэндфордский университет и основал компанию MIPS Computer Systems. В 1985 она выпустила первый 32-разрядный MIPS-процессор R2000; в 1988 году - гораздо более быстрый, работающий с виртуальной памятью и поддерживающий многопроцессорность R3000. R3000 стал первым по-настоящему коммерчески успешным MIPS-процессором и использовался в рабочих станциях Silicon Graphics. Кстати, вариант MIPS R3000A хорошо известен в народе как центральный процессор приставки Sony PlayStation В 1991 году вышел первый 64-разрядный MIPS R4000, легший в основу целого ряда различных процессоров, выпускавшихся по лицензиям другими фирмами. R4000 оказался настолько важен для SGI, что она не колеблясь приобрела испытывавшую тогда финансовые затруднения MIPS Computer Systems и превратила эту компанию в собственное подразделение MIPS Technologies. Тогда же SGI начала продавать лицензии на производство MIPS-процессоров сторонним фирмам, которые взялись разрабатывать свои, улучшенные варианты R4000. Помимо всего прочего, начиная с R4600 и R4700 (разработка Quantum Effects Devices) MIPS-процессоры стали основой для знаменитых маршрутизаторов Cisco, являющихся сегодня неотъемлемой частью большинства крупных сетей, включая Интернет. Использовались 64-разрядные MIPS-процессоры и в приставках: R4300 - в Nintendo 64, R5900 - в PlayStation 2. В 1994 году вышел R8000 - первый суперскалярный MIPS-процессор; в 1995-м - R10000, улучшенный во всех отношениях вариант R8000, поддерживавший внеочередное исполнение команд в конвейере. Работая на частоте 200 МГц, R10000 был одним из самых быстрых CPU того времени. Пожалуй, на те времена пришелся расцвет архитектуры MIPS - она была столь успешной, что в 1998 году SGI снова сделала из MIPS Technologies отдельную компанию. Правда, «в стиле Тараса Бульбы» («я тебя породил, я тебя и убью»), - SGI сочла дальнейшее развитие MIPS как своей флагманской разработки бесперспективным и решила, когда настанет срок, перевести линейку Silicon Graphics на процессоры архитектуры IA-64 (Intel Itanium). В итоге дизайн всех последующих MIPS-процессоров основывался на R10000. Изменялись только объем кэш-памяти и постепенно наращивалась тактовая частота. Фактически после прорыва R10000 архитектура MIPS была заброшена[После очередного сообщения о задержке выпуска Itanium, выходила очередная версия MIPS R1xxxx. Причем этих задержек было столько, что MIPS Technologies помаленьку добралась и до R16000A с тактовой частотой 800 МГц], и мало-помалу эти процессоры утратили лидирующее положение в индустрии. В 2001 году топовым CPU от MIPS Technologies был R14000 с тем же старым ядром R10000 и тактовой частотой всего 600 МГц. Конкуренты в лице, к примеру, более совершенных в технологическом плане AMD Athlon уже достигли частот 1,3-1,4 ГГц, были в несколько раз производительнее, а стоили куда меньше. Так что как «тяжелая высокопроизводительная RISC-архитектура» MIPS к началу нового тысячелетия умерла. Но компания MIPS Technologies процветает до сих пор - за счет лицензирования архитектуры сторонним разработчикам. Еще в 1999 году MIPS Technologies упростила свою лицензионную политику, предложив всем желающим два варианта MIPS-архитектуры: MIPS32 - для 32-разрядных систем и MIPS64 - для 64-разрядных. С тех пор эту технологию лицензировали NEC, Toshiba, Broadcom, Philips, LSI Logic и IDT, выпустившие огромное количество специализированных интегрированных процессоров на ее основе. Сегодня MIPS - самая популярная высокопроизводительная[То есть там, где производительность критична, используется MIPS, а где нет - ARM] архитектура, использующаяся во встраиваемых системах. А это львиная доля сетевых устройств (от роутеров Cisco Systems до небольших мостов домашних и офисных сетей); большая часть процессоров игровых приставок прошлых поколений; процессоры для WiFi и VoIP; кодеры-декодеры MPEG; некоторая часть процессоров терминалов, КПК и сотовых телефонов. Не очень завидная участь для бывшего лидера, но если сравнивать с судьбой SPARC или Alpha - не такая уж и плохая. Шаг 4. Суперскалярные и Out-of-Order-процессоры У полноценной конвейеризации, более или менее эффективно обходящей перечисленные выше проблемы, есть одно несомненное достоинство: она настолько сложна, что, единожды реализованная, позволяет легко построить на ее основе целый ряд интересных новшеств. Для начала заметим, что коль уж у нас есть очереди готовых к исполнению инструкций и мы знаем взаимозависимости между ними по данным, есть техника переименования регистров, позволяющая разным инструкциям одновременно задействовать одни и те же регистры для разных целей, и, наконец, есть надежно работающая система сброса конвейера, то мы можем: Запускать на исполняющие устройства сразу несколько инструкций (если они не зависят друг от друга и могут быть безболезненно выполнены одновременно). Переупорядочивать независящие друг от друга инструкции так, как сочтем нужным. Процессоры, использующие первую технику, называются суперскалярными. К примеру, сугубо теоретически, по числу исполнительных устройств, Pentium 4 может выполнять семь инструкций за такт, а Athlon 64 - девять. Реальные цифры, конечно, гораздо скромнее и определяются трудностью полноценной загрузки всех исполнительных устройств, однако Pentium 4 все же способен исполнять в устоявшемся режиме две (при некоторых условиях - четыре), а Athlon 64 - три инструкции за такт, одновременно производя две (A64 - три) операции по адресации и выборке данных из оперативной памяти. Может показаться, что реализация суперскалярного процессора очень проста (достаточно со стадии schedule просто распределять инструкции по разным исполнительным устройствам), однако такой лобовой подход обычно упирается в то, что Front-end процессора перестает успевать загружать исполнительные блоки работой. Поэтому на практике хорошо сделанные суперскалярные архитектуры, подобные AMD K7/K8, приходится специально «затачивать» под суперскалярность. Процессоры, использующие вторую технику, называются процессорами с внеочередным исполнением инструкций (Out-of-Order processors, OoO). Техника переупорядочивания инструкций замечательна тем, что резко ослабляет негативные эффекты от медленной оперативной памяти и от наличия зависимых цепочек инструкций. Если, например, инструкция A обратилась к оперативной памяти, а нужных данных в кэше не оказалось или если A занимается ожиданием результатов выполнения какой-то другой инструкции, то OoO-процессор сможет пропустить вперед другие инструкции, не зависящие от результатов выполнения инструкции A. Кроме того, продвинутый планировщик OoO-процессора иногда может использоваться для реализации специфических деталей той или иной архитектуры - например, для спекулятивного исполнения по данным в случае Pentium 4 или одновременного исполнения нескольких веток программного кода в IA-64. Реализация OoO-процессоров не требует специальной оптимизации всего конвейера - это всего лишь усложнение схемы планировщиков, запускающих готовые к исполнению инструкции на исполнительные устройства в другом порядке, нежели они на планировщики поступили, плюс усложнение схем сброса конвейера и сохранения полученных результатов: результат выполнения прошедших вне очереди инструкций все равно должен сохраняться в последовательности, строго соответствующей расположению инструкций в изначальном коде[Это связано с тем, что если случится какая-то ошибка, то результаты выполнения запущенных вперед очереди инструкции придется аннулировать]. На сегодняшний день не существует ни одного суперскалярного или OoO CISC-процессора. Дело в том, что поскольку для нормальной реализации навороченных диспетчеров и планировщиков все равно требуется длительная и тщательная подготовка инструкций, причем желательно - до такого простого состояния, чтобы эти функционирующие на огромных частотах модули особенно не «задумывались» над тем, что такая хитрая последовательность байтов означает и куда ее следует направить (проблем у них и без того хватает), то любой исходный машинный код Front-end процессоров превращает перед исполнением в некое внутреннее, упрощенное и «разжеванное», состояние. То есть на этом этапе развития различия между RISC- и CISC-архитектурами почти стираются - просто у RISC’ов декодер, превращающий исходный машинный код в содержимое очередей планировщиков, устроен гораздо проще, чем «расковыривающий» хитро упакованные x86-инструкции CISC-подобный декодер AMD Athlon и Intel Pentium. Так что можно сказать, что фактически все современные x86-процессоры «в глубине души» являются полноценными RISC’ами - ведь исходный x86-код они в любом случае преобразуют на лету во внутреннее RISC-подобное представление. Правда, разной сложностью декодеров дело не ограничивается: все-таки классический RISC-код не только проще преобразовывать, но и результирующий внутренний код из него получается лучше - планировщикам гораздо легче его обрабатывать (в нем меньше зависимостей и операций с оперативной памятью). Вот и появляются в x86 все новые и новые расширенные наборы инструкций (от 3Dnow! до SSE): это всего-навсего «внешняя ширма», упрощающая работу декодерам инструкций и позволяющая им сгенерировать более эффективный внутренний код. Специального блока обработки того же упакованного 128-битного формата SSE нет ни в одном современном процессоре, так что когда в программном коде x86 встречается, скажем, инструкция сложения двух регистров SSE по четыре числа в каждом - декодер банально генерирует код из четырех явно независимых (вот за что боролись!) инструкций сложения, которые планировщику потом будет легко разбросать по исполнительным устройствам. Но какого-либо «специального блока SSE», одновременно выполняющего запрошенные одной инструкцией четыре сложения, ни в Athlon, ни в Pentium 4 нет. Фактически развитие собственно «архитектуры» x86-процессоров долгое время стояло на месте: что древний Pentium Pro, что новейший Pentium M - все они основаны на одной и той же старой-престарой архитектуре P6. Вылизанной, оптимизированной, но старой - ибо повода для ее смены до сих пор просто не было; «внутреннее представление» x86-кода, несмотря на все внесенные в x86 новации, с тех самых древних времен «чистой IA-32» вплоть до появления технологии AMD64 практически не изменялось. К сожалению, нет места для рассказа об архитектурах VLIW и Cell - потенциальных претендентов на замену суперскалярных OoO-процессоров, так что о них мы поговорим в следующий раз. А пока рассмотрим самые популярные примеры «классических» подходов - в их видении Intel и AMD. Блок предсказания переходов Да-да, именно так называется этот странный блок! Но «гадание на кофейной гуще» здесь ни при чем - переходы предсказываются на основе вполне научных соображений. Обычно используется очень простой способ: в процессоре ведется табличка ранее совершенных переходов - для каждого условного перехода подсчитывается, сколько раз он «сработал», а сколько - «был проигнорирован». Поэтому, скажем, когда процессор встречает переход, замыкающий какой-нибудь цикл, то он быстренько начинает считать: раз переход сработал, два сработал, три сработал - ну, значит, наверное, он всегда будет срабатывать, вот так и будем предсказывать, что переход всегда происходит. То, что мы один раз в конце цикла ошибемся, - не беда, зато ценой максимум двух ошибок мы добьемся точного предсказания во всех остальных случаях. Кстати, на простых циклах процессор, как правило, ошибается еще реже - не более одного раза: по умолчанию, когда не из чего выбирать, считается, что условный переход всегда происходит. При неправильном предсказании конвейер обычно приходится «сбрасывать», каким-то образом восстанавливая состояние процессора, предшествующее моменту неправильного перехода. А ведь пока исполнялась неправильная ветка, там ого-го сколько всего могло случиться! Неправильный опкод (нераспознаваемая машинная инструкция), обращение к виртуальной памяти (провоцирующее исключение в процессоре), некстати распознанное деление на ноль (тоже ошибка). Все это приходится тщательно отслеживать и проверять, причем это не шутки: одно время из-за ошибки в реализации конвейера процессора AMD K5, программист, написавший конструкцию если x A 0, то y = 1/x, иначе y = 0, запросто мог получить при x @ 0 на, казалось бы, ровном месте ошибку «деление на ноль», вызванную неправильным предсказанием перехода. А в OoO-процессорах ситуация еще сложнее - пока «тормозит» не вовремя отправившаяся за операндами в оперативную память инструкция, процессор успевает пропустить вперед, выполнить и едва ли не сохранить результат вычисления десятков инструкций неправильной ветки: попробуй за всем этим уследить! Но бороться здесь есть за что: для современных процессоров каждая ошибка предсказания - это десятки вхолостую израсходованных тактов. Сущая катастрофа, если учитывать, что за каждый такт можно было бы исполнить до трех x86-инструкций и совершить кучу вычислений. Если бы блока предсказания не было, то так «тормозил» бы каждый условный переход. Точность предсказания современных блоков составляет на тестах SPEC порядка 98-99%. Может показаться, что совершенствовать блок не имеет смысла, но это не совсем так. Дело в том, что на производительности гораздо больше сказывается процент ошибок, а не верных предсказаний. А переход от 98-процентной точности к 99-процентной означает двукратное снижение ошибок - с 2% до 1%! Поэтому если вы внимательно почитаете пресс-релизы о новых CPU, то заметите, что «усовершенствованный блок предсказания переходов» упоминается в них почти всегда. В архитектуре IA-64 техника предсказания переходов сделала значительный шаг вперед - эти процессоры умеют одновременно вычислять несколько веток программного кода. То есть, встретив инструкцию условного перехода, процессор начинает «охотиться за двумя зайцами» - просчитывать оба варианта развития событий вплоть до того момента, пока не станет ясно, какой из них правильный. Поскольку инструкции «разных вариантов» практически не зависят друг от друга, а исполнительные устройства Itanium обычно загружены далеко не полностью, то исполнять побочную ветку нередко удается практически с той же скоростью, что и основную, так что даже при неправильном предсказании условного перехода происходит не остановка процессора на пару десятков тактов, а всего лишь снижение производительности на небольшом участке кода. Архитектура PowerPC Последняя из ныне здравствующих процессорных RISC-архитектур - это, конечно же, знаменитая PowerPC, детище альянса Apple, IBM и Motorola (AIM). Сегодня на PowerPC есть четкие спецификации, следуя которым любой желающий может разработать совместимый с ним процессор. Ничего особо интересного в нем нет - это самый что ни на есть классический RISC-процессор без специальных «примочек». Существуют 32- и 64-разрядные версии PowerPC (причем 64-разрядные совместимы с 32-разрядным кодом), а равно и ряд стандартизованных расширений (типа эппловского набора инструкций AltiVec). В то время как MIPS и ARM «специализировались» на тех или иных применениях, PowerPC, подобно x86, позиционировалась в основном для обычных персоналок и серверов. Вплоть до 2001 года x86 и PowerPC развивались более или менее синхронно, однако из-за технологических проблем и неспособности угнаться за процессорами AMD и Intel в «гонке мегагерц» PPC шаг за шагом сдавала позиции. А исчерпав «запас прочности» и застряв на частотах 1,0-1,4 ГГц, она стала стремительно проигрывать архитектуре x86, по-прежнему сохранявшей высокие темпы развития из-за ожесточенной схватки Intel и AMD. Поскольку «отступать» PowerPC было в общем-то некуда (нишу интегрированных процессоров оккупировали ARM и MIPS), то многие посчитали ее верным кандидатом на вымирание. Даже Apple недавно «отреклась» от своей архитектуры, переметнувшись в стан приверженцев x86. Только крайне дорогие серверные процессоры POWER, выпускавшиеся на пределе технологических возможностей Голубого гиганта (Power4, в частности, стали первыми в мире двухъядерниками), еще довольно уверенно чувствуют себя в линейке продуктов IBM. Однако ситуация, похоже, начала меняться: именно архитектура PowerPC положена в основу будущих многоядерных процессоров всех игровых приставок шестого поколения (от Sony, Microsoft и Nintendo), поскольку ни MIPS, ни тем более ARM на эту роль не годятся; процессоры Intel в их текущем варианте плохо подходят для создания игровых приставок нового поколения; о процессорах AMD и говорить не приходится - компания просто не в состоянии обеспечить достаточный объем их производства. Вот и остается единственным кандидатом на роль нового «суперпроцессора» только всем доступная, технологически более простая, нежели x86, и достаточно производительная архитектура PowerPC. Что еще важнее для PPC, именно она положена в качестве аппаратной основы концепции Cell, которая, возможно, станет следующим шагом в развитии компьютинга. Так что пожелаем РРС удачи - от наличия на рынке множества альтернатив пользователи только выигрывают, и видеть в обозримом будущем абсолютную монополию x86, даже в варианте AMD64, лично мне не хотелось бы. Устройство процессоров AMD архитектуры K8 Архитектура K8 используется во всех современных серверных, десктопных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера[Время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память] варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до трех; тактовые частоты серийно выпускаемых процессоров - от 1,6 до 2,8 ГГц. Об особенностях организации архитектуры K8, связанных с интегрированным контроллером памяти, линками HyperTransport и неоднородной моделью памяти SUMa мы подробно писали в статье про двухъядерные процессоры; в остальном же - перед нами вполне классический процессор Гарвардской архитектуры. Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) - фиксирован и составляет по 64 Кбайт; имеется общий эксклюзивный[Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш - когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти нижележащих] кэш второго уровня объемом от 128 до 1024 Кбайт; кэш третьего и более низких уровней не предусмотрен, но в рамках протокола MOESI процессоры в многопроцессорных системах могут обращаться к кэш-памяти других процессоров. *** 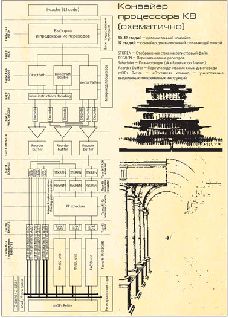 Исполнение инструкций на конвейере K8, как и положено, начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 - сколько в выбранных данных поместилось[Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт]. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы - в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86. Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I-cache; при вытеснении данных из L1 в L2 теги сохраняются. На втором такте работы конвейера свежевыбранные одна-три инструкции x86 распределяются по трем блокам декодирования инструкций. Самые сложные инструкции, требующие декодирования с использованием микрокода процессора, отправляются в декодер VectorPath. Более простые - в декодеры DirectPath: те, что попроще, - в обычный, те, что посложнее, - в сдвоенный DirectPath Double. Начиная с этого момента процессор «забывает» о существовании x86 и переключается на работу с внутренними микроинструкциями (mOP). Весь дальнейший конвейер строится на том, что работа с mOP’ами происходит тройками инструкций (AMD называет их линиями, line). С логической точки зрения конвейер K8 строится таким образом, что обрабатывает именно линии, а не x86-инструкции или отдельные микрооперации. При этом в одной линии может быть меньше трех микроопераций - тогда «недосдачу» в тройке заполняют специальные пустые операции (null-mOP). При этом со «сложными» vector-инструкциями все элементарно - VectorPath-декодер подставляет на их место прошитые в микрокоде процессора линии; а вот декодирование «простых» инструкций выливается в сложный процесс превращения x86-инструкции в один (DirectPath) или два (DirectPath Double) mOP’а, которые потом перетасовываются и упаковываются в одну линию специальным упаковщиком[В этом упаковщике, который, в частности, научился эффективно управляться с разбивающимися на два mOP’а инструкциями SSE, и скрыто важнейшее усовершенствование конвейера K8 по сравнению с конвейером K7 (процессоры Athlon/Athlon XP). Изменение декодера (и значительное увеличение времени на декодирование), усовершенствование планировщика инструкций - казалось бы, мелочи, но эффект огромный. Кстати, отсюда следует, что конвейер K8 практически не оптимизировался для достижения высоких тактовых частот - неудивительно, что на старом 130-нм технологическом процессе он и не показал существенно более высоких тактовых частот, нежели старичок K7]. На весь процесс в нормальных условиях уходит пять тактов конвейера. Сгенерированные линии от VectorPath- и DirectPath-декодеров по одной за такт поступают в специальное устройство - Instructions Control Unit (ICU), где подготовленные к исполнению линии накапливаются в специальной очереди (24 линии). О том, что происходит дальше, поясним с помощью аналогии. Предположим, что наша программа - это книжка, в которой записано, как процессору нужно обрабатывать данные. Что делает процессор? Упоминавшийся блок выборки вырывает из книжки страничку с текстом (будем считать, что странички достаточно маленькие) и выбирает из нее от одной до трех содержательных частей, которые передает декодеру. Декодер читает выделенные фрагменты текста и конвертирует их в четкие инструкции, указывающие, что и в какой последовательности нужно сделать. Инструкции (по одной) он записывает на бумажках (mOP’ах) и упаковывает в конверты - до трех бумажек в один конверт (линию). Конверты поступают в специальную картотеку - ICU, где их вскрывает и прочитывает специальный человек. Что дальше? Претендентов на декодированные инструкции два - блок целочисленных вычислений (ALU) и блок вычислений с плавающей точкой (FPU). Когда блоки готовы принять очередную инструкцию, они сообщают об этом человеку в картотеке; человек копается в своих конвертах и выбирает из них в произвольном порядке, как ему удобнее, до трех бумажек-инструкций, которые и раздает ALU и FPU. Единственное ограничение, которое при этом накладывается, - человек никогда не передает ALU и FPU те инструкции, выполнение которых зависит от еще не переданных. Блоки ALU/FPU каким-то хитрым образом выполняют полученные инструкции, но результаты отсылают не во «внешний мир», а в нашу картотеку-ICU, где их кладут в тот же самый конверт, в котором лежали инструкции. Даже если происходит ошибка выполнения, процессор не сообщает о ней сразу, а сперва записывает информацию об ошибке на конверте; когда настанет пора вскрыть конверт - вот тогда он про нее и сообщит. Чтобы потом эти данные использовать - применяется довольно хитрая техника (та самая, из сноски 4), позволяющая вновь выполняемым инструкциям обращаться к еще «официально несуществующим» данным. Когда для конверта все инструкции оказываются выполненными, а конверт стоит первым в очереди и больше не содержит инструкций, но лишь результаты их исполнения - то полученные результаты «объявляются официальными», а конверт выбрасывается (отставка линий). Иногда, если при вскрытии очередного конверта выясняется, что ранее была допущена ошибка при предсказании условного перехода или при выполнении содержащейся в конверте инструкции, дело до этого и не доходит - конвейер приходится «сбрасывать», то есть смотреть на последнем конверте адрес того самого неудачного перехода, выкидывать всю накопленную к текущему моменту картотеку со всеми ее результатами и начинать выполнение с того самого места, где произошло неверное предсказание перехода. Благодаря тому, что результаты выброшенных конвертов еще не были «объявлены официальными», а «рвем» мы конверты строго в той же очередности, в которой они к нам в очередь поступали - допущенная ошибка «никому не станет известна» - результаты выполнившихся «вперед батьки» инструкций автоматически будут аннулированы. Если теперь вернуться к технологическому описанию конвейера, то изложенный выше процесс с конвертами происходит следующим образом. Из очереди в 24 линии по три mOP’а в каждой ICU выбирает в наиболее удобной для исполнения последовательности один-три mOP’а и пересылает их либо на ALU, либо на FPU - в зависимости от типа микрооперации. В случае ALU микрооперации сразу же попадают в очередь планировщика (шесть элементов по три mOP’а), который подготавливает необходимые для исполнения микрооперации ресурсы, дожидается их готовности и только потом отправляет mOP вместе со всеми необходимыми данными на исполнение. Причем при исполнении одного mOP’а на самом деле может происходить исполнение сразу двух действий - несложных арифметических вычислений, которые часто возникают при обращении к оперативной памяти (ими занимается блок Address Generation Unit, AGU), и «сложных», требующих вмешательства «полновесного» ALU, - соответствующая «двойка» микроинструкций (ROP) закладывается в mOP еще на стадии декодирования. Подготовка данных в планировщике занимает (в идеальном случае) один такт, исполнение - от одного (подавляющее большинство инструкций) до трех (при обращении к оперативной памяти) и даже пяти (64-битное умножение) тактов. С блоком FPU все чуточку сложнее. Для начала вышедшие из ICU mOP’ы проходят две стадии по подготовке их операндов. Затем - накапливаются в планировщике FPU (двенадцать элементов по три mOP’а), который, по аналогии со своим целочисленным собратом, дожидается, пока данные для этих mOP’ов будут готовы, а исполнительные устройства освободятся, и разбрасывает накопленные mOP’ы по трем исполнительным устройствам. Но в отличие от целочисленной части конвейера (где содержатся по три одинаковых блока ALU и AGU), исполнительные устройства FPU «специализированы» - каждое производит только свой специфический набор действий над числами с плавающей запятой. Время выполнения: два такта на переименование и отображение регистров, один такт (в идеале) на планирование и ожидание операндов, четыре такта на собственно исполнение. Финал же у всех закончившихся микроопераций один - они «возвращаются» в ICU с полученными результатами, и ICU, по мере готовности линий, потихоньку производит их отставку. На все про все в идеальных условиях у нас ушло 10-17 тактов, причем за каждый такт мы исполняли по три mOP’а (это обычно 1,5-3 инструкции x86). Устройство процессоров Intel архитектуры NetBurst Архитектура NetBurst сегодня лежит в основе всех процессоров Pentium 4, Xeon и Celeron. Эффективная длина конвейера в зависимости от варианта составляет 20 или 31 стадию. Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до четырех; тактовые частоты серийно выпускаемых процессоров - от 2,53 до 3,8 ГГц - это по всем показателям лучше данных по K8. Лучше, но, к сожалению, только сугубо теоретически и на специально подготовленном коде. ***  NetBurst тщательно оптимизировалась для работы на высоких частотах, и назвать эту архитектуру классической можно только с большой натяжкой. Для начала упомянем хотя бы тот же Trace Cache (TC), заменяющий в NetBurst классический Гарвардский I-cache (L1 code). Идея состоит в том, что в NetBurst декодер вынесен за пределы собственно конвейера - процессор конвертирует x86-инструкции в свое внутреннее представление не на лету, как AMD K8, а заблаговременно, еще на стадии копирования кода в кэш-память первого уровня. Устроено это все так своеобразно (например, в процессе декодирования декодер убирает безусловные переходы, занимается предсказанием условных переходов и может едва ли не «разворачивать» циклы!), что внутреннему устройству Trace Cache и декодеру инструкций для него вообще можно посвятить отдельную статью (чего мы делать сейчас не будем; скажем только, что декодер для TC работает очень медленно). Точная длина соответствующего участка конвейера неизвестна, но составляет, по разным оценкам, от 10-15 до 30 тактов - то есть этот «скрытый» участок конвейера имеет длину едва ли не большую, чем «видимый». Таким образом, введение TC позволяет практически вдвое уменьшить эффективную длину конвейера (страшно даже представить NetBurst без Trace Cache)[С K8, кстати, та же самая история - декодированием и подготовкой инструкций занята примерно половина конвейера. Есть предположения, что в следующем поколении процессоров AMD - архитектуре K9 - появится и Trace Cache. Скажем, в K8 подобное нововведение уменьшило бы видимую длину конвейера до 6-7 стадий в целочисленных вычислениях и до 12 стадий в вычислениях с плавающей точкой!]! Емкость TC для всех NetBurst составляет 12 тысяч микроопераций; в терминах классического x86 это соответствует примерно 8-16 Кбайт кэша L1-data; причем работает TC и обслуживающая его логика на половинной частоте ядра и наполняется декодером с темпом не более одной новой инструкции за такт. Поэтому если процессор некстати вылетит на незакэшированный участок кода (а кэш маленький, и подобная ситуация вполне возможна), то от теоретически возможных четырех инструкций за такт в лучшем случае останется лишь одна. Подобные «резкие потери темпа» вообще свойственны архитектуре NetBurst; к счастью, такие ситуации возникают редко. Дальнейшее повествование я буду вести, указывая время исполнения инструкции для ядра Northwood (20-стадийный конвейер). Для более нового Prescott в целом справедливо все то же самое, просто время исполнения отдельных стадий слегка возросло. Первые четыре такта работы конвейера - извлечение специальным блоком выборки инструкций из TC и второй этап предсказания условных переходов. В первый раз декодер TC уже пытался предсказать переход, так что второй этап предсказания фактически сводится к «угадыванию» того, правильно ли декодер угадал переход еще «в тот раз» или нет. Заодно для некоторых записей TC («закладок»["Закладки" позволяют увеличить эффективный объем Trace Cache, поскольку вместо нескольких mОР’ов мы храним в нем одну «закладку»]) происходит их «развертывание» в несколько микроопераций. В силу того что TC работает на половинной частоте ядра, происходит выборка довольно медленно и каждый ее этап занимает по два такта конвейера. Затем полученные микрооперации (до шести штук за такт) складываются в традиционную очередь выборки (Fetch Queue), где буферизуются, сглаживая неравномерность декодирования и обеспечивая «на выходе» устоявшийся темп декодирования в три микроинструкции за такт. Задержка, вносимая буферизацией, - 1 такт; еще 1 такт расходуется на то, чтобы подготовить внутренние ресурсы процессора для выбранной из Fetch Queue тройки mOP’ов. Затем еще два такта уходит на то, чтобы подготовить для каждого mOP’а персональные физические регистры для вычислений (в рамках техники переименования регистров). И, наконец, на последнем, девятом по счету такте полностью готовые к исполнению mOP’ы начинают «распихиваться» по очередям инструкций, стоящих на выполнение. Зачем понадобилась вся эта каша с многократными очередями? Разработчики NetBurst пытались добиться того, чтобы все стадии конвейера были независимы друг от друга и работали асинхронно, без точной привязки к некой «единой тактовой частоте» процессора. Именно асинхронность (а не только длинный конвейер!) позволяет резко повысить тактовые частоты, на которых способно работать ядро процессора. Вернемся к конвейеру NetBurst. Итак, подготовленные к исполнению инструкции на девятом такте распределяются по двум очередям - очереди для AGU-инструкций, обращающихся к оперативной памяти (длина - 16 mOР’ов), и очереди для всего остального (32 mOP’а). На следующем такте инструкции из этих очередей разбираются аж пятью независимо работающими планировщиками - планировщиком AGU, двумя «быстрыми» и двумя «медленным» планировщиками. «Быстрые» имеют дело лишь с некоторыми самыми простыми арифметико-логическими операциями и работают на удвоенной тактовой частоте процессора, успевая забирать из очередей по две простые инструкции за такт. Нужны они для того, чтобы загружать работой «быстрые» же исполнительные блоки, построенные на специальной быстродействующей логике и тоже работающие на удвоенной тактовой частоте (до 8 ГГц!), обрабатывая по две инструкции за такт. «Медленные» планировщики «специализируются» каждый на своем типе инструкций и работают на номинальной частоте ядра. Планировщики могут переупорядочивать микрооперации по своему усмотрению (OoO-исполнение); они же отслеживают ход выполнения микроопераций, при необходимости перезапускают их и в конце выполнения инструкции записывает полученные результаты в оперативную память; на все про все у них уходит еще три такта процессора. Наконец, планировщики через четыре порта запуска (порты частично общие, а это значит, что «быстрые» и «медленные» планировщики конкурируют друг с другом за то, кто из них получит право запускать в текущем такте подготовленные mOP’ы дальше) переправляют упорядоченные микрооперации в очереди диспетчеров, где они дожидаются «разрешения на запуск». И тут начинается самое интересное. Задача диспетчера - подготовить для микрооперации операнды таким образом, чтобы, когда команда прибыла на исполнительное устройство, необходимые для вычисления данные оказались там же. Но конвейер NetBurst устроен так, что диспетчер и собственно исполнительное устройство довольно сильно разнесены по конвейеру, и чтобы данные и микрооперация пришли одновременно, микрооперацию на исполнение требуется запускать задолго до того, как будет получено подтверждение готовности ее операндов. Если быть точным, то после запуска инструкции диспетчером два такта уйдет на подготовку данных, три такта - на исполнение команды и еще один такт - на проверку результатов[В NetBurst, как и в других архитектурах, используется быстрая выборка данных из кэша, когда, грубо говоря, «вначале вытаскиваем данные, а потом уж смотрим, что мы такое вытащили». Выборка происходит при совпадении лишь небольшой части запрошенного и найденного адресов, а проверка на то, что остальная часть адреса тоже совпадает, - производится параллельно с выборкой «вроде как найденных» данных и исполнением операции над ними], после чего инструкции уже можно будет отправлять «в отставку». Стало быть, нужно отправлять инструкцию за пару тактов до того, как данные понадобятся; причем ошиблись мы или нет, станет известно еще позже - тактов эдак через пять-семь, когда диспетчер успеет выпустить соответствующее количество инструкций, часть из которых уже будет выполнена (!). А если мы ошиблись, что тогда делать? Авторы NetBurst предложили весьма своеобразное решение - «реплей». Снова попробую объяснить ситуацию «на пальцах». Представьте, что конвейер - это рельсовый путь, а по нему бегают вагончики - микрооперации, указывающие, что процессору нужно изготовить и в вагончики погрузить. Причем путей в нашем процессоре несколько, и инструкции разных видов - катятся по разным рельсам. Задача диспетчера, - организовать оптимальным образом движение по своей железнодорожной ветке. Что он делает? Время вагончика в пути от его станции до станции, где вагончик загрузят полезным грузом, ему известно; так что нашему диспетчеру (а всего их семь) остается только связаться с другими диспетчерами и запросить у них информацию о том, когда будут готовы те данные, которые «его» микрооперации используют в качестве исходных, и отправить вагончик с таким расчетом, чтобы он и данные, полученные на другой ветке от другой микрооперации, прибыли на исполнительное устройство одновременно. Загвоздка в том, что некоторые вагончики имеют обыкновение опаздывать или привозить совсем не то, что запрашивалось, постфактум сообщая о накладке. Соответствующая подобным микрооперациям неспокойная ветка в процессоре отведена для вагончиков, обращающихся к оперативной памяти; причем часто результат выполнения этих микроопераций выступает как исходные данные для другого mОР’а. Поэтому в архитектуре NetBurst порой возникает ситуация, когда микрооперация на исполняющее устройство прибыла, а исходные данные для ее исполнения - нет, Что происходит тогда? Очень простая штука: наш вагончик тут же «переводят на запасной путь», путешествуя по которому, он описывает круг специально рассчитанного размера и возвращается к диспетчеру как раз в тот момент, когда его нужно было бы запускать повторно. Диспетчер приостанавливает отправку на линию новых вагончиков и пропускает вперед прибывший «новый-старый» вагончик. Если к моменту повторного прибытия на исполняющие устройства данных там так и не окажется, микрооперация снова отправится на запасной путь и будет нарезать круги до тех пор, пока нужные данные не появятся. При этом по основному пути могут исполняться другие инструкции, независимые от первой. Получается простое и вроде бы эффективное решение. Хотя стоп! Эффективное ли? Занимавшаяся изучением реплея группа экспертов[Replay: неизвестные особенности функционирования ядра NetBurst.] убедительно показала, что подобная незамысловатая техника приводит к нетривиальным и крайне интересным эффектам вроде «затягивания» в петли реплея целых цепочек данных (вплоть до полного зацикливания - deadlock’а!) и перегрузки исполнительных устройств из-за необходимости многократно исполнять некоторые инструкции. В итоге процессор архитектуры NetBurst «тормозит» даже при отсутствии ошибок предсказания - просто в силу того, что несвоевременно запущенные цепочки инструкций приходится переисполнять целиком, вместо того чтобы переисполнить одну-единственную «неудачную» инструкцию. Вдобавок, поскольку исполнительные устройства греются больше всех остальных узлов процессора, то непрерывная прогонка через них потока инструкций, данные для которого не подготовлены, приводит еще и к тому, что процессор не просто «тормозит», а вовсю греется. Не очень приятные эффекты, но это та цена, которую уплатила Intel за разработку процессора, умеющего работать на очень высоких тактовых частотах. И если учесть успех процессоров на ядре Northwood - цена вполне оправданная. К сожалению, непомерное тепловыделение NetBurst-процессоров начиная с некоторого момента замедлило, а потом и вовсе остановило рост тактовой частоты, так что сегодня минусы скорее перевешивают плюсы этой, несомненно, опередившей свое время архитектуры. Просуммируем все сказанное. Теоретически процессор архитектуры NetBurst способен обрабатывать четыре инструкции за такт (два «быстрых» ALU, работающих на удвоенной частоте). При тактовой частоте от 2,53 до 3,8 ГГц столь высокий показатель должен был бы вывести NetBurst-процессоры в лидеры по производительности, если бы не недостаточно быстрый Front-end, неспособный обеспечить больше трех микроопераций за такт; если бы не крайне ограниченный набор «быстрых» инструкций, в которых вплоть до ядра Prescott не входила, например, широко используемая простая операция битового сдвига[Кстати, даже в Prescott битовый сдвиг поддерживает только одно Fast ALU из двух. Это и ряд других ограничений связаны с оригинальной организацией 32-битного Fast ALU в виде двух «сдвоенных» 16-битных ALU]; если бы не наличие всего лишь одного (!) блока ALU и одного блока FPU, умеющих работать со «всей остальной» арифметикой (причем целочисленное умножение вплоть до того же Prescott, тоже выполнялось в FPU!); если бы не многочисленные штрафные такты, возникающие, например, при обращении к «невыровненным» данным в оперативной памяти; если бы не система реплея… если бы не десятки разных «если», подрезающих этой архитектуре крылья. Мнения: предположительные характеристики процессоров будущего Информация о разработке преемника существующего решения AMD - ядра K9 - впервые появилась в 2003 году. На сегодняшний день почти доподлинно известно, что: - K9 будет традиционным x86-процессором, с набором инструкций AMD64, поддержкой виртуализации и технологии безопасности LaGrande. - K9 будет многоядерным CPU; вероятно, с общим для ядер L2-кэшем. - K9 будет работать с двухканальной оперативной памятью DDR-II. При этом возможно, что предназначенные для многопроцессорных систем K9 будут выпускаться в нескольких вариантах - с интегрированным контроллером памяти и без него: вариант без ИКП будет дешевле. Более того, возможен и обратный вариант: покупка относительно дешевого контроллера памяти без процессора. Скажем, можно будет установить в 4P-материнскую плату один процессор с ИКП и три дешевых модуля ИКП - получится поддержка очень большого объема оперативной памяти (например, 64 Гбайт) задешево. Естественно, что устанавливаться все эти «разновидности» и «контроллеры» будут в один и тот же стандартный сокет. - Число линков HyperTransport в K9 увеличат (вероятно, до пяти), что позволит легко создавать на основе K9 более чем восьмипроцессорные системы и повысит производительность четырех- и восьмипроцессорных серверов. - Количество исполняемых за такт инструкций - больше трех. - Удвоенное количество блоков FADD и FMUL позволит удвоить производительность при вычислениях в SSE2 с плавающей точкой. Интересные, но маловероятные слухи говорят также о том, что в K9 появится: - Одновременная поддержка до восьми спекулятивных ветвлений, позволяющая, как в процессоре Itanium, одновременно просчитывать несколько ветвей программного кода, избегая таким образом полного сброса конвейера при ошибке предсказания перехода. - Введение трех специальных блоков SSE в дополнение к трем существующим блокам ALU и трем блокам FPU. - Поддержка кэш-памяти третьего уровня (L3). - HyperTransport 2.0; улучшенный протокол когерентности кэшей (MOESI+). - Специальные буферы - суперкэши нулевого уровня, напрямую доступные исполнительным устройствам для сохранения промежуточных результатов и позволяющие сократить время на пересылку и сохранение данных при работе с плавающей точкой. - Возможность переброски mOP’ов в многоядерных процессорах с конвейера одного ядра на конвейер другого. То есть двухъядерный процессор будет работать быстрее даже в однопоточных (!) приложениях. - Сжатие на лету данных, хранящихся в кэш-памяти процессора, позволяющее увеличить эффективный объем кэша. - 15 стадий целочисленного конвейера, 20 стадий - для вычислений с плавающей точкой. - Trace Cache. - Возможен интегрированный в крышку процессора тепловой насос - элемент Пельтье, увеличивающий эффективность теплоотдачи от кристалла CPU. - Срок появления на рынке прототипов - второе полугодие 2006 года. С Intel ситуация интереснее. От развития преемника архитектуры NetBurst - процессорного ядра Tejas (в котором, по слухам, должен был появиться - страшно представить - аж 50-стадийный конвейер), корпорация после долгих размышлений отказалась. Последним процессором «Пентиум четвертой» архитектуры станет выпускающийся по 65-нм технологическому процессу процессор Presler (Pentium D)/CedarMill (Pentium 4), в котором Intel всего лишь исправит допущенные при проектировании ядра Prescott ошибки. Например, появится поддержка маленьких коэффициентов умножения. Напомню суть проблемы: ядро Prescott, которое должно было покорить рубеж едва ли не в 5 ГГц, не позволяет использовать коэффициенты умножения, меньшие 14. Ну вот не предполагали разработчики, что они понадобятся: для частот 3-5 ГГц самый актуальный диапазон множителей - от 15 до 25. Но когда стало понятно, что из-за чрезмерного тепловыделения новое ядро не сумеет покорить даже 4-гигагерцовый рубеж, то невозможность процессоров с 800-МГц системной шиной работать на частоте меньше 2,8 ГГц, а процессоров с 1067-МГц шиной - на частоте менее 3,73 ГГц превратилась в серьезную проблему, не позволяющую массово ввести быструю шину и реализовать эффективные технологии энергосбережения. Появится и поддержка технологий виртуализации. Но это все мелочи, такая же «доработка» архитектуры, которой являлся в свое время пришедший на смену революционному, но неудачному Wilamette неновый, но удачный Northwood. Интереснее, что станет следующим Большим Шагом в развитии архитектур Intel. Недавно обнародованные технические характеристики предполагаемого преемника NetBurst - процессоров Conroe, Merom и Woodcrest - таковы: - За основу взят Pentium M (архитектура P6). Сохранен механизм наслоения микроопераций (когда одна операция распадается на несколько микроопераций - как, например, в K8, где mOP может порождать два ROP’а, один из которых задействует ALU, а другой - AGU). - Новый широкий конвейер, напоминающий конвейер K8, но рассчитанный не на тройки, а на четверки инструкций. Длина конвейера - 14 стадий. - Поддержка технологии EM64T, технологий виртуализации VT-x и безопасности LaGrande. - Общий для многоядерных процессоров кэш второго уровня. - Улучшенная подсистема памяти с эффективными схемами предвыборки и разрешения конфликтов по адресам при одновременном чтении-записи в память. Больше пока ничего не известно: слишком уж мало времени прошло с момента анонса. Но судя по всему, получится нечто изрядно напоминающее сегодняшний Athlon 64, только без интегрированного контроллера памяти. Поживем - увидим: предполагаемый срок появления на рынке новых процессоров - второе полугодие 2006 года. |
|
||
| Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх | ||||
|
|
||||